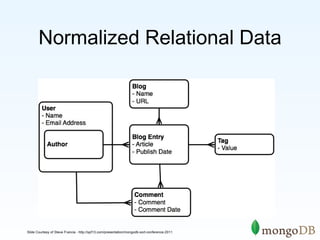
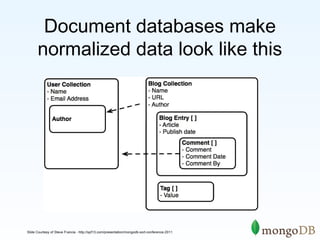
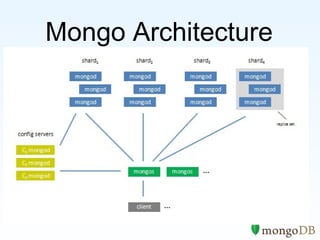
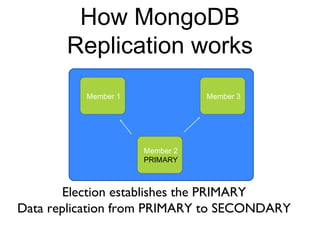
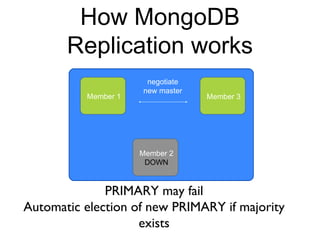
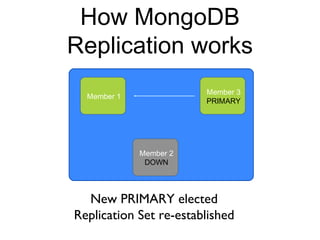
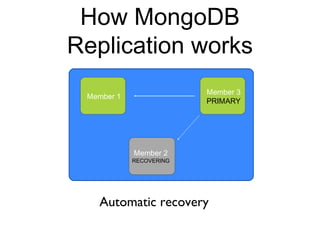
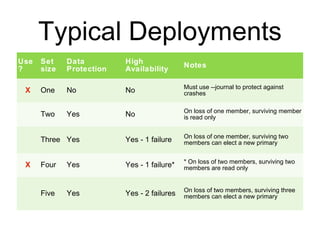
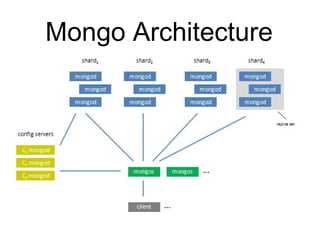
The document discusses the advantages and use cases for MongoDB, highlighting its flexibility, scalability, and performance improvements over traditional databases like Oracle and MySQL. It outlines specific scenarios where MongoDB provided significant cost reductions and performance enhancements, emphasizing its document-oriented architecture and features like sharding and replication. Limitations of MongoDB, such as the lack of multi-document transactions and certain schema constraints, are also addressed.













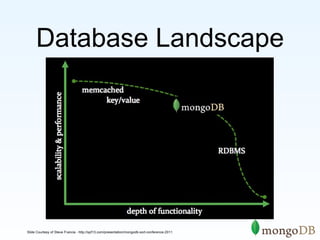
![MongoDB is:
Horizontally Scalable
Document
Oriented
{{ aauutthhoorr:: ““sstteevvee””,,
ddaattee:: nneeww DDaattee(()),,
tteexxtt:: ““AAbboouutt MMoonnggooDDBB......””,,
ttaaggss:: [[““tteecchh””,, ““ddaattaabbaassee””]]}}
Application
High
Performance
Slide Courtesy of Steve Francia - http://spf13.com/presentation/mongodb-sort-conference-2011](https://image.slidesharecdn.com/prosandconsofmongo-141105070805-conversion-gate02/85/MongoDB-Pros-and-Cons-14-320.jpg)




![Insert Document
> p = {author: "roger",
date: new Date(),
text: "about mongoDB...",
tags: ["tech", "databases"]}
> db.posts.save(p)
SQL equivalent
INSERT INTO posts (col1, col2, …)
VALUES (val1, val2, …)](https://image.slidesharecdn.com/prosandconsofmongo-141105070805-conversion-gate02/85/MongoDB-Pros-and-Cons-21-320.jpg)
![Querying
> db.posts.find()
> { _id : ObjectId("4c4ba5c0672c685e5e8aabf3"),
author : "roger",
date : "Sat Jul 24 2010 19:47:11",
text : "About MongoDB...",
tags : [ "tech", "databases" ] }
SQL equivalent
SELECT * FROM POSTS](https://image.slidesharecdn.com/prosandconsofmongo-141105070805-conversion-gate02/85/MongoDB-Pros-and-Cons-22-320.jpg)



















































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)