Downloaded 276 times













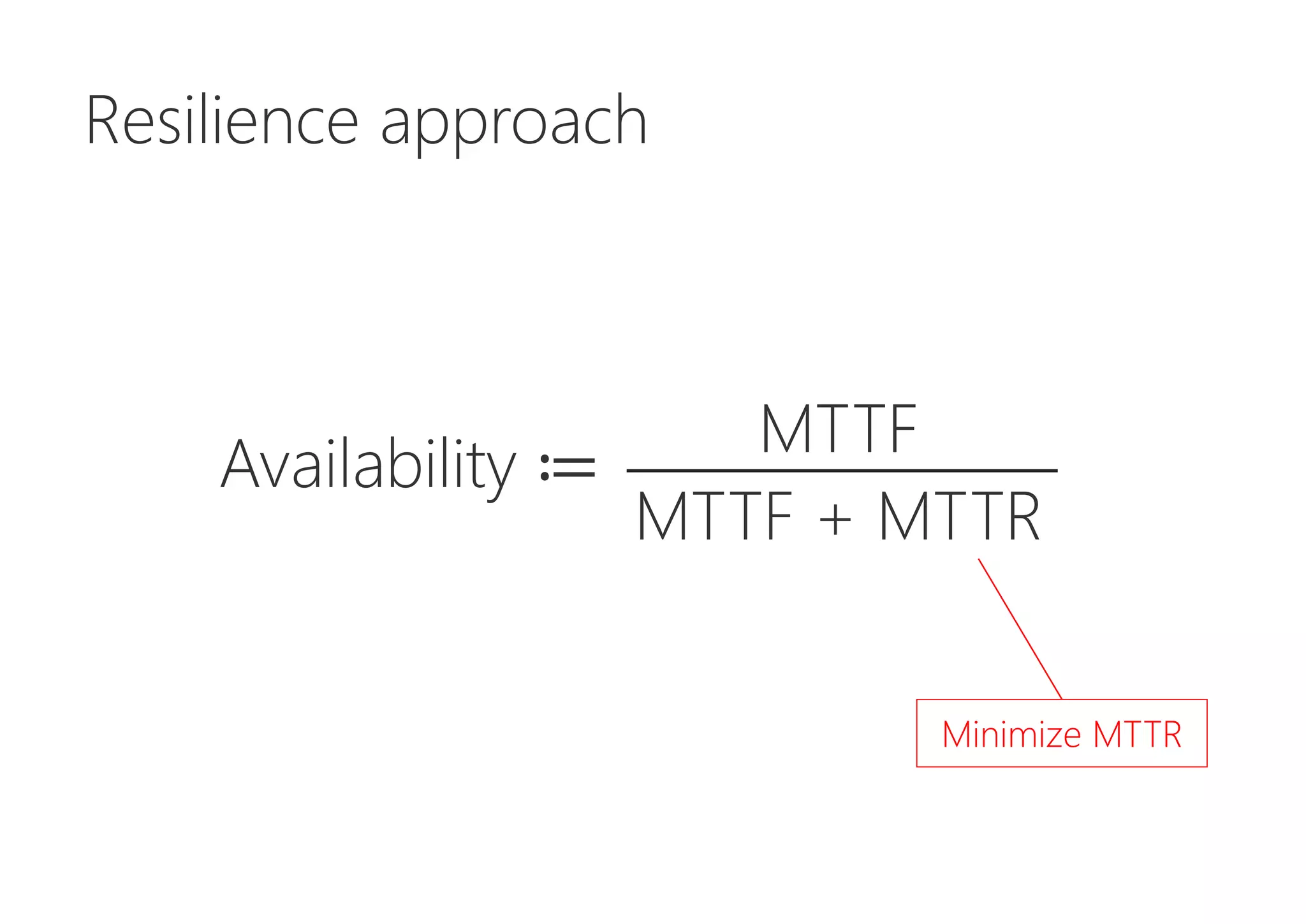

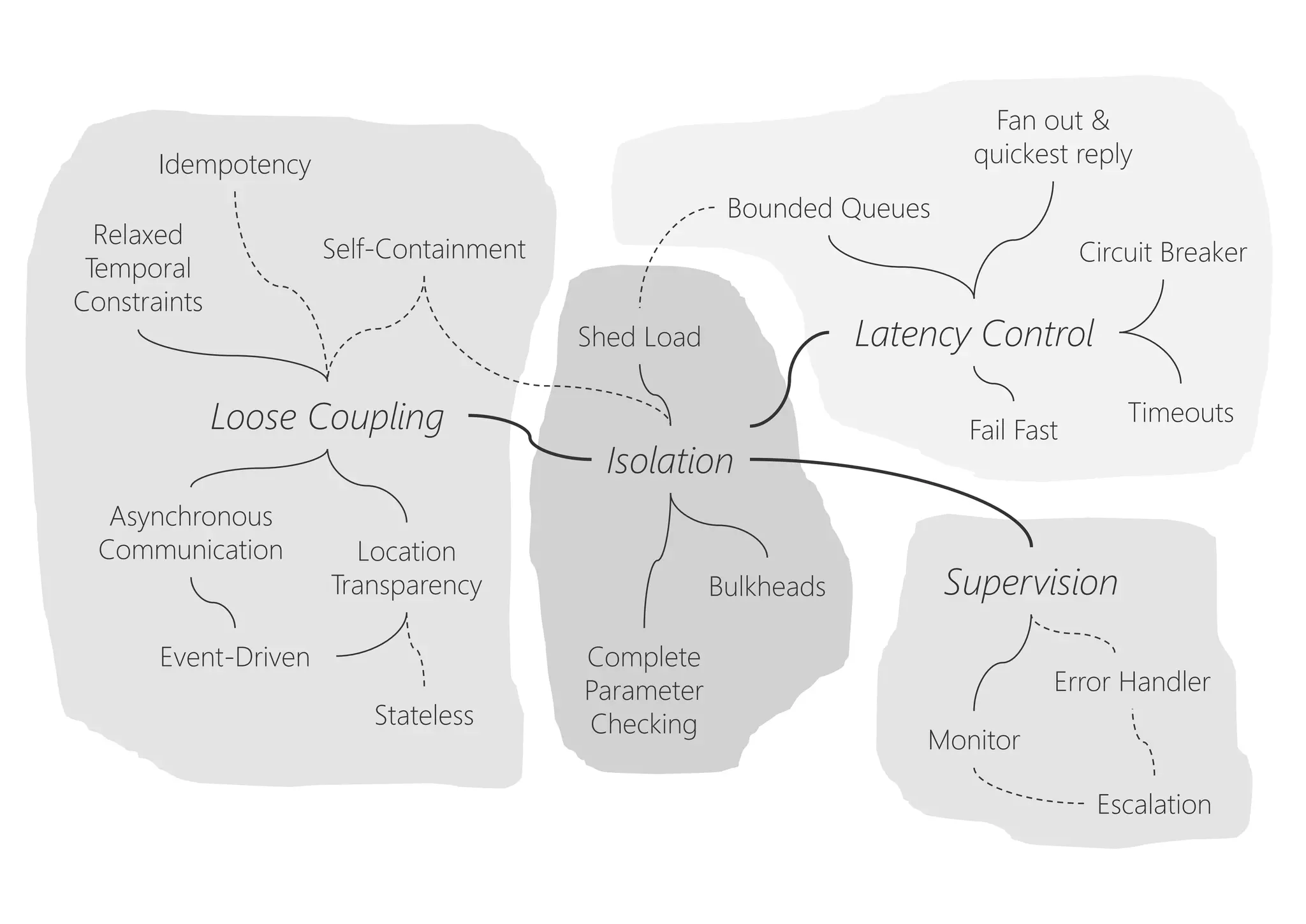



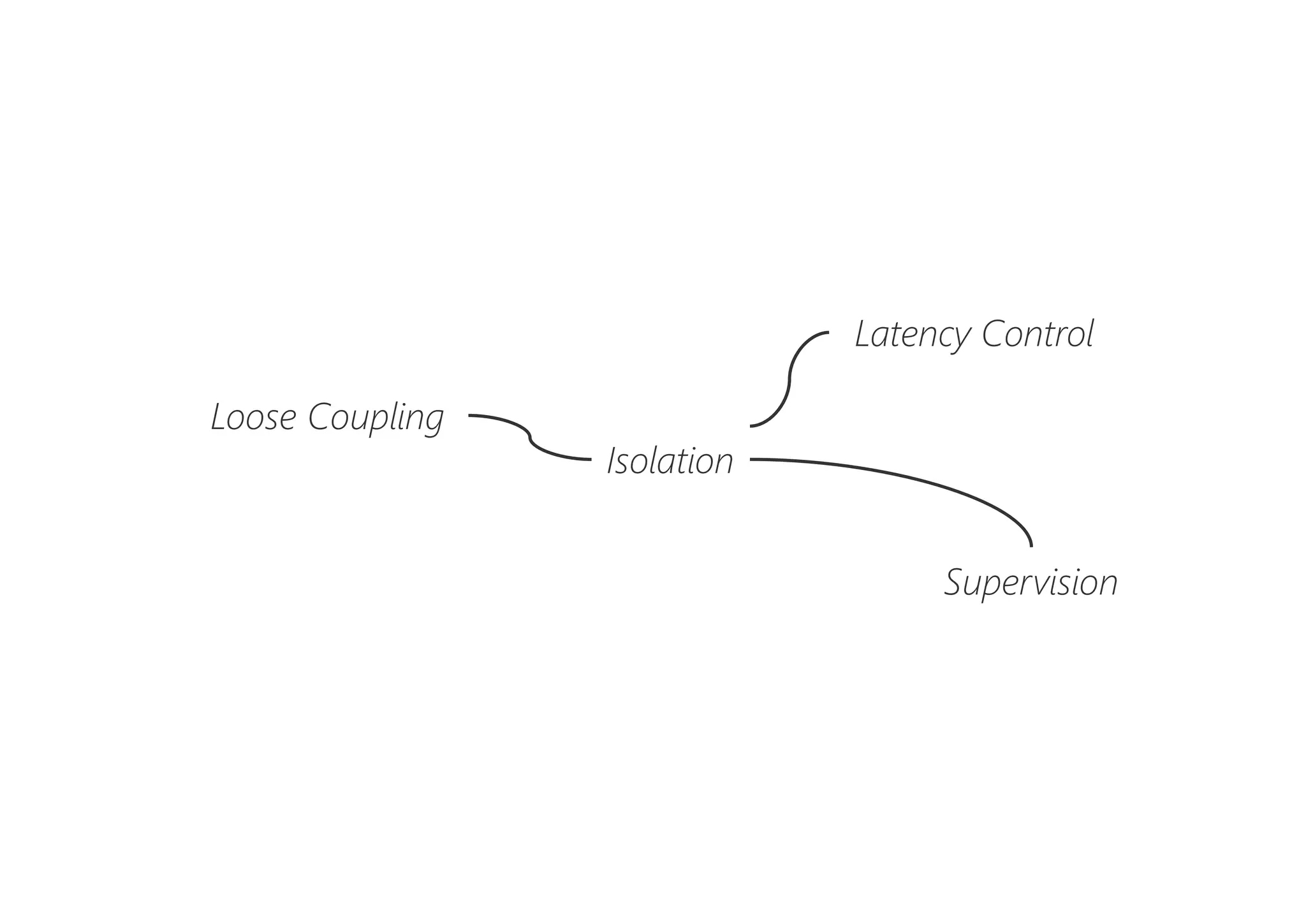
