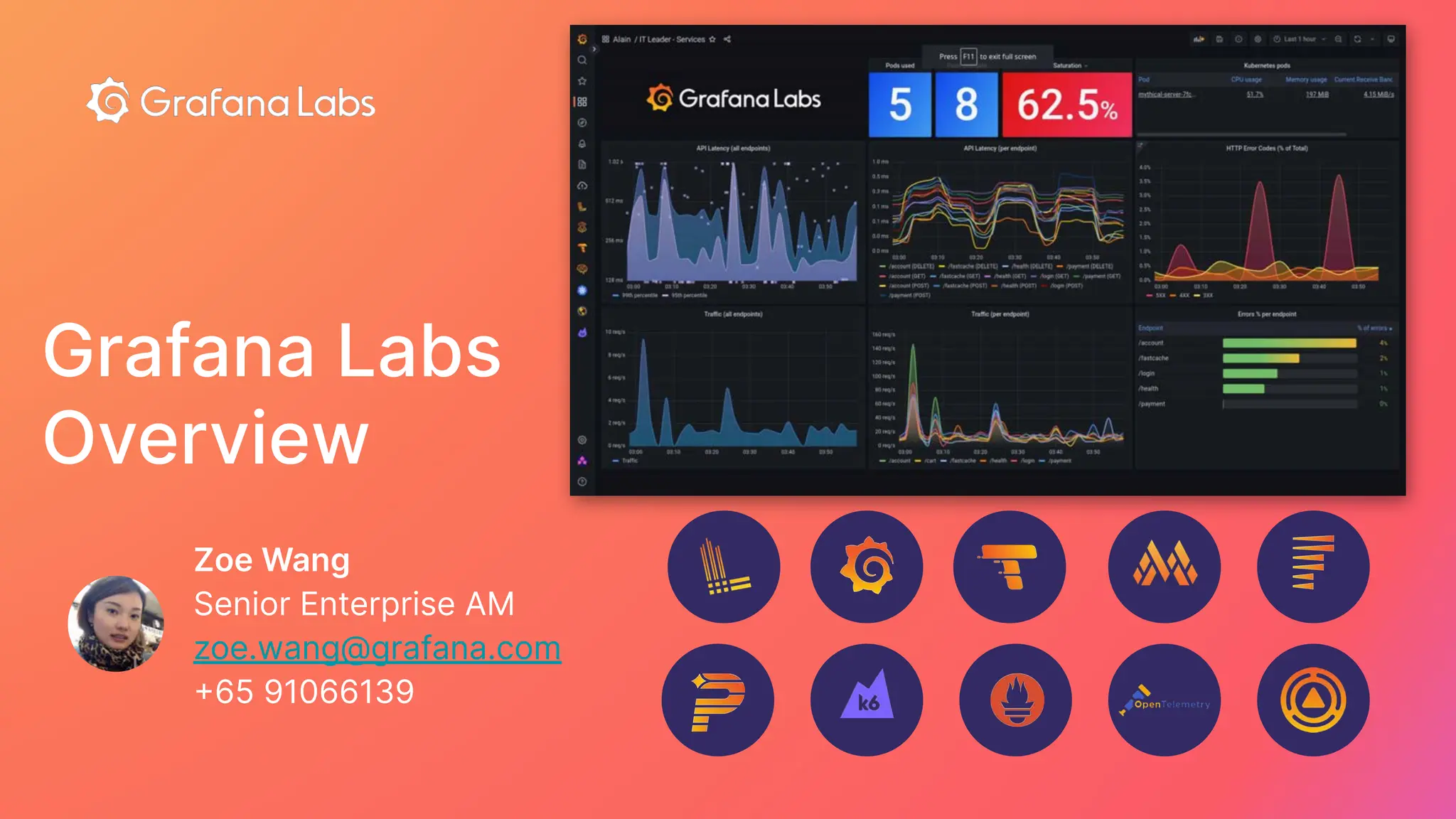
