Downloaded 132 times












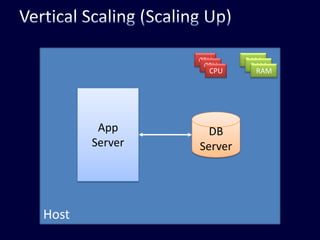


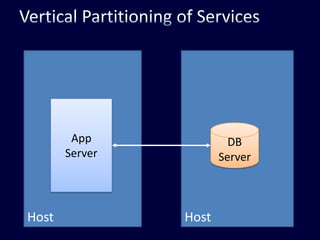

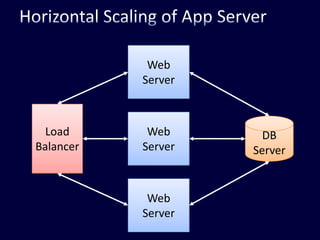

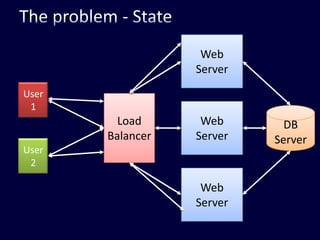






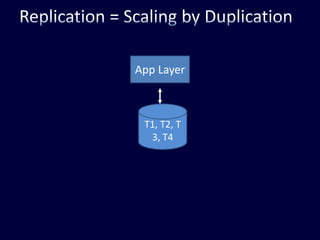
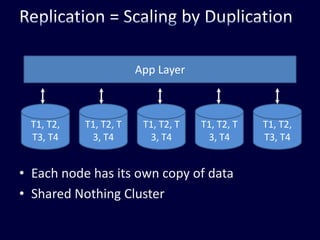

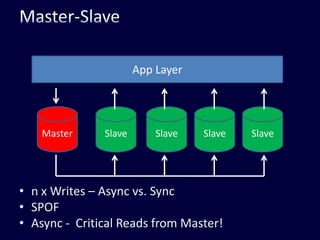
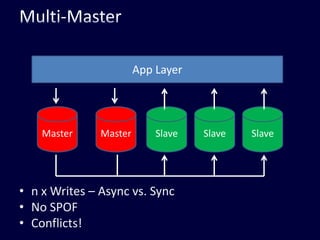


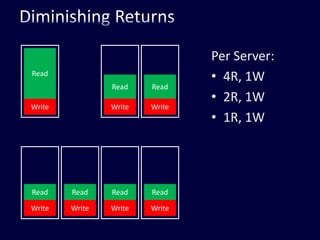


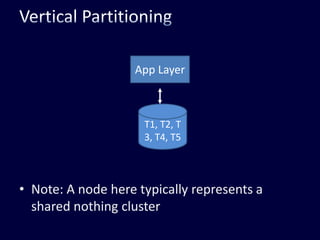
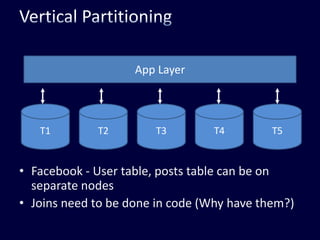
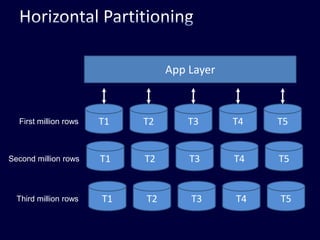


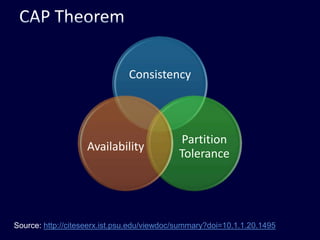
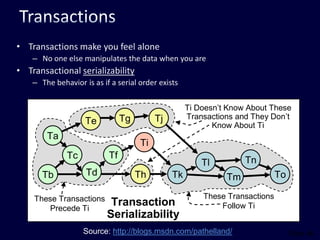
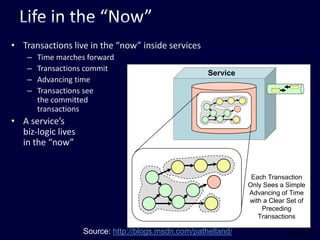


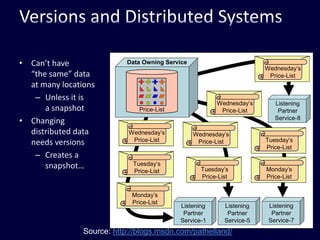




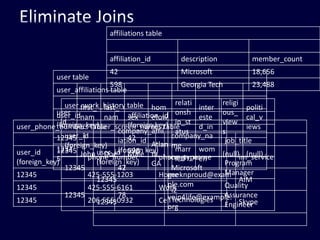



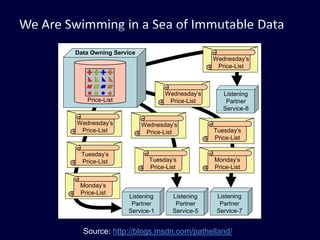


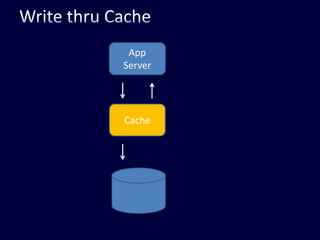
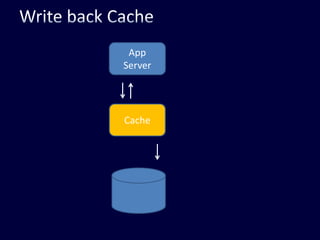
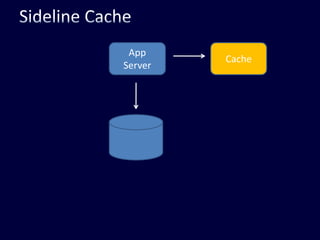










This document discusses strategies for handling large amounts of data in web applications. It begins by providing examples of how much data some large websites contain, ranging from terabytes to petabytes. It then covers various techniques for scaling data handling capabilities including vertical and horizontal scaling, replication, partitioning, consistency models, normalization, caching, and using different data engine types beyond relational databases. The key lessons are that data volumes continue growing rapidly, and a variety of techniques are needed to scale across servers, datacenters, and provide high performance and availability.














![[DO08] 『変わらない開発現場』を変えていくために ~エンプラ系レガシー SIer のための DevOps 再入門~](https://cdn.slidesharecdn.com/ss_thumbnails/do08-170616023458-thumbnail.jpg?width=640&height=640&fit=bounds)








































