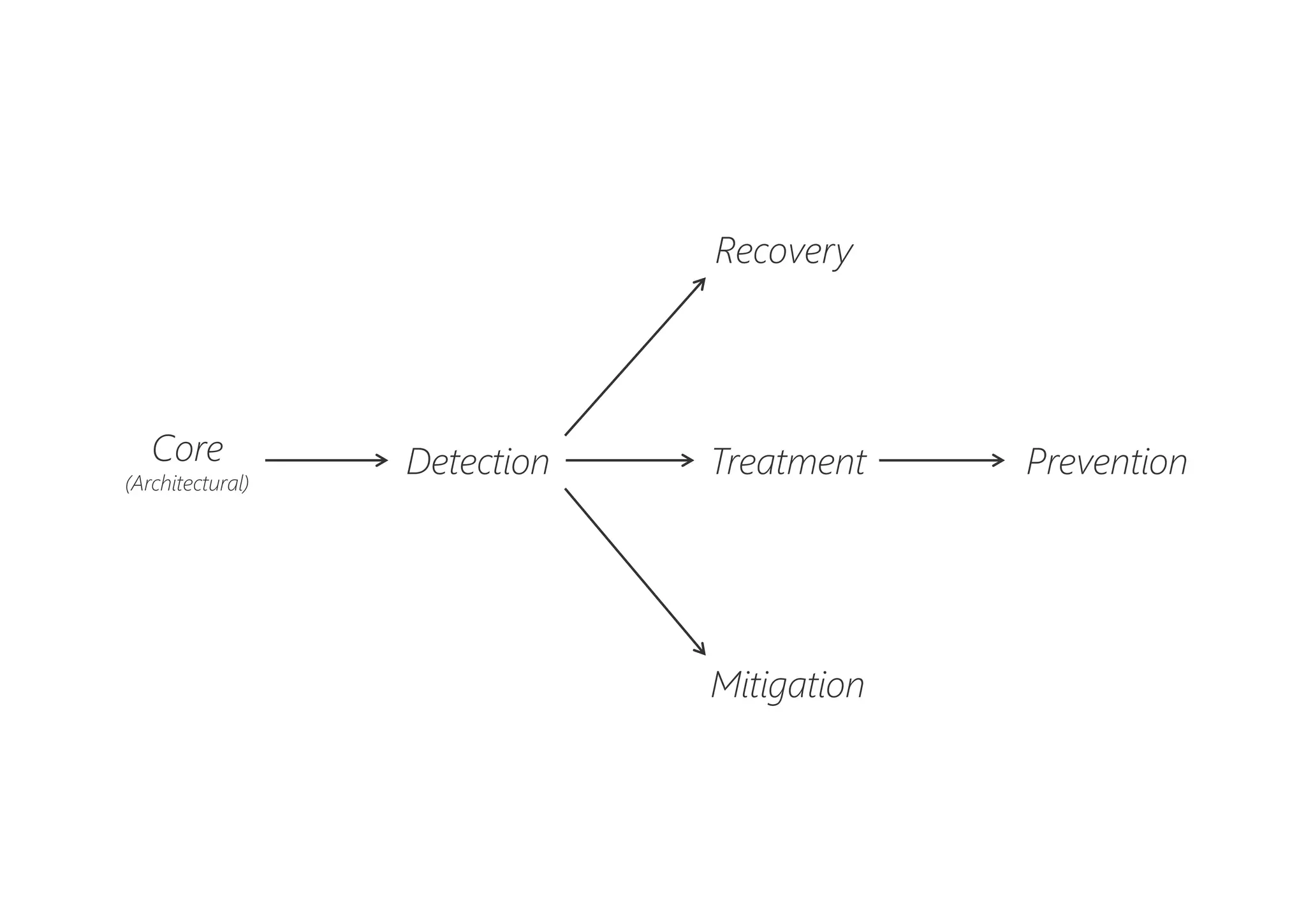
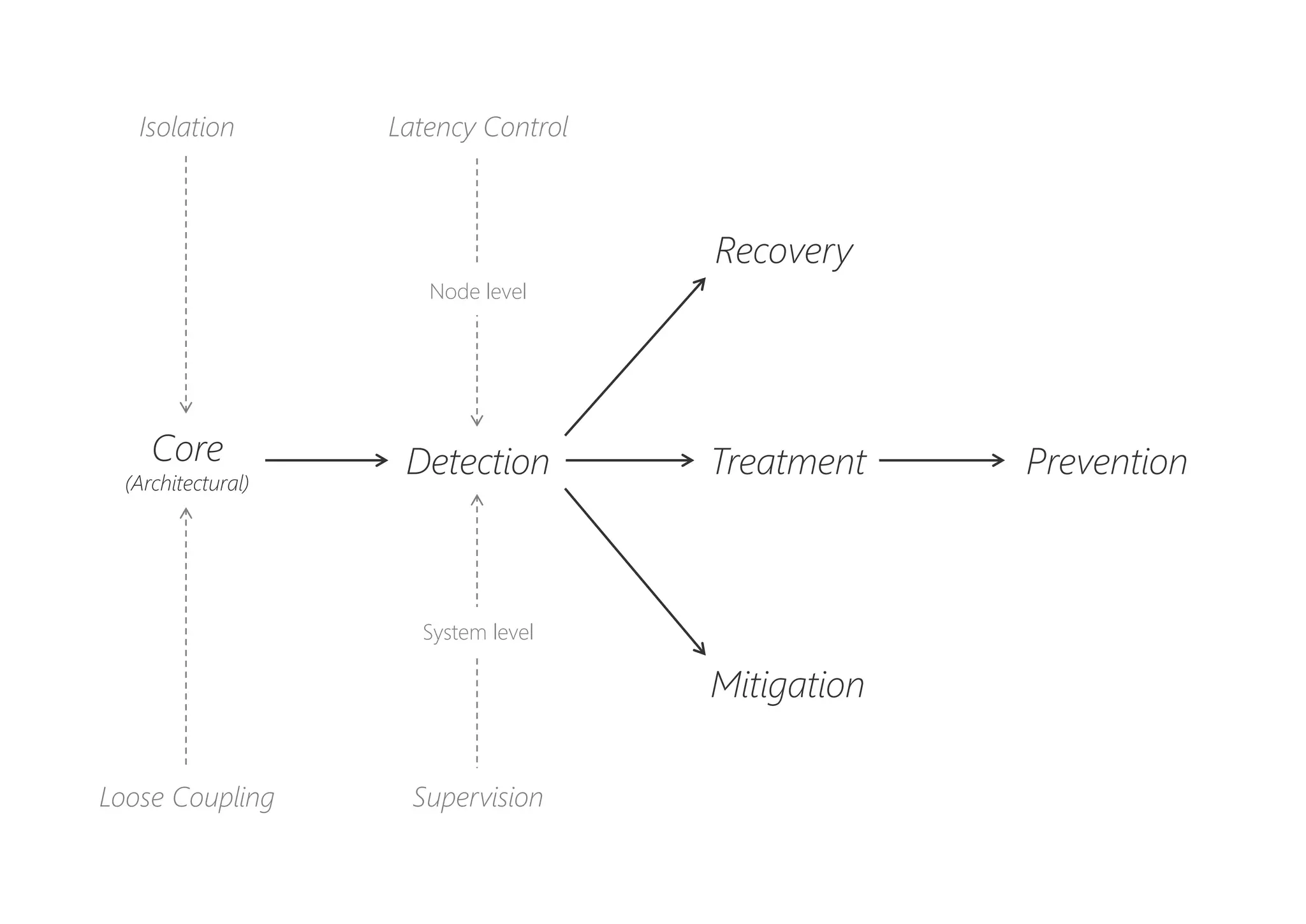
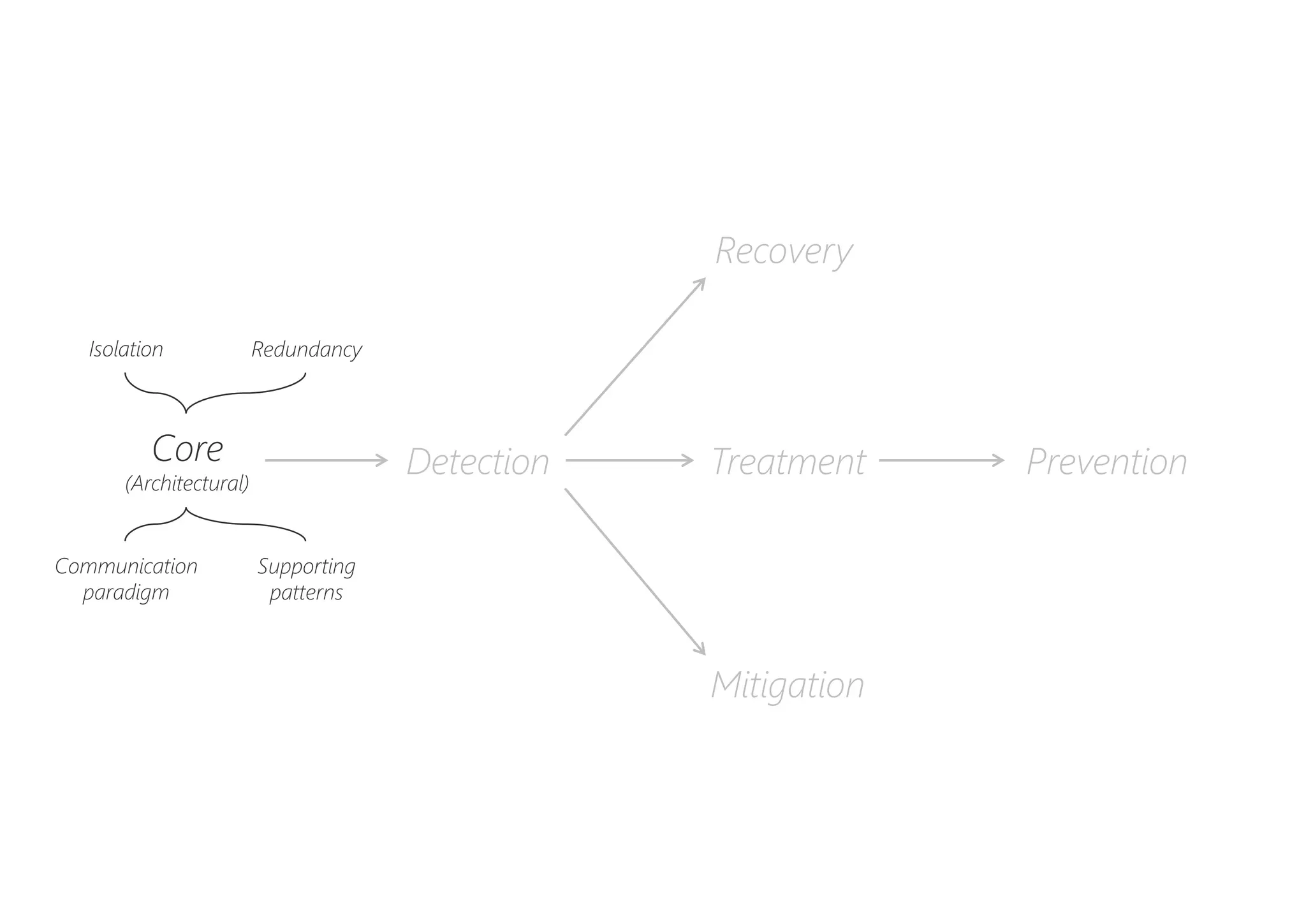
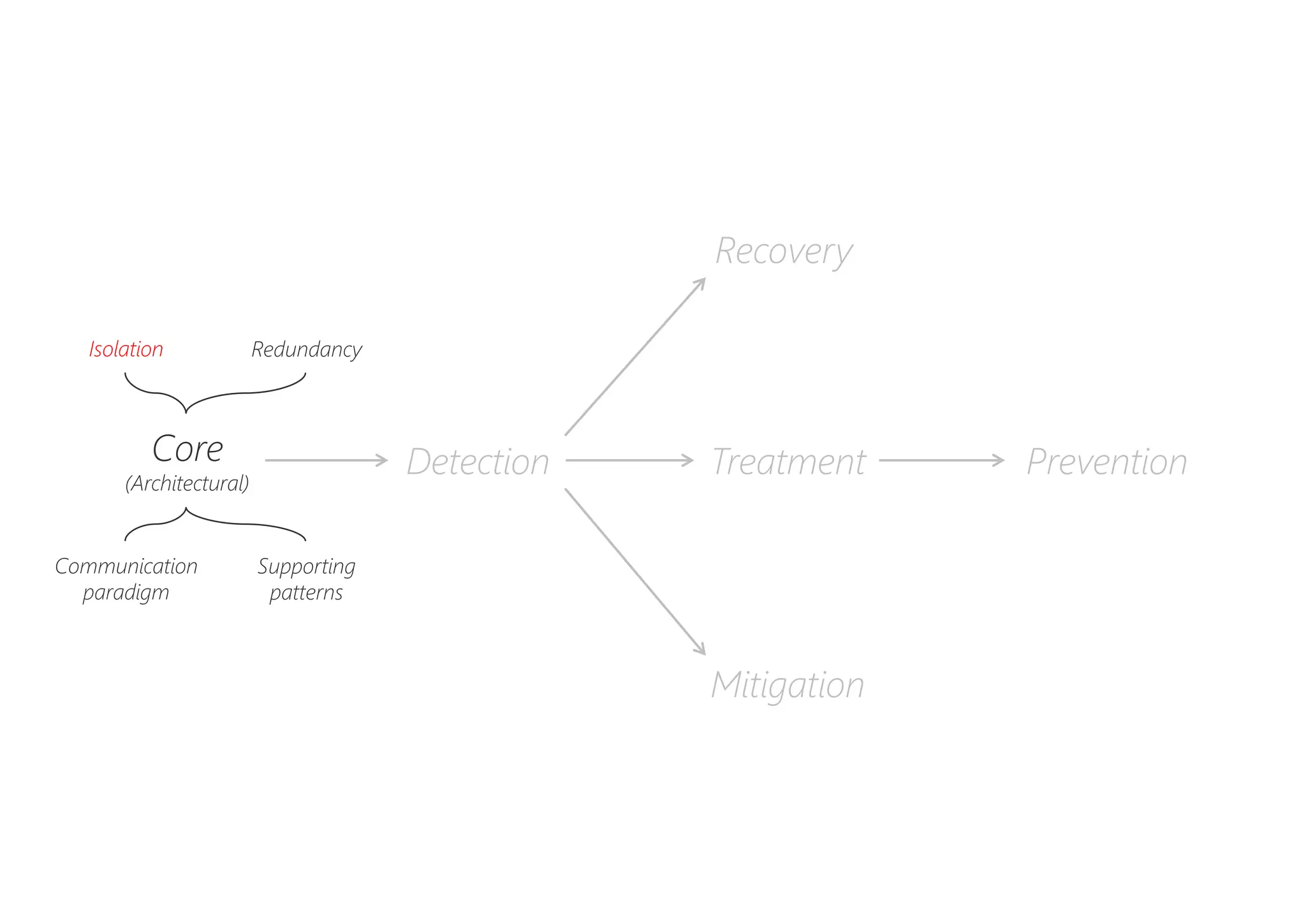


