Download as PDF, PPTX


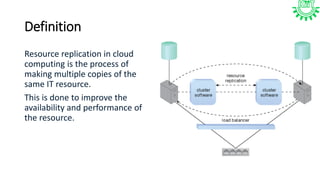


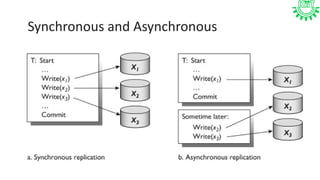







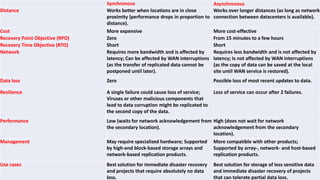

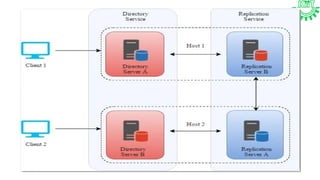


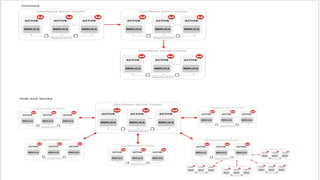

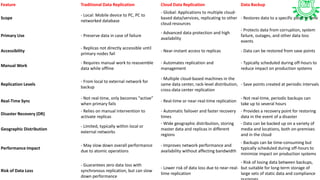

Resource replication in cloud computing involves creating multiple copies of IT resources to enhance availability and performance. It is crucial for reliability, disaster recovery, and application performance, utilizing methods like synchronous and asynchronous replication. Factors such as distance, bandwidth, and replication technology are important for effective execution, and there are distinctions between traditional and cloud-based data replication in terms of scope, accessibility, and recovery times.




















































































