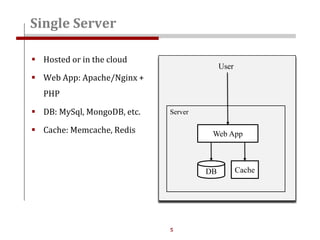
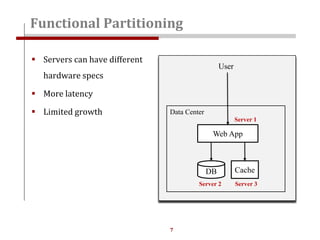
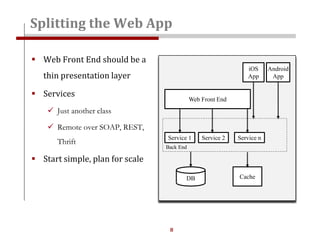
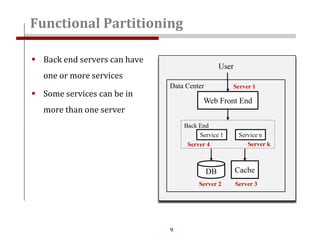
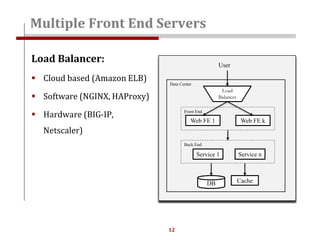
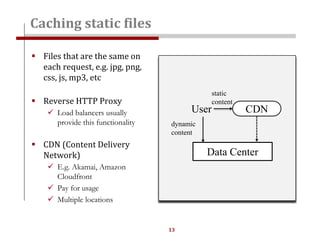
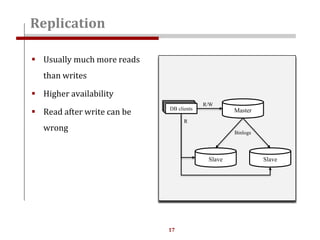
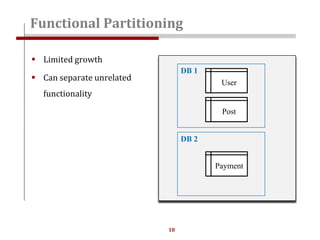
The document discusses strategies for scaling websites, including scalable architecture, database scaling techniques such as replication and sharding, and the importance of caching for performance. It covers methods for introducing new features effectively through development branches, feature toggles, and percentage rollouts. Additionally, it emphasizes the need for a stateless architecture and external storage solutions to support scalable web applications.















![28
Usually required at large scale
Key-Value stores
Set(key, value[, TTL])
Get(key)
Delete(key)
Different levels
Client side (e.g. in the browser in JS)
In the WebServer (e.g. APC)
Distributed cache (e.g. Redis, Memcached)
Caching application data](https://image.slidesharecdn.com/scalingyourwebsite-draft-160531233213/85/Scaling-your-website-28-320.jpg)



























































