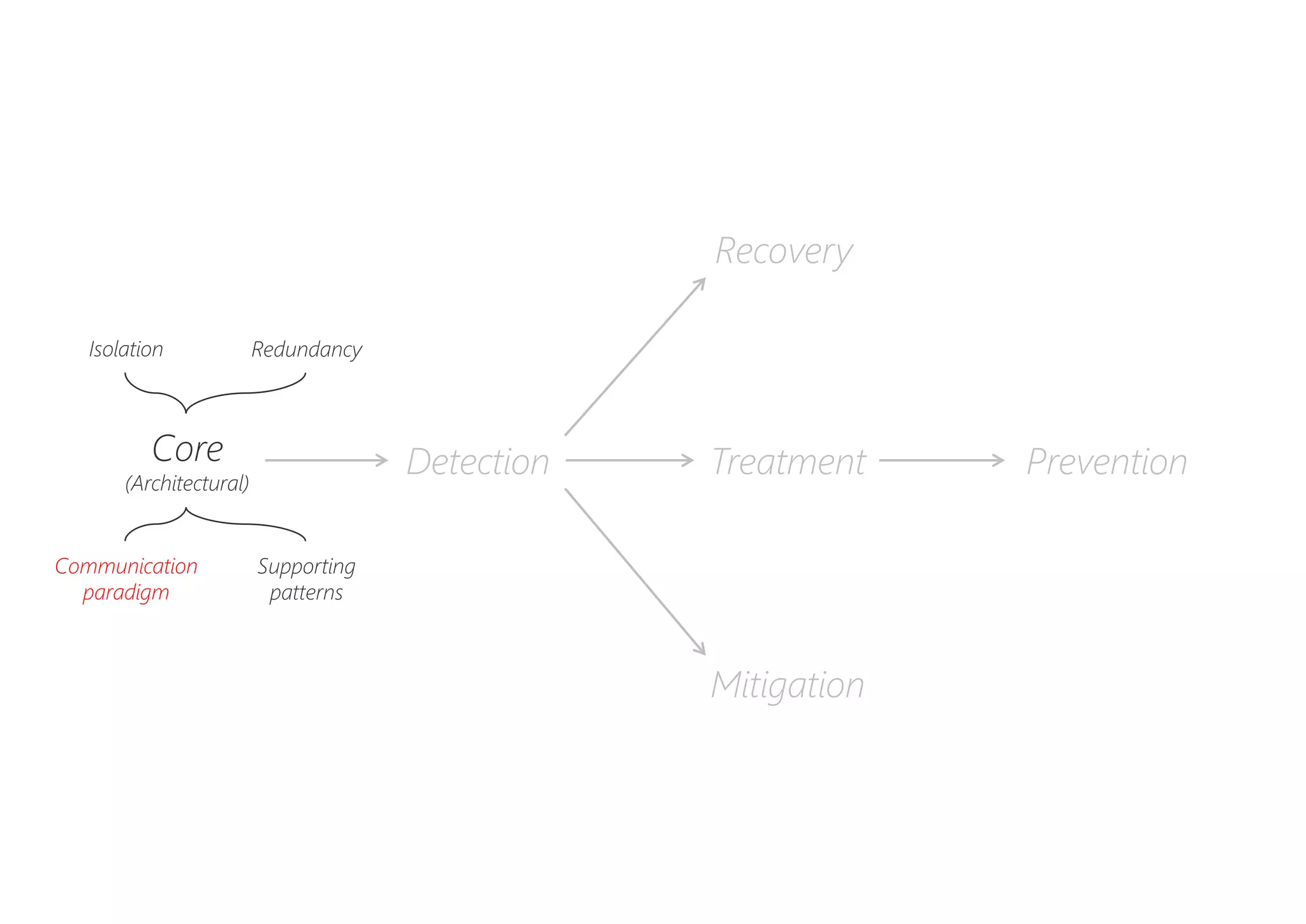










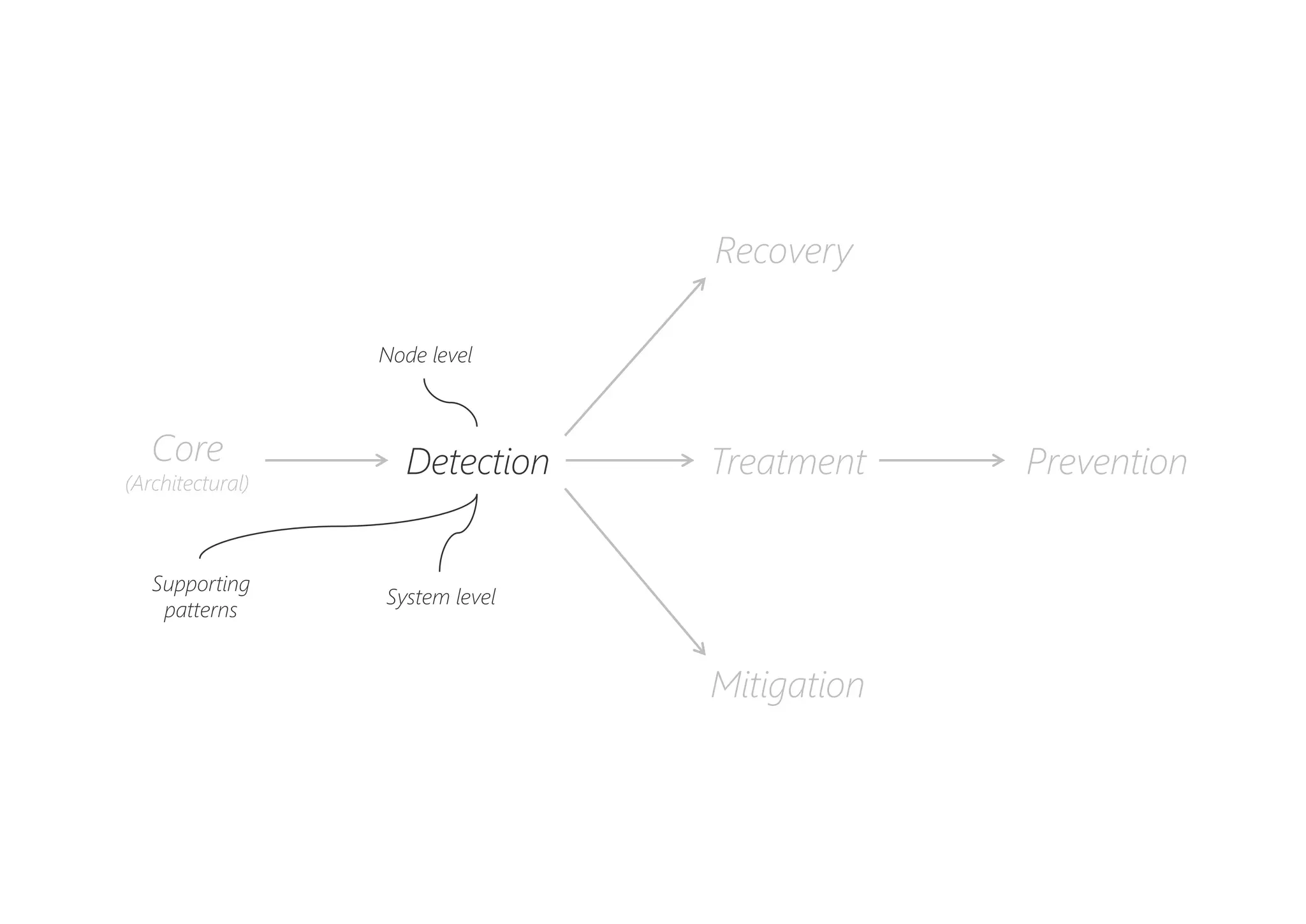
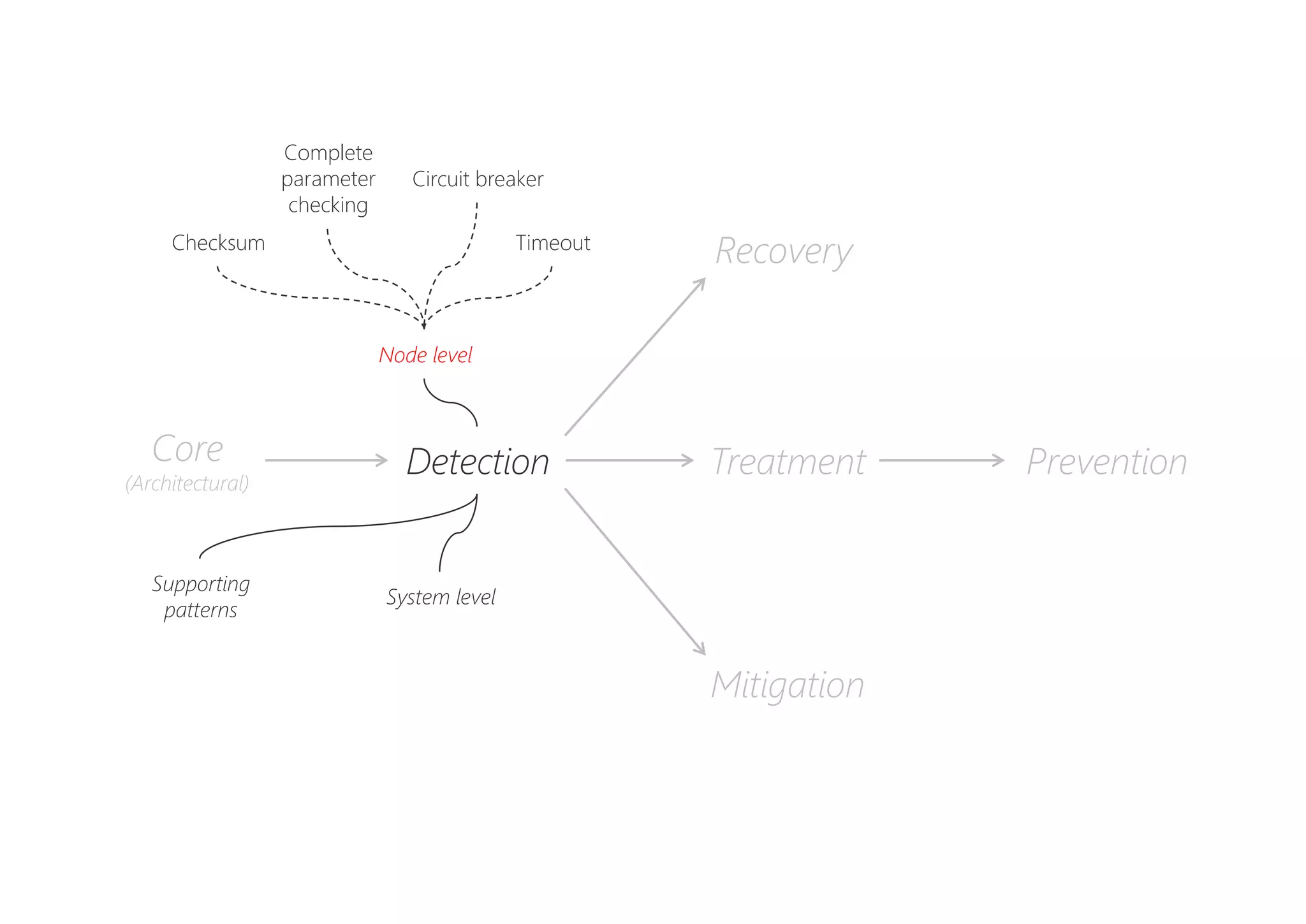