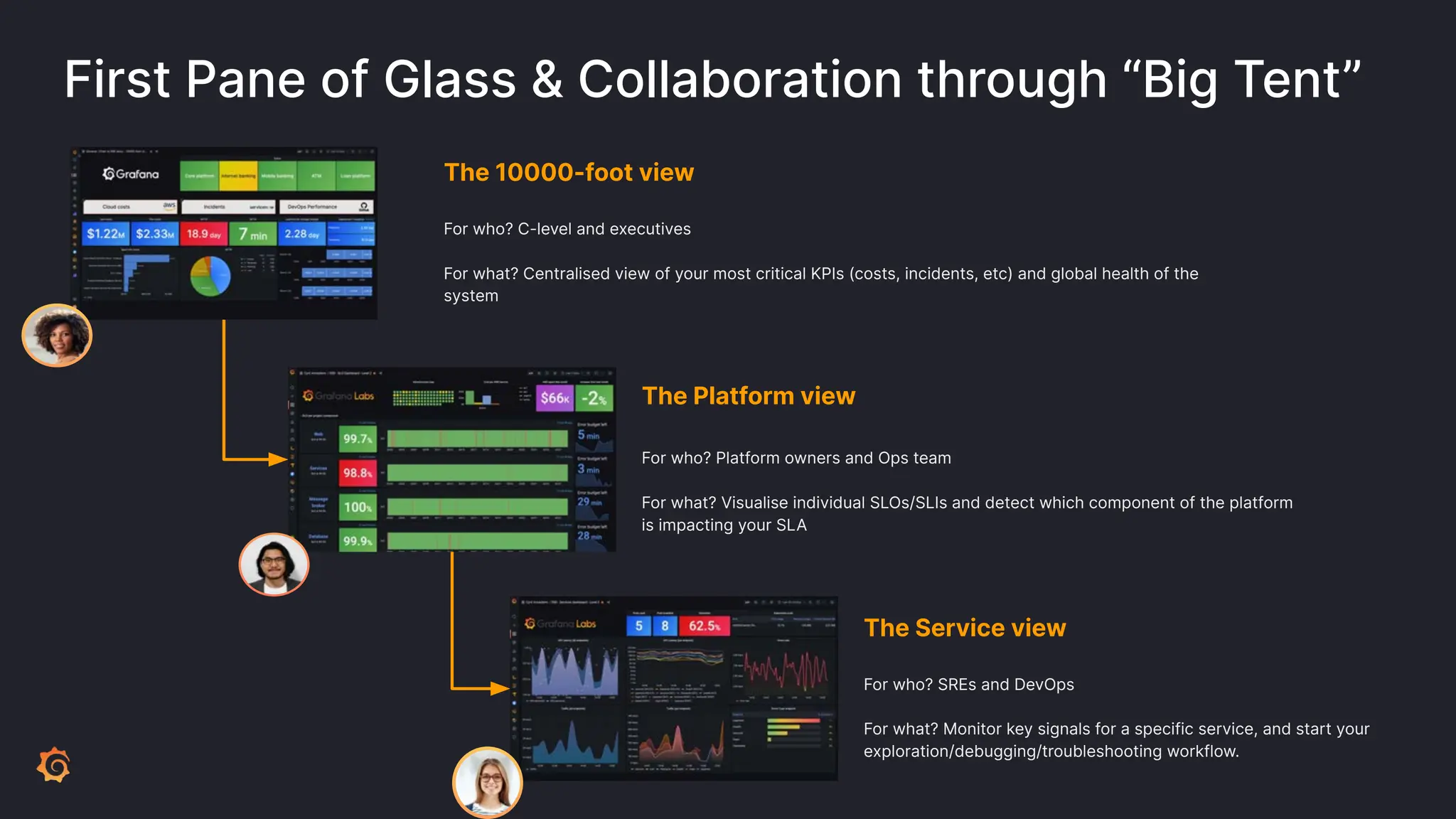
