Downloaded 623 times






























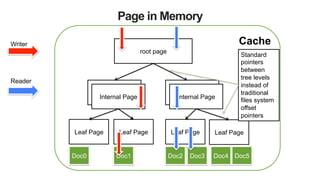



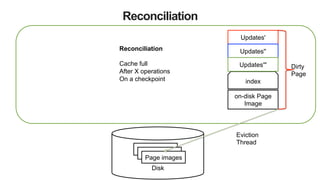




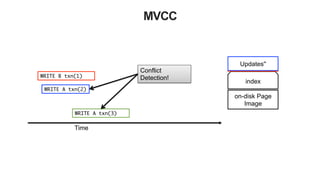

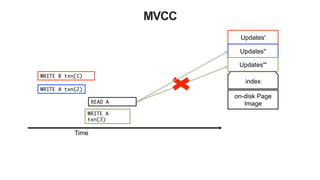




![51
Compression
• WiredTiger uses snappy compression by default in MongoDB
• Supported compression algorithms:
– snappy [default]: good compression, low overhead
– zlib: better compression, more CPU
– none
• Indexes also use prefix compression
– stays compressed in memory](https://image.slidesharecdn.com/wiredtiger-151209083622-lva1-app6892/85/MongoDB-WiredTiger-Internals-51-320.jpg)

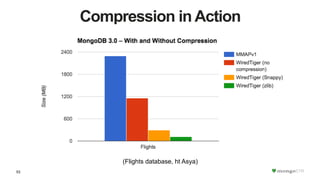


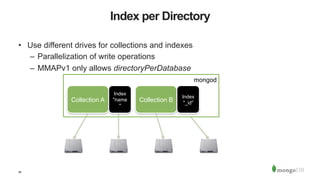











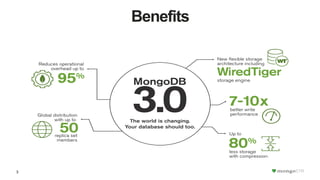
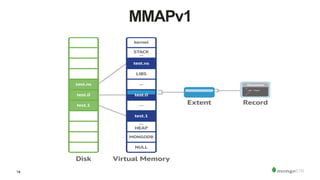
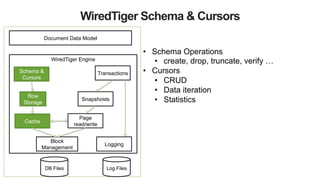
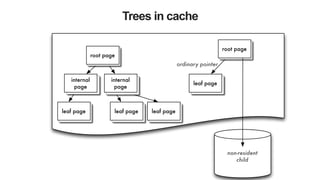
The document discusses the WiredTiger storage engine, introduced in MongoDB 3.0, highlighting its benefits such as improved performance, concurrency control, and support for multiple compression algorithms. It details the architecture, functions, and capabilities of WiredTiger, including how it optimizes data access and management for various workloads. The content emphasizes future enhancements and the transition of existing infrastructure to utilize WiredTiger effectively.





















































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)