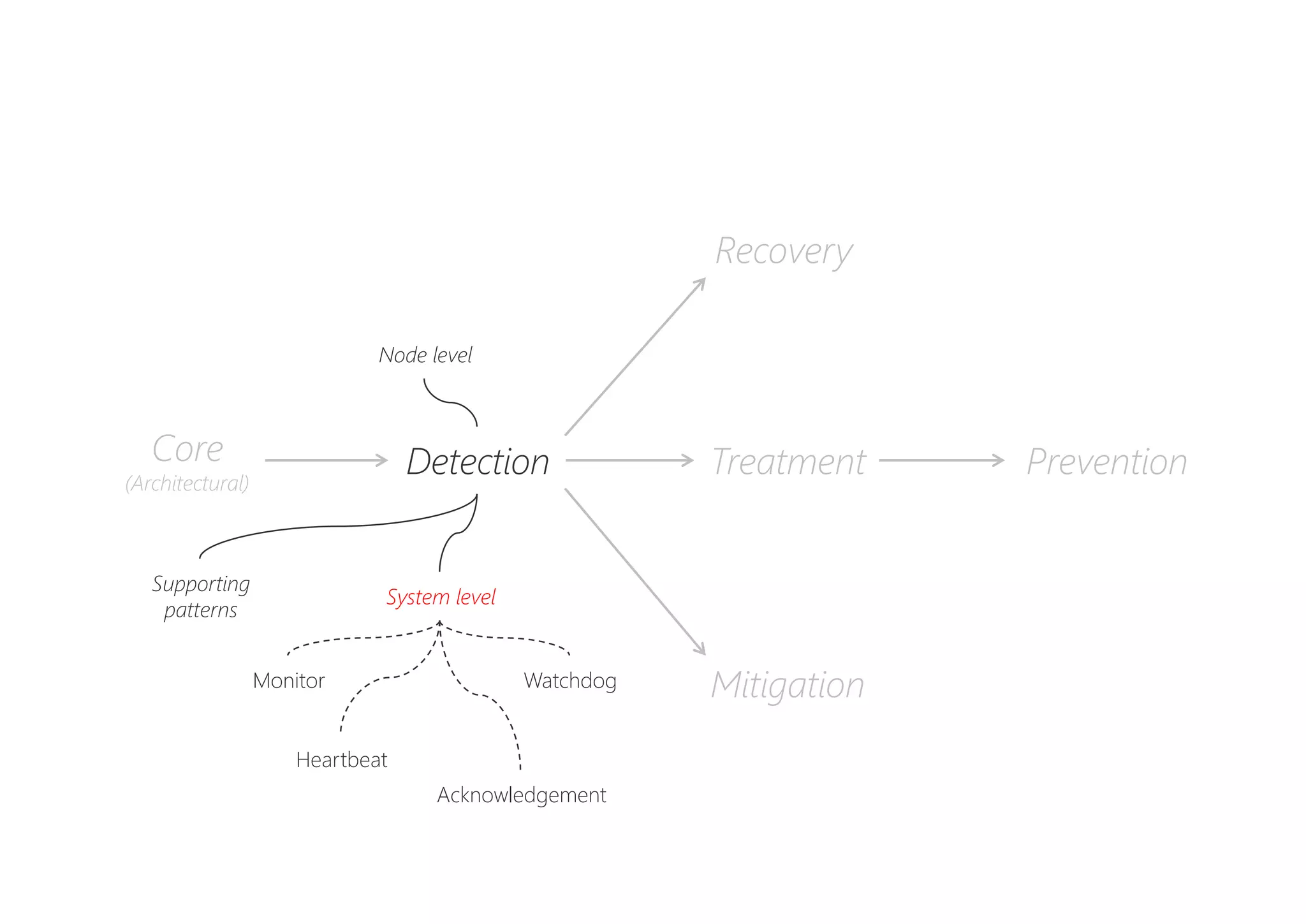
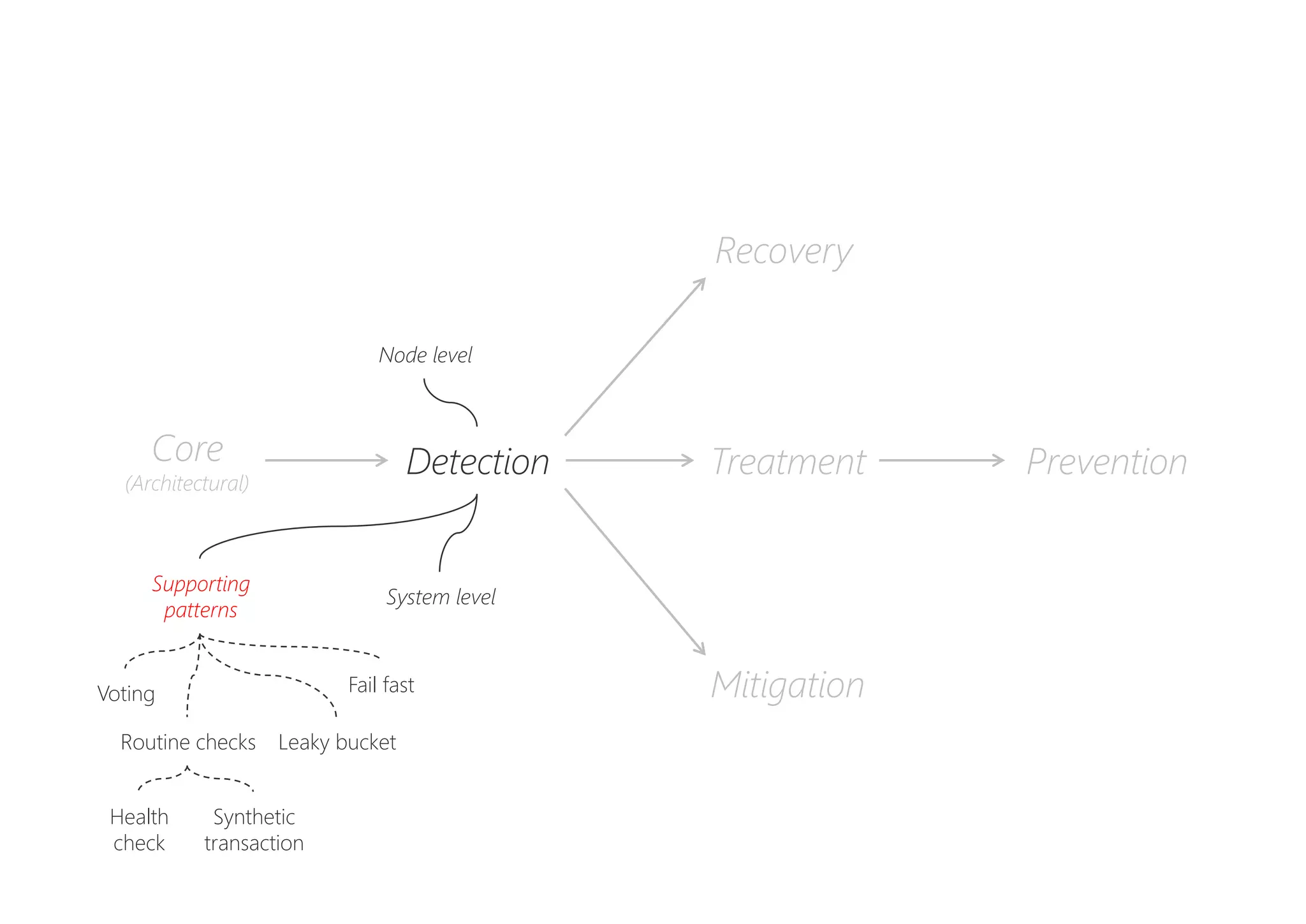
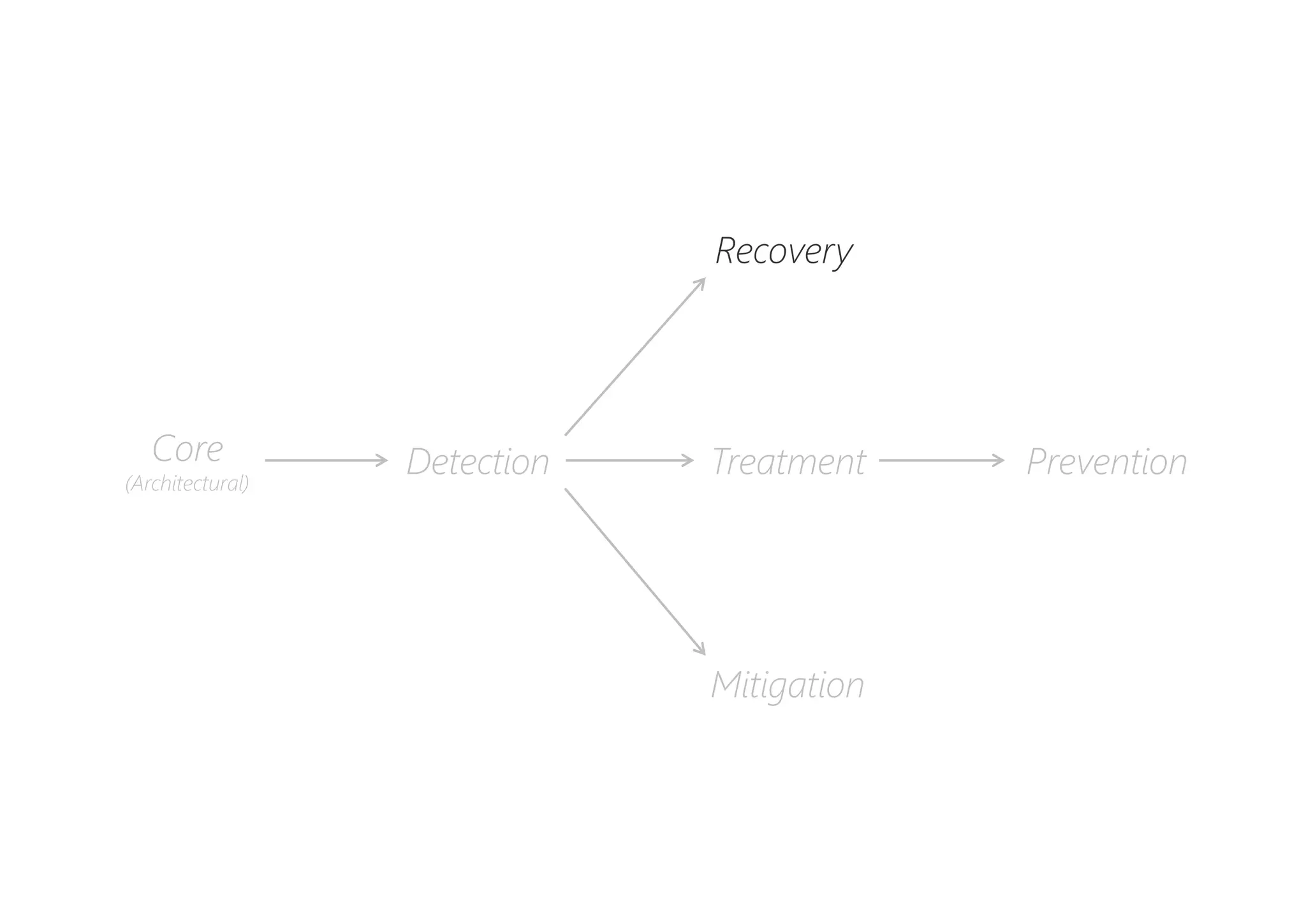
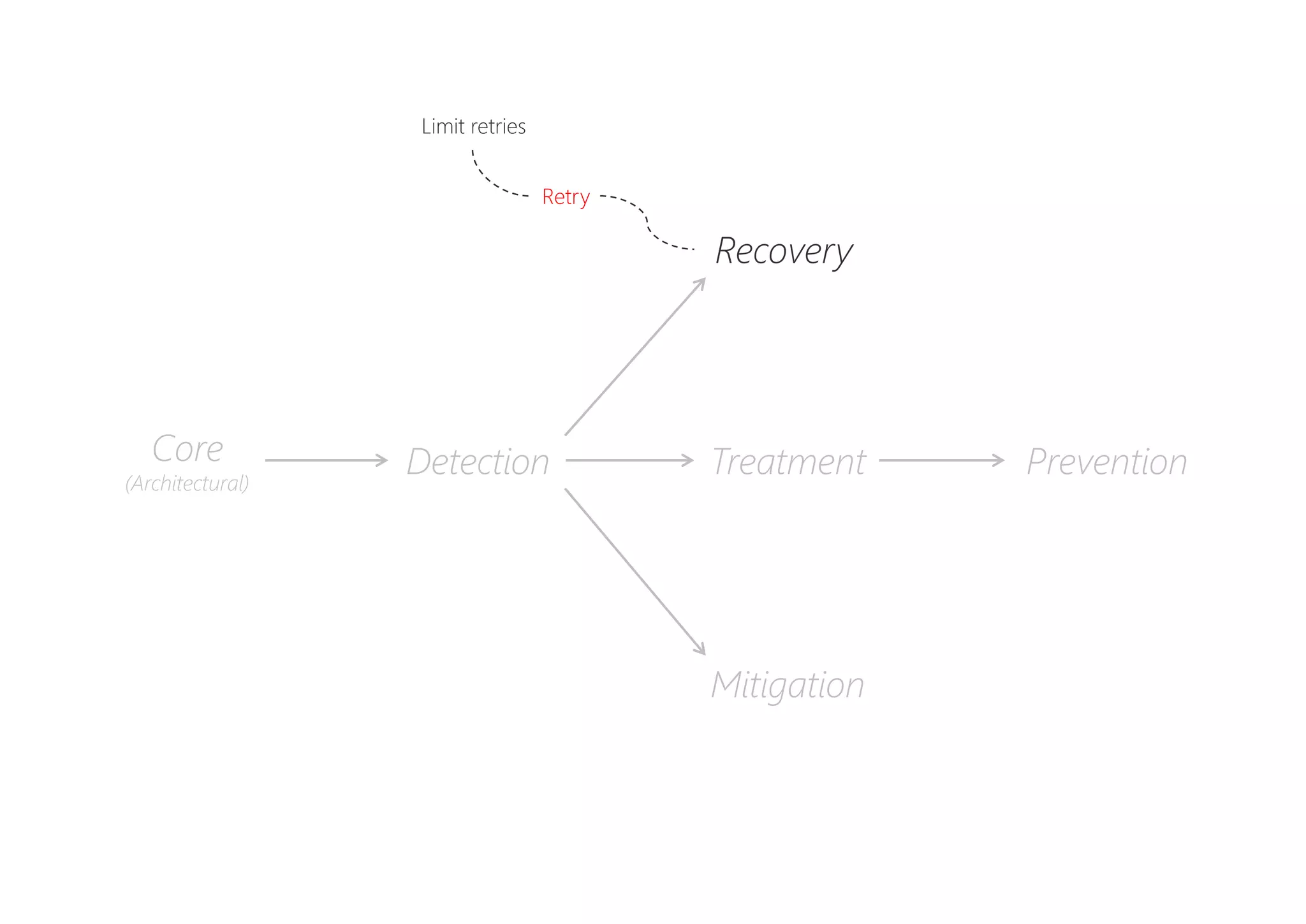