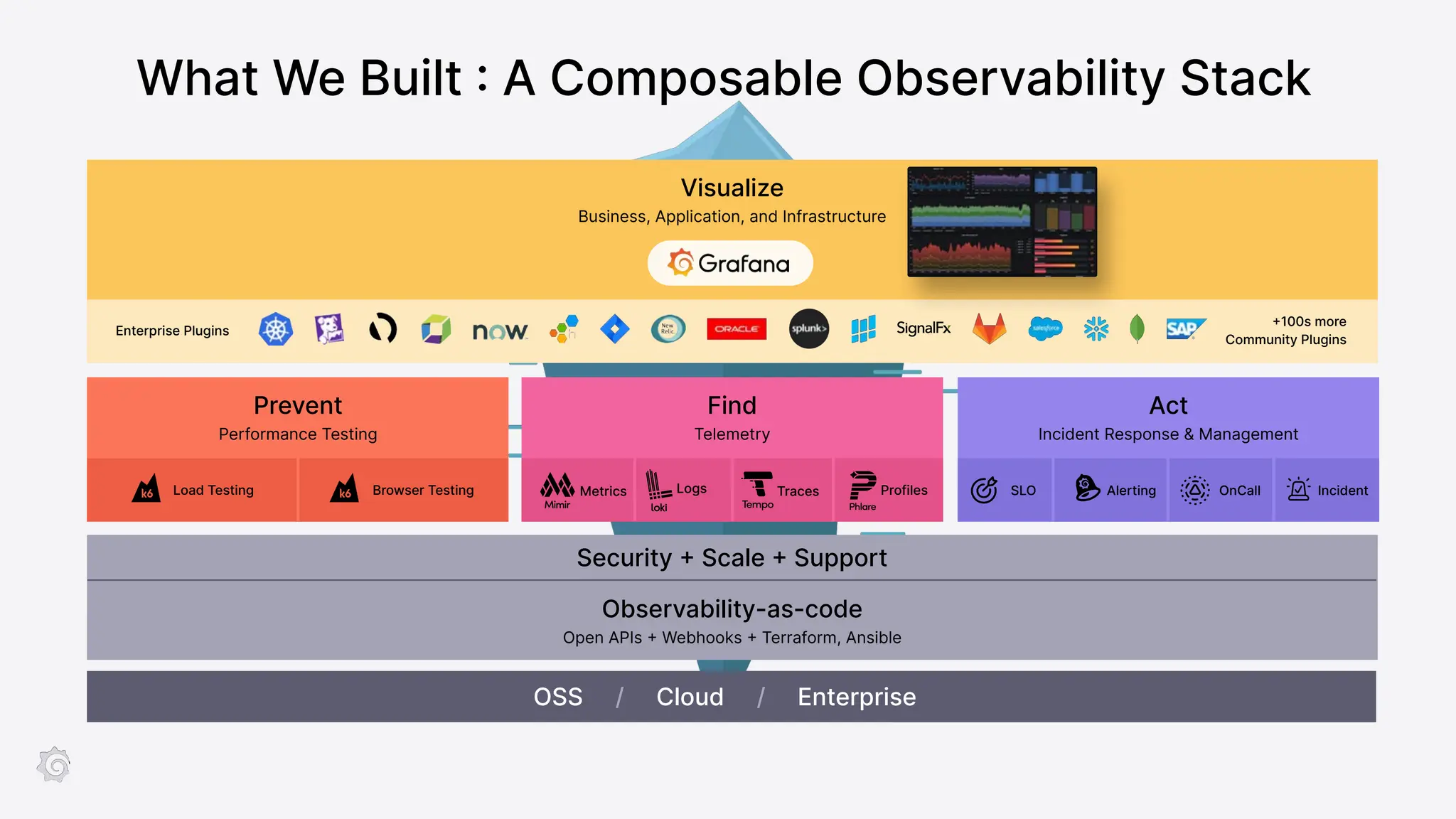
