Download to read offline







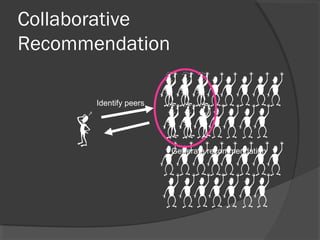







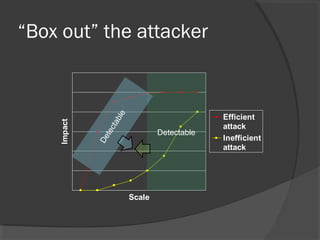


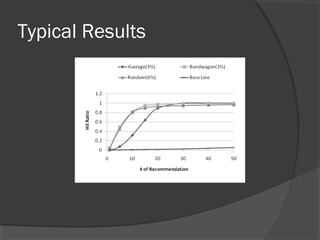

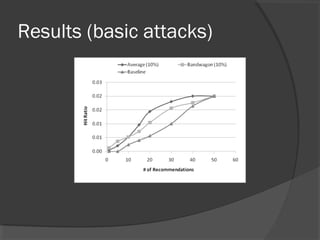



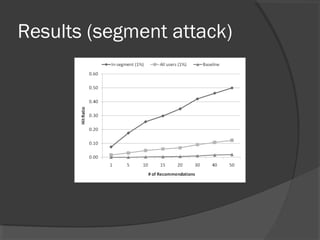

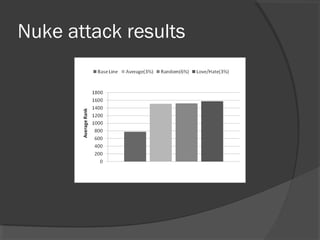








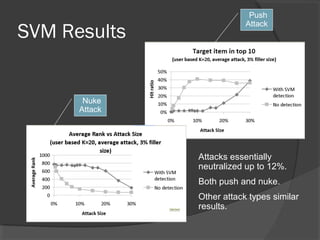




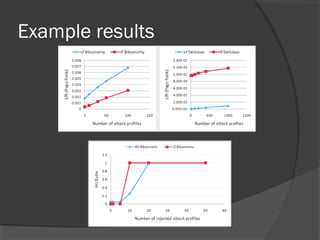
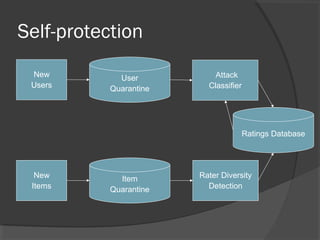




The document discusses attacks on collaborative recommendation systems. It finds that relatively small attacks can be effective at influencing recommendations. Various attack types are explored, including average, bandwagon, segment and nuke attacks. Detection methods are also examined, such as clustering, dimensionality reduction and supervised classification. While detection makes attacks less effective, obfuscated attacks remain a challenge. Overall, the document analyzes how to model and defend against attacks aimed at manipulating the insights provided by collaborative systems.































