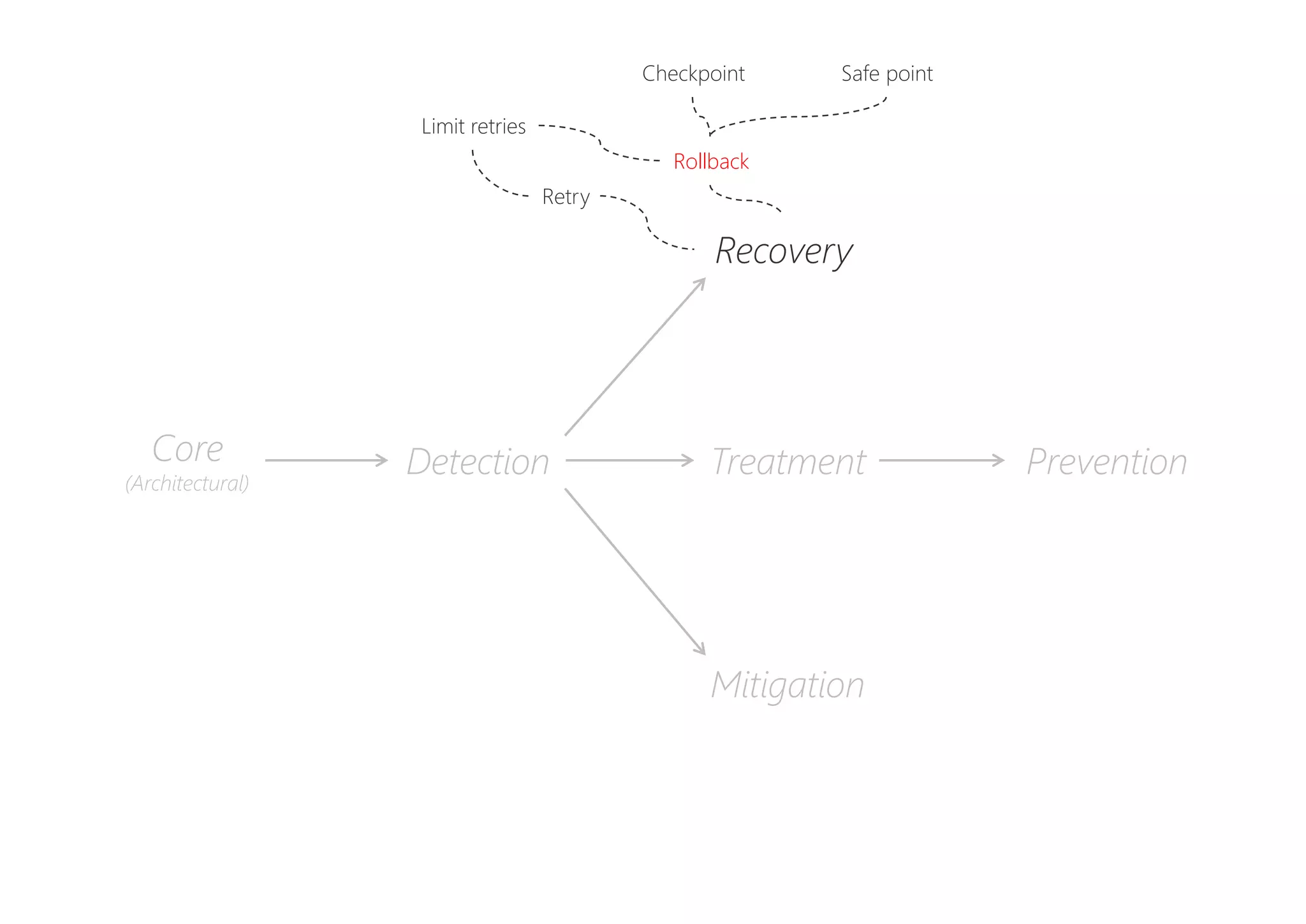

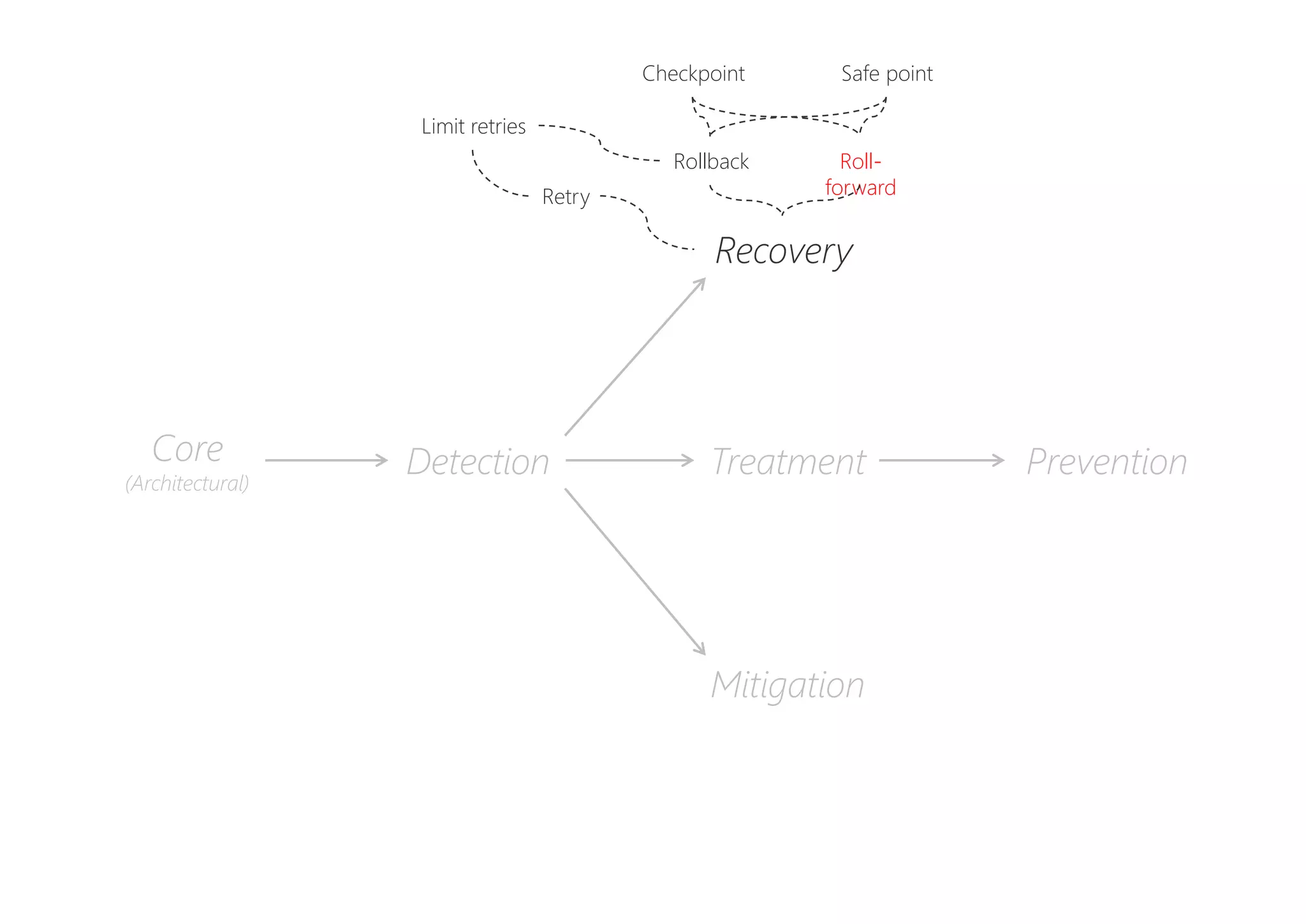



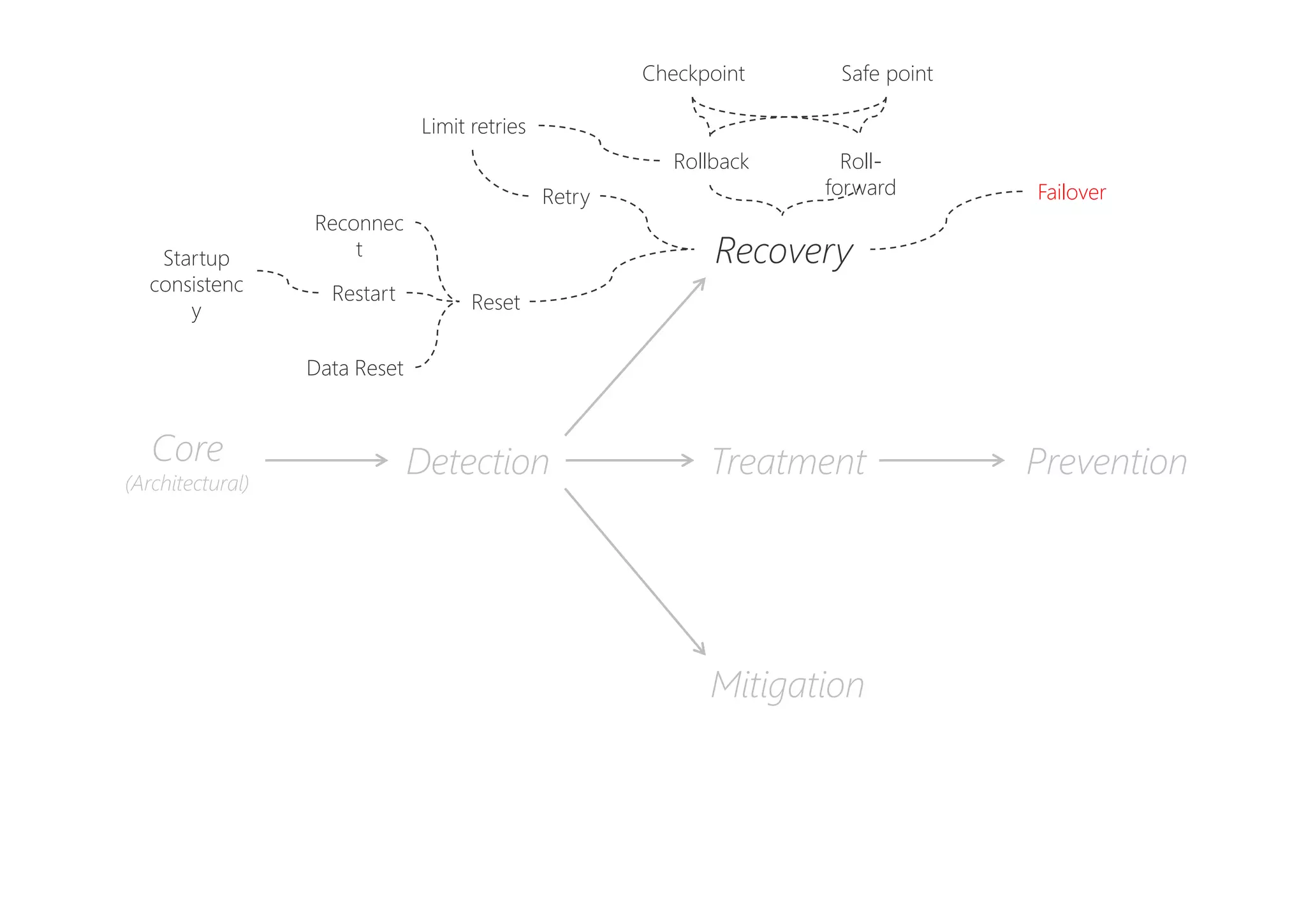

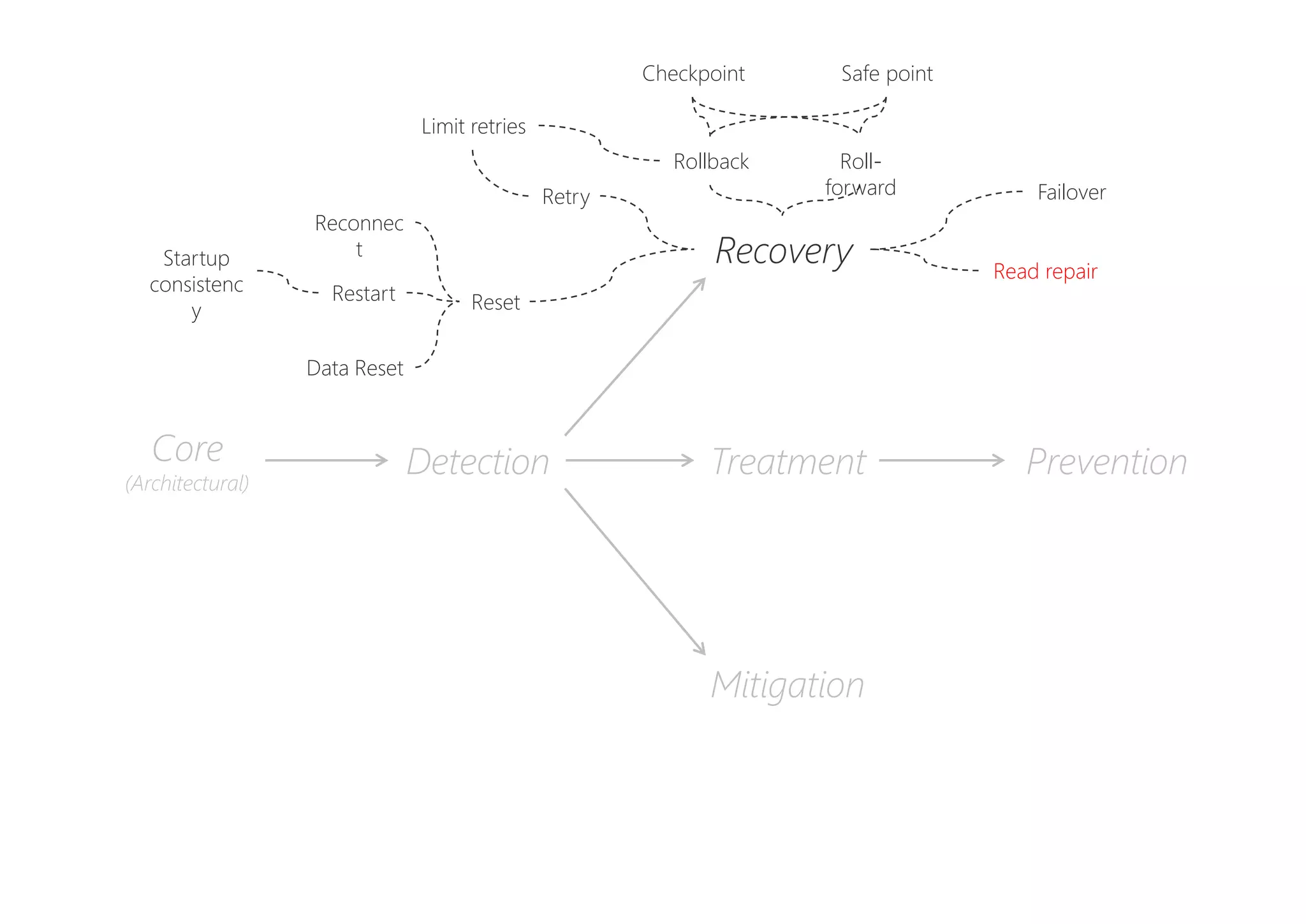






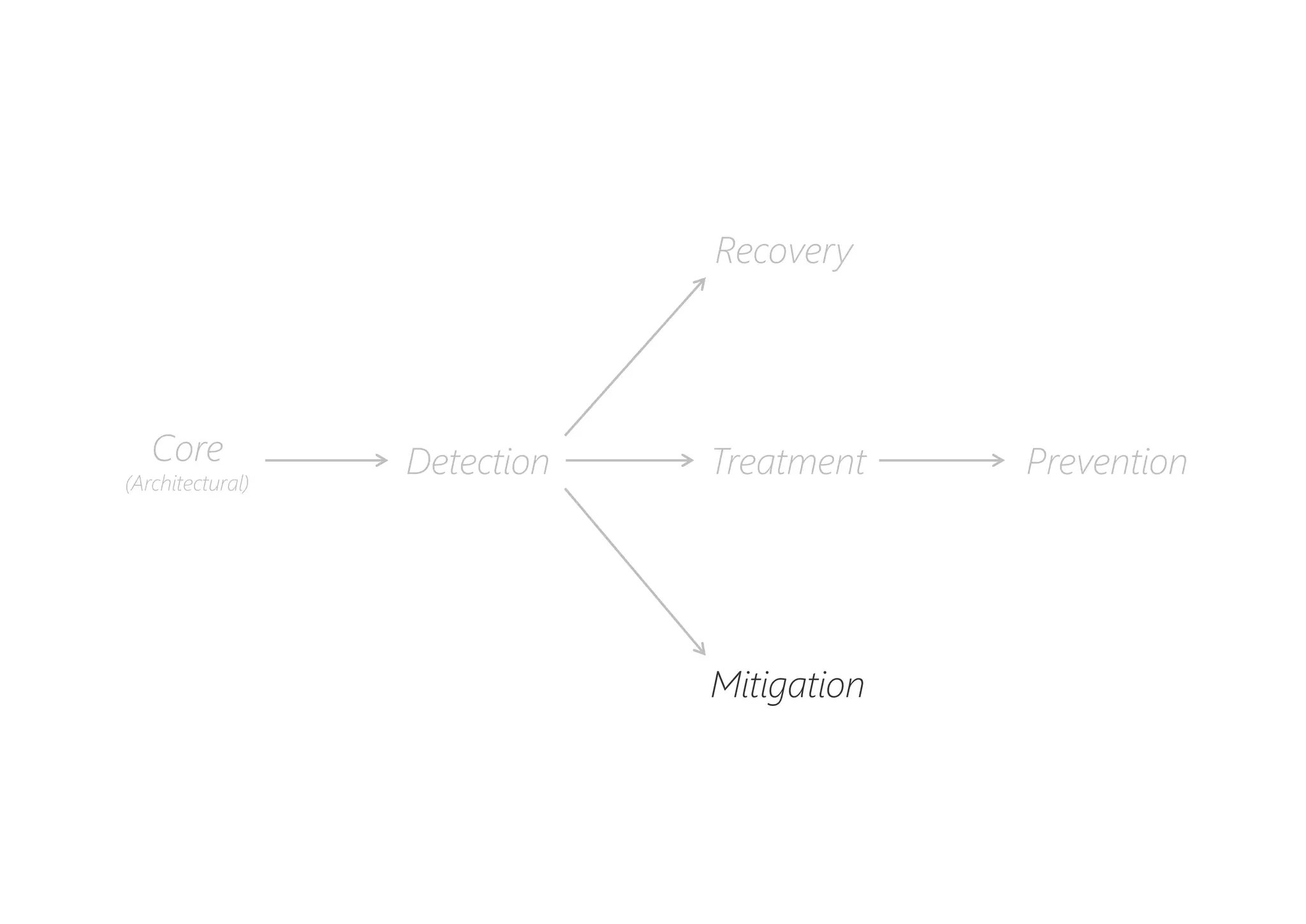




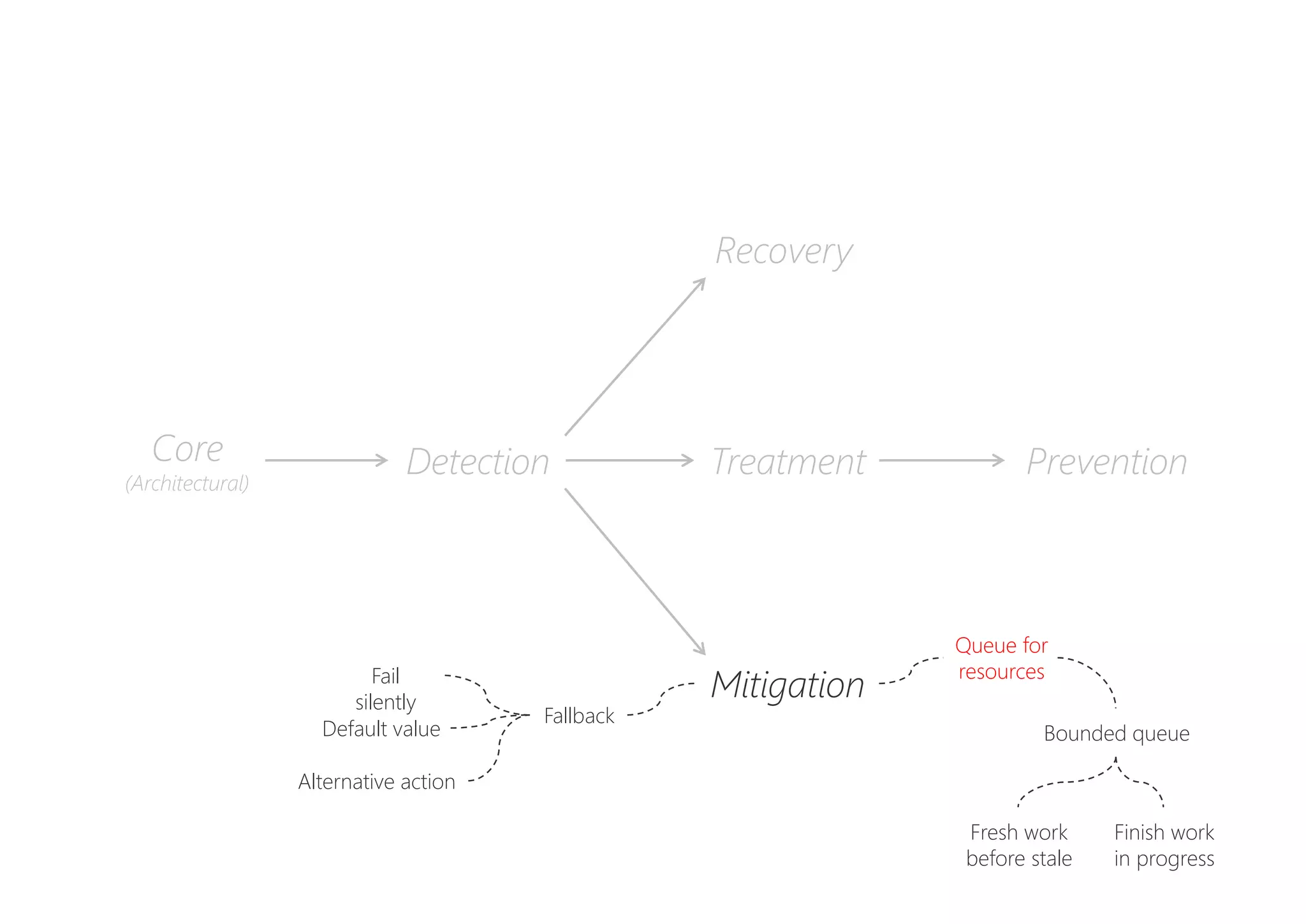

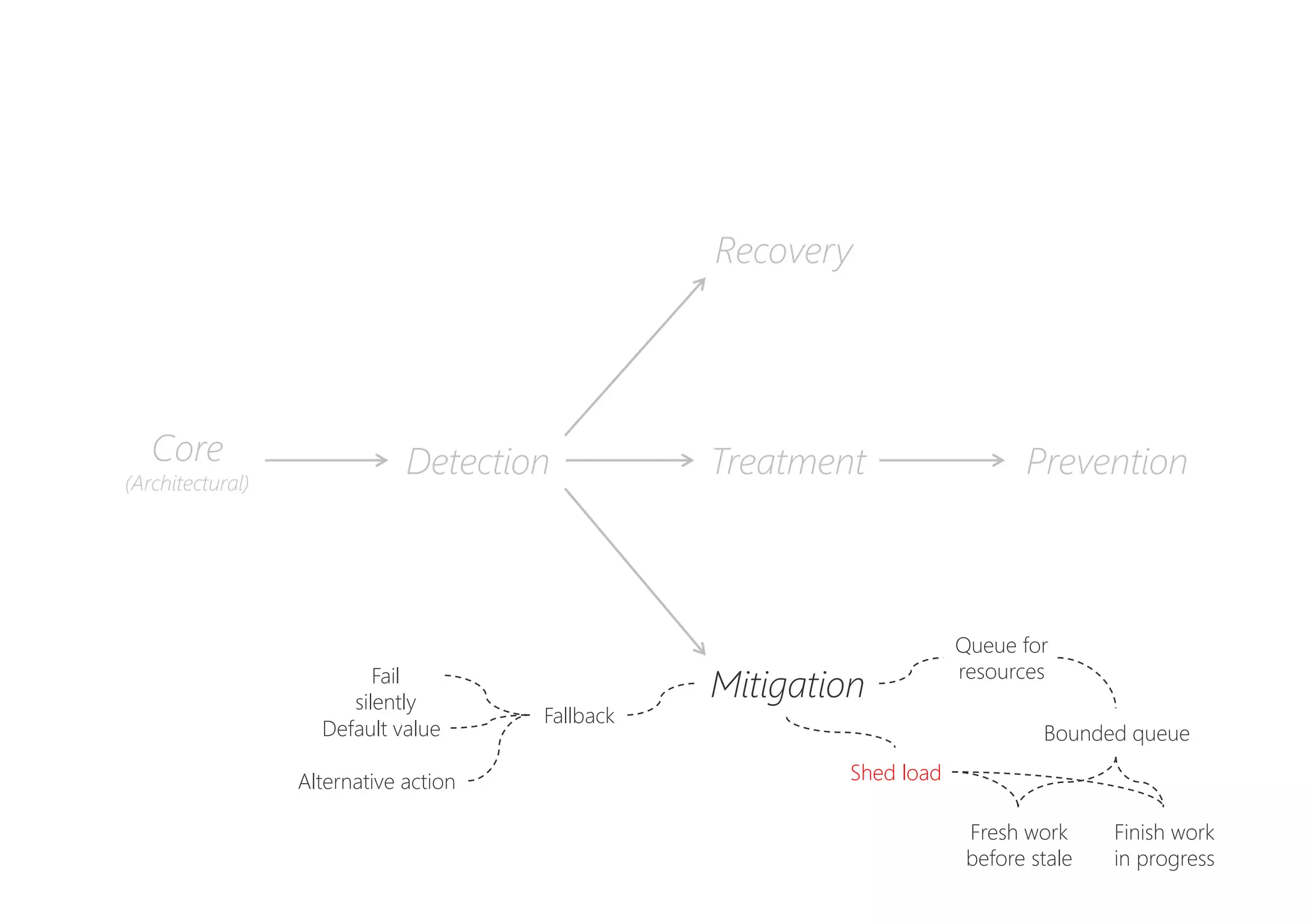

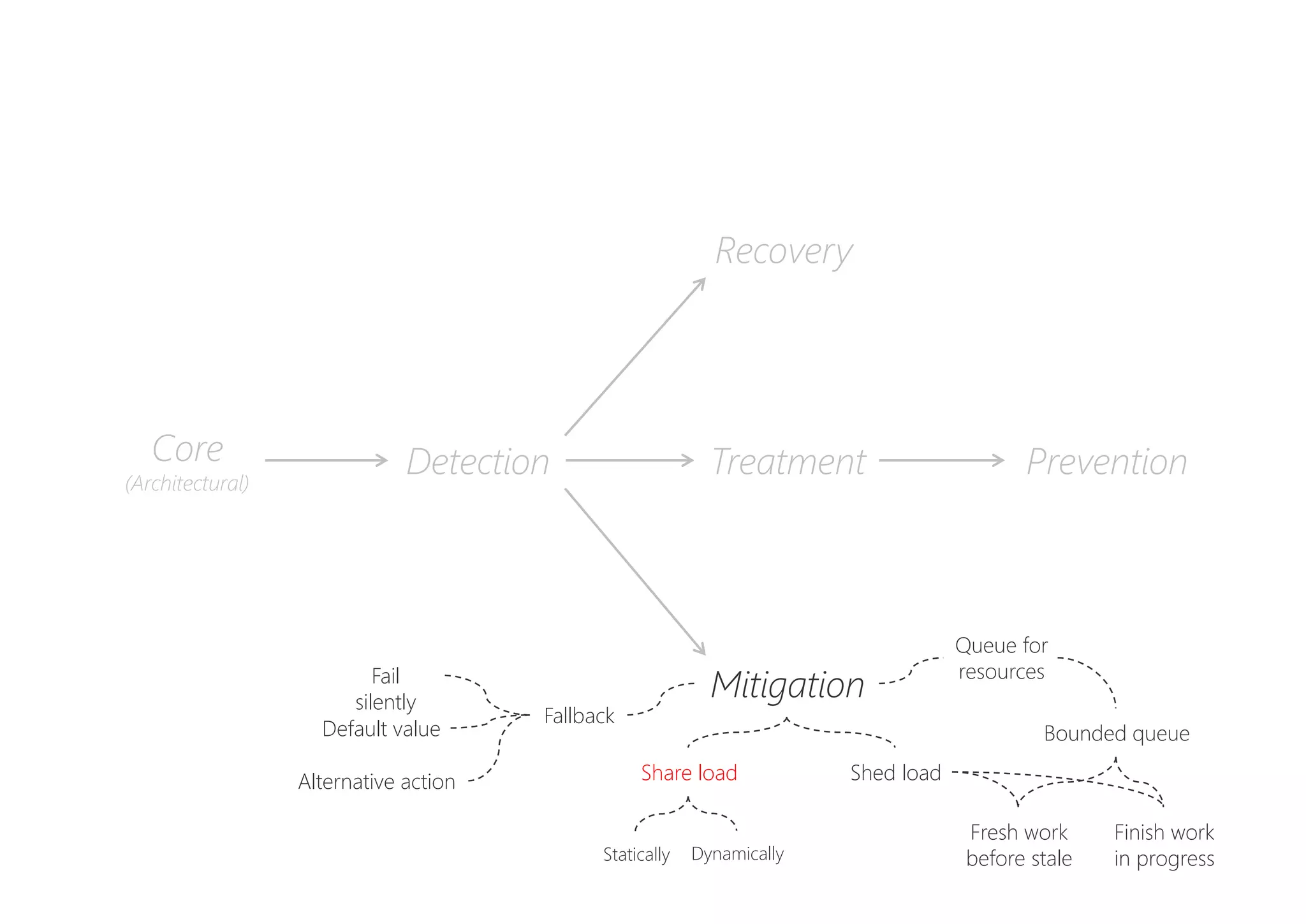

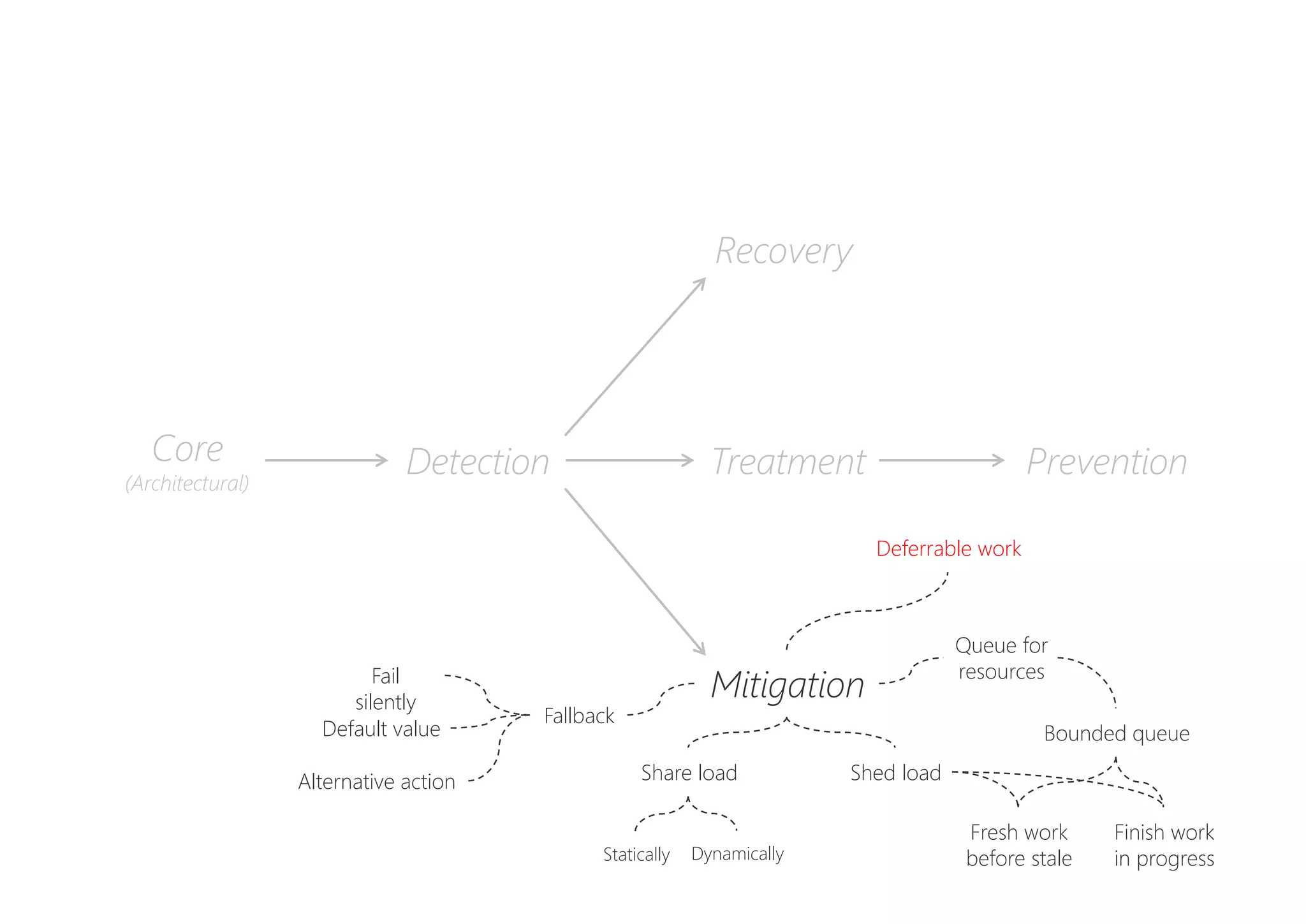

