Downloaded 61 times





![Denormalize{ userid: 100,books: [{ title: ‘James and the Giant Peach’,author: ‘Roald Dahl’ },{ title: ‘Charlotte’s Web’,author: ‘E B White’ },{ title: ‘A Wrinkle in Time’,author: ‘Madeleine L’Engle’ }]}](https://image.slidesharecdn.com/scaling-100729162243-phpapp02/85/Scaling-with-MongoDB-5-320.jpg)
![Use IndicesFind by valuedb.users.find( { userid: 100 } )Find by range of valuesdb.users.find( { age: { $gte: 20, $lte: 40 } } )db.users.find( { hobbies: { $in: [ ‘biking’, ‘running’, ‘swimming’ ] } )Find with a sort specdb.users.find().sort( { signup_ts: -1 } )db.users.find( { hobbies: ‘snorkeling’ } ).sort( { signup_ts: -1 } )Index on { hobbies: 1, signup_ts: -1 }](https://image.slidesharecdn.com/scaling-100729162243-phpapp02/85/Scaling-with-MongoDB-6-320.jpg)












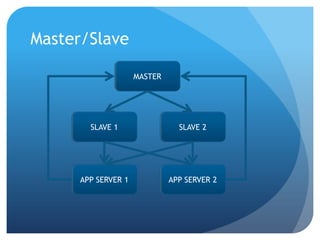
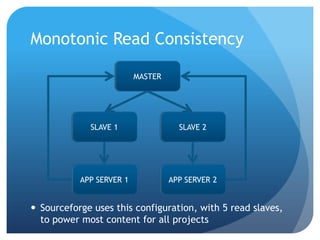






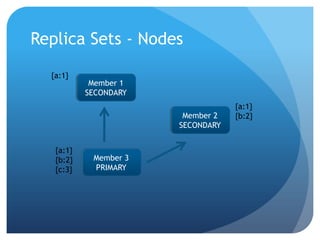
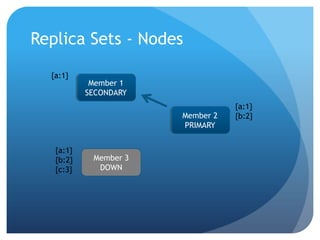



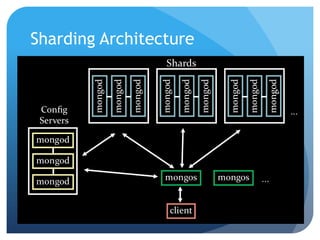














This document summarizes techniques for scaling MongoDB deployments, including: - Single server read/write scaling using techniques like denormalization, indexing, and restricting fields - Scaling reads using master-slave replication and replica sets for improved availability and read scaling - Scaling reads and writes using sharding to partition data across multiple servers and distribute load























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