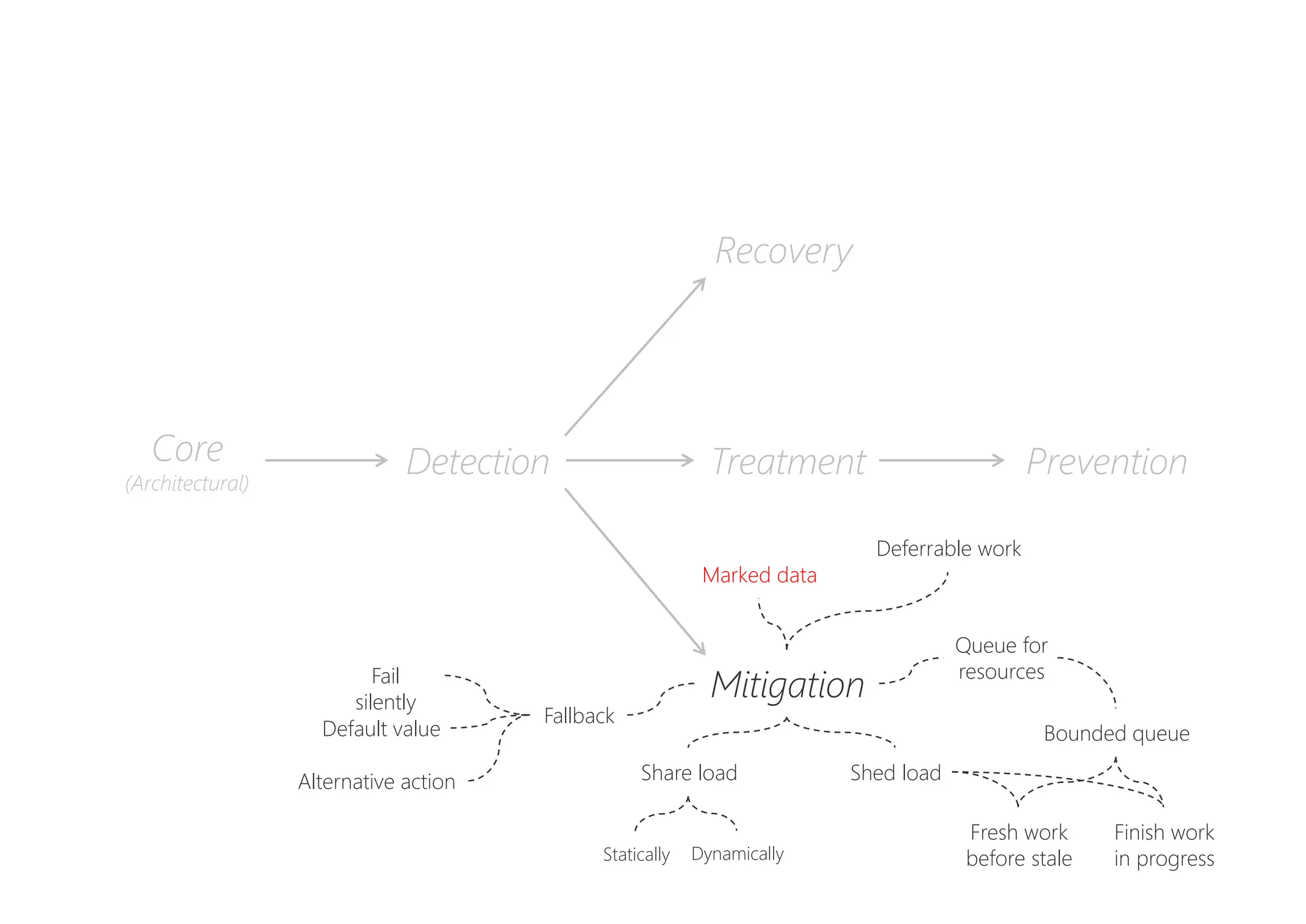

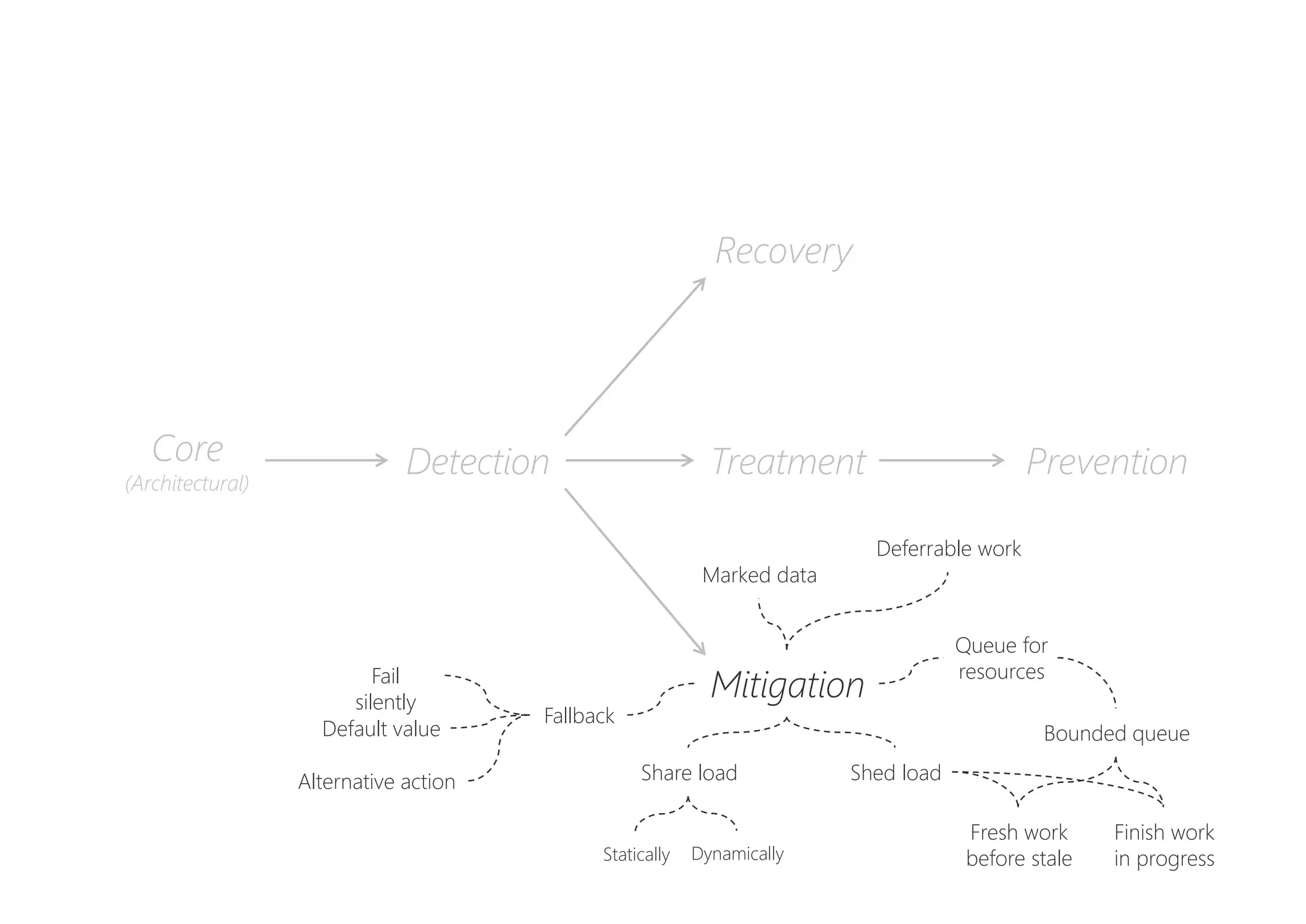


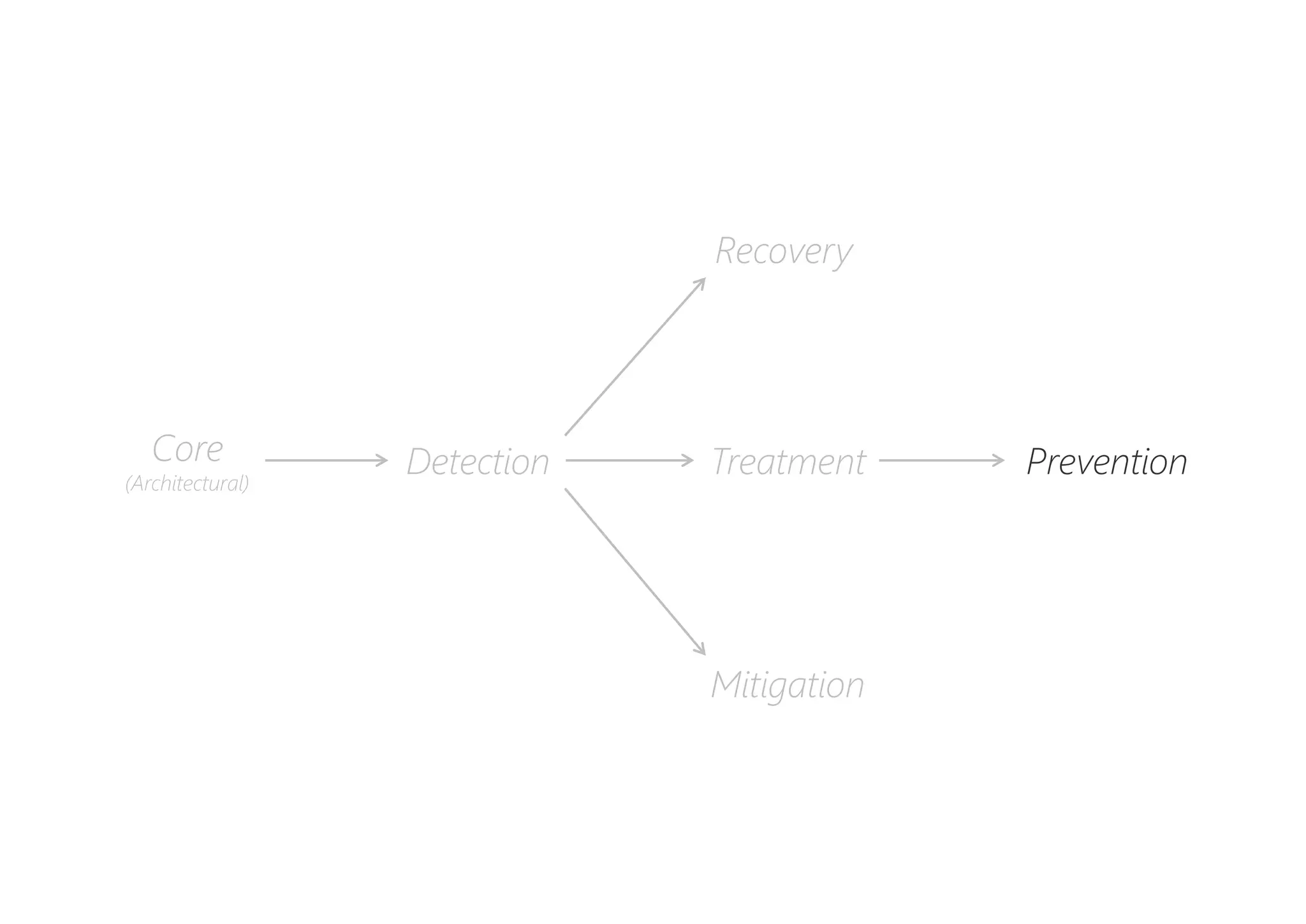


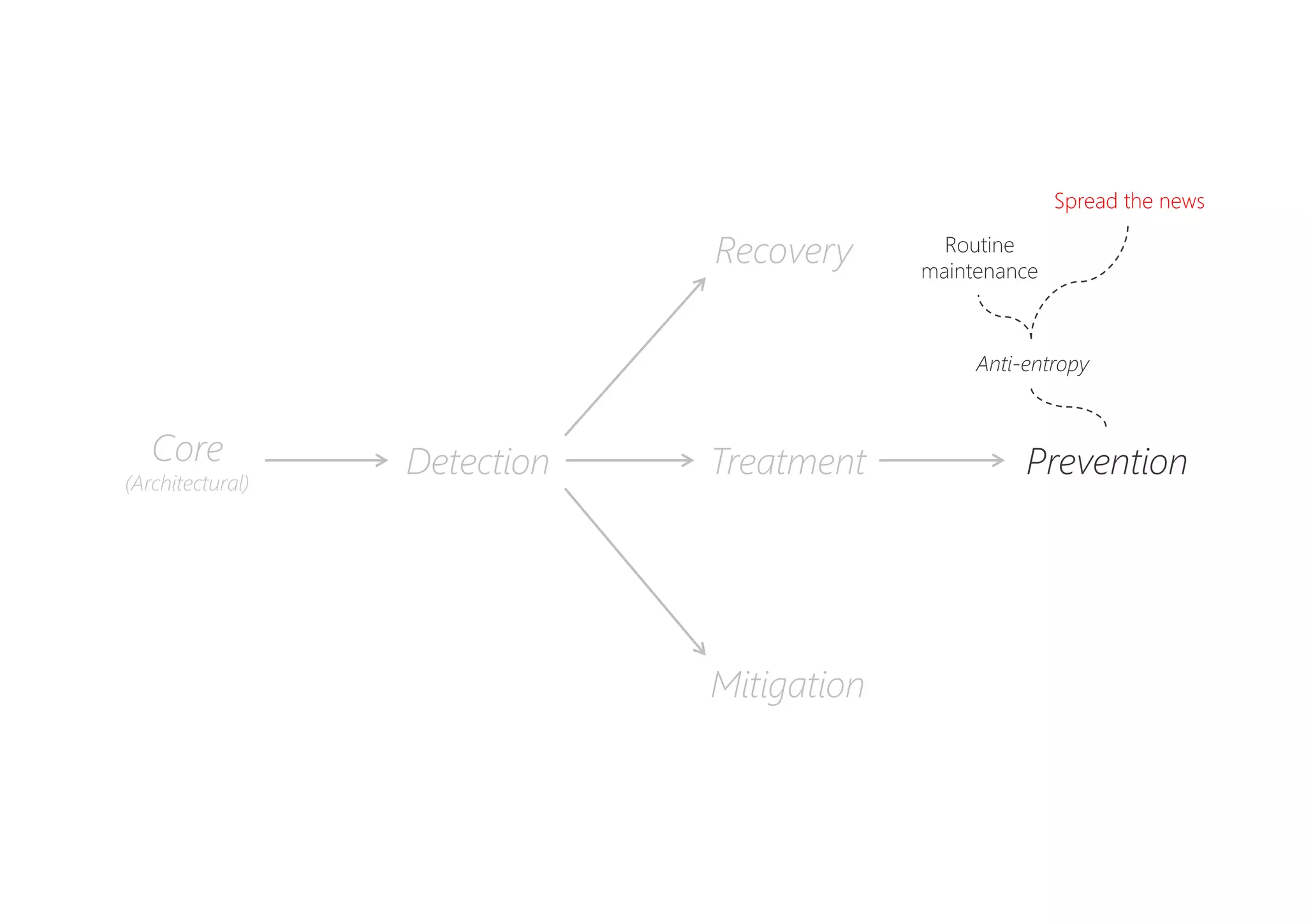



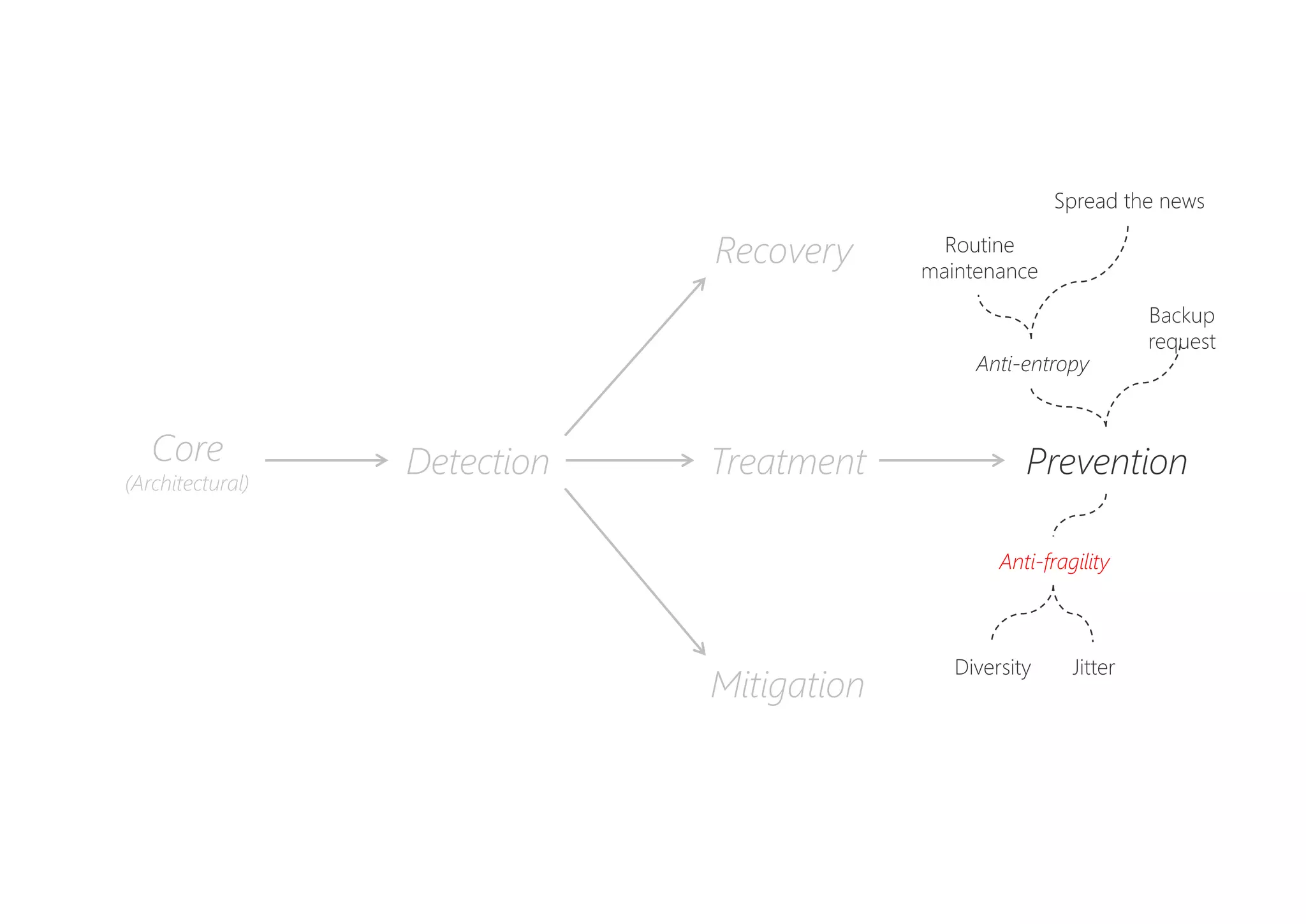







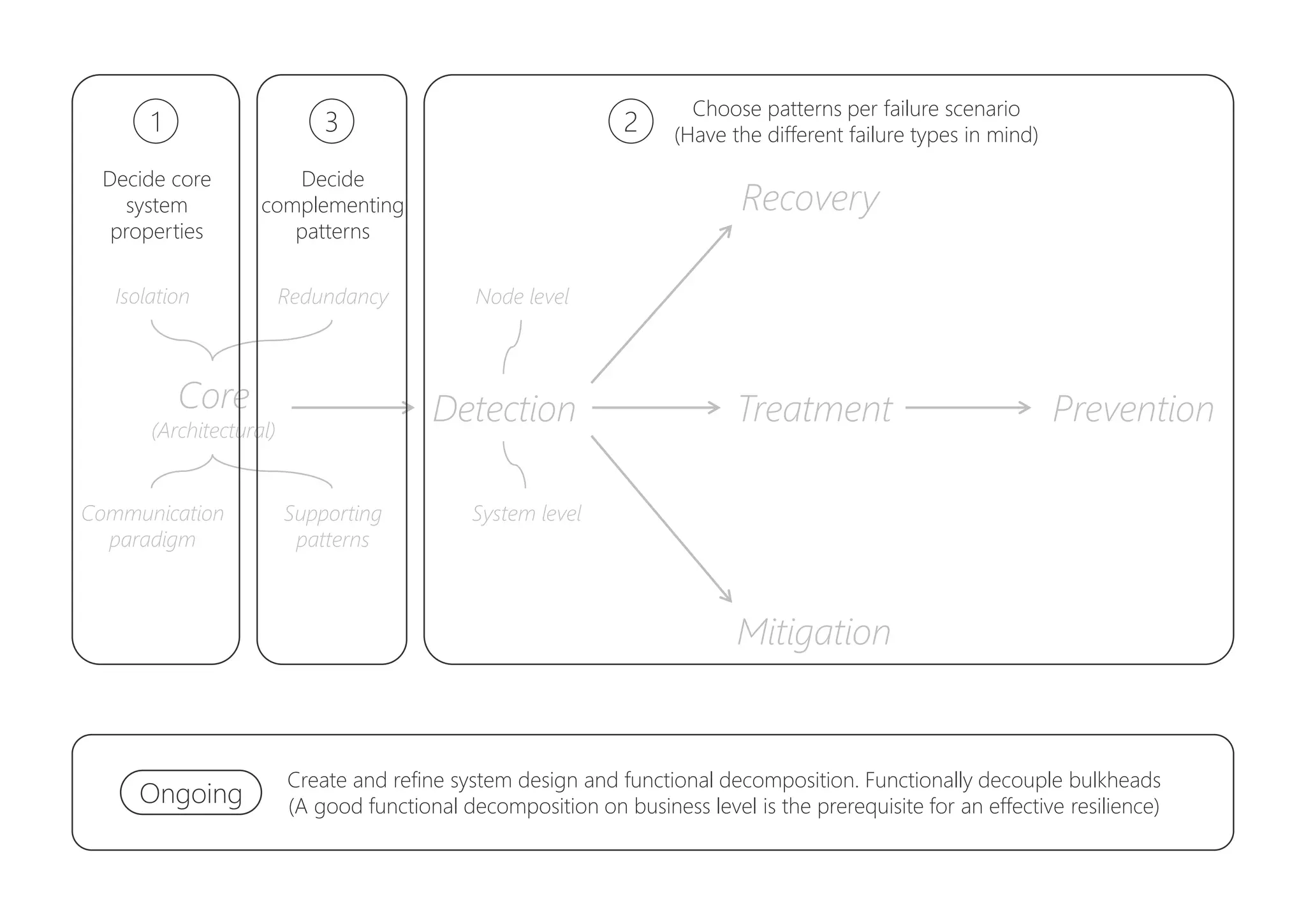
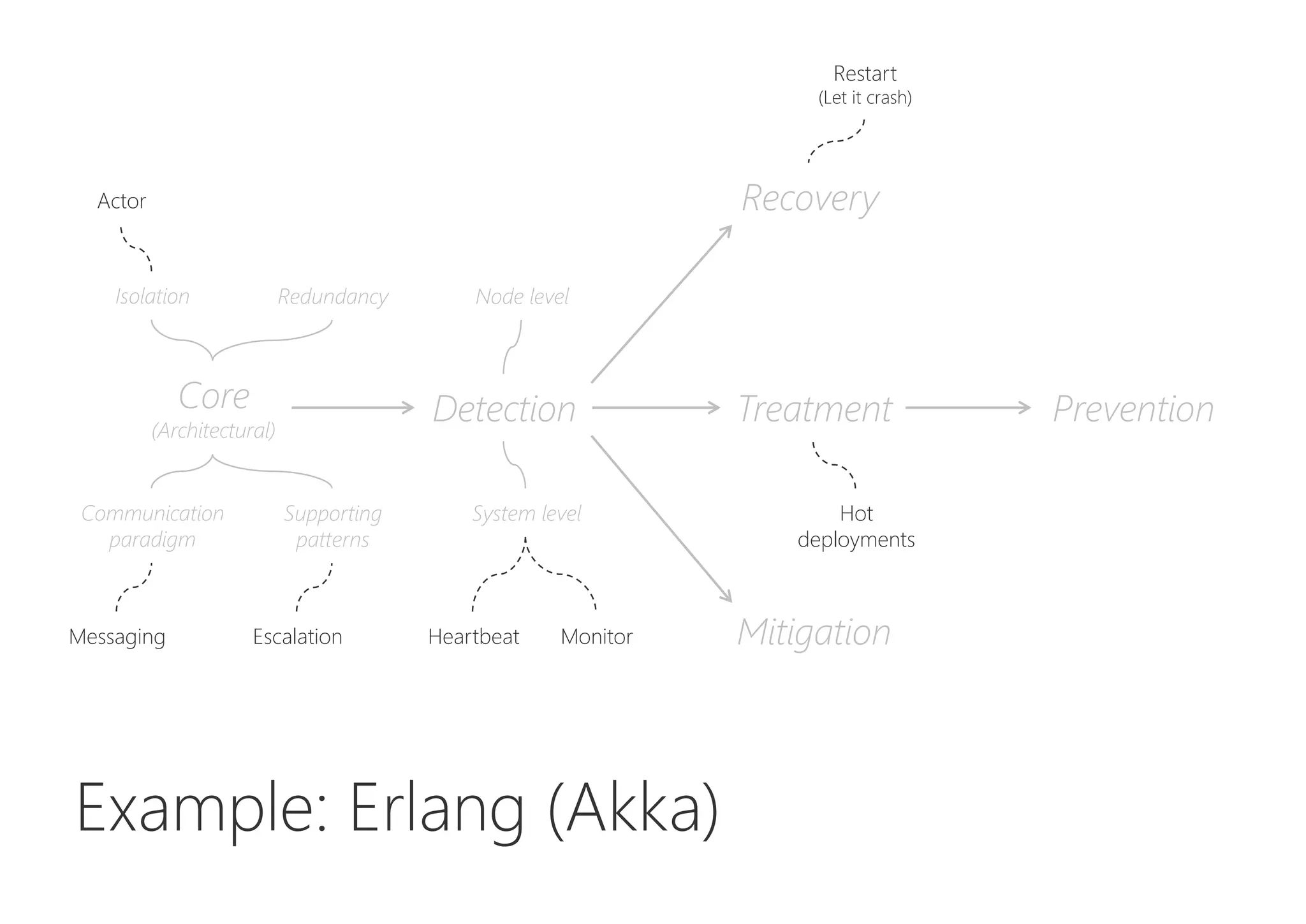
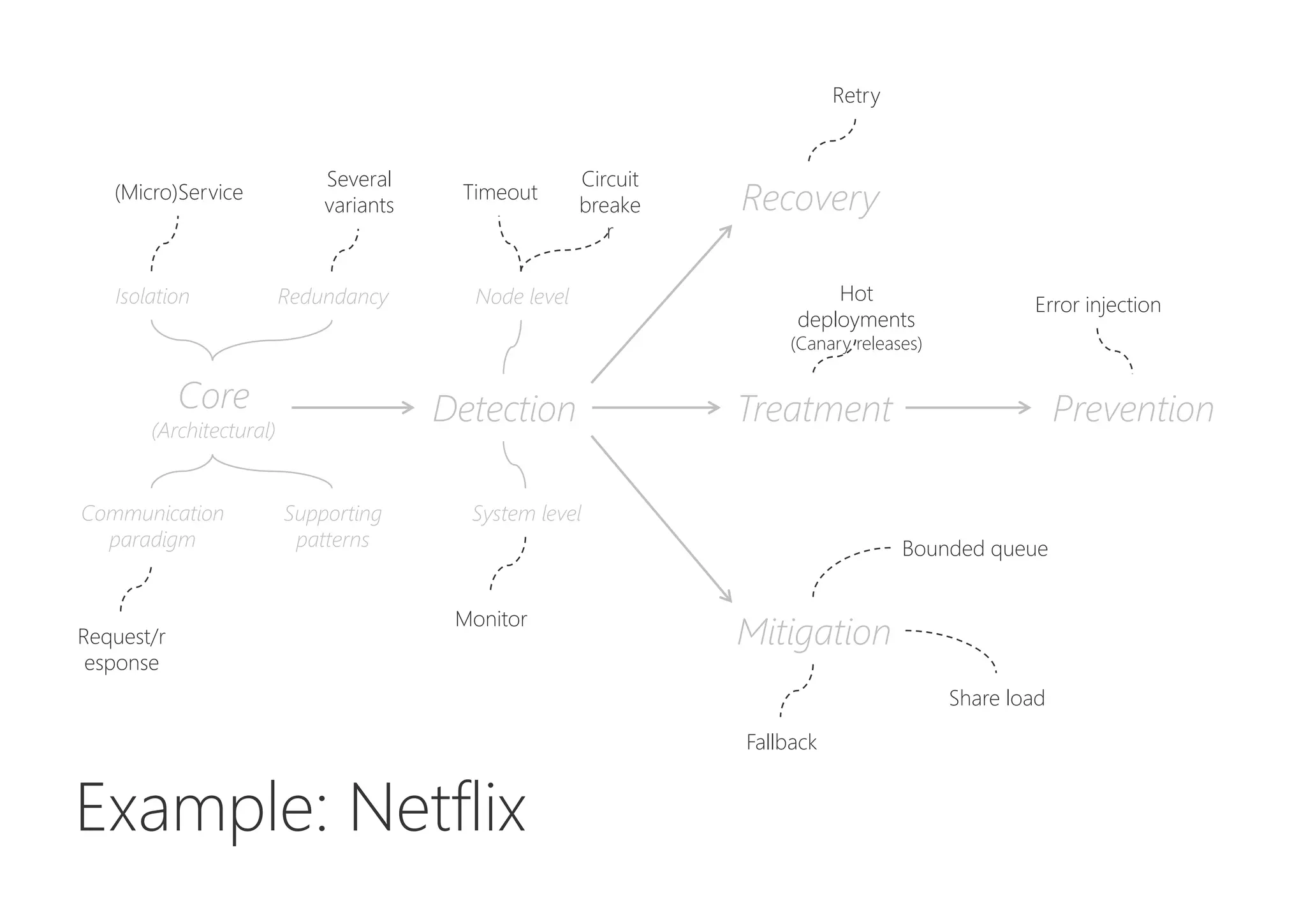







The document discusses resilience in software systems, emphasizing that failures are common in complex distributed environments and should be embraced rather than avoided. It introduces various resilience patterns and strategies, such as redundancy, failover, and dynamic load sharing, as well as methods to recover from and mitigate failures. The text aims to provide a comprehensive understanding of how to design resilient systems through thoughtful architectural decisions and pattern selection.




































![[WSO2Con EU 2017] Resilience Patterns with Ballerina](https://cdn.slidesharecdn.com/ss_thumbnails/myteul0aqxm9m9aefn37-signature-25a03a0dd11bea2cb4b5d302614dc9fa369274823e87b86d7bcc419612b27068-poli-171106131830-thumbnail.jpg?width=640&height=640&fit=bounds)
































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