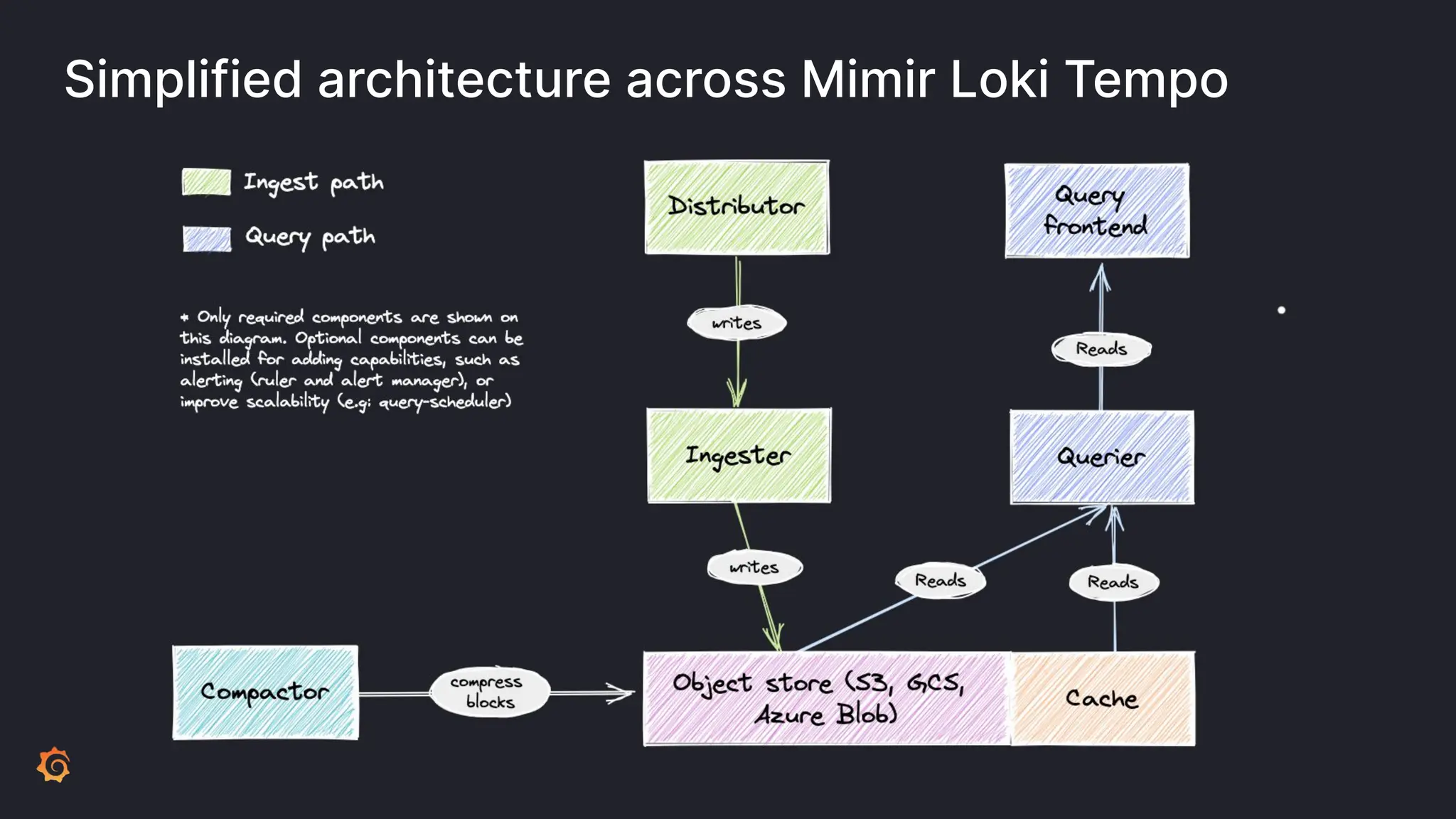
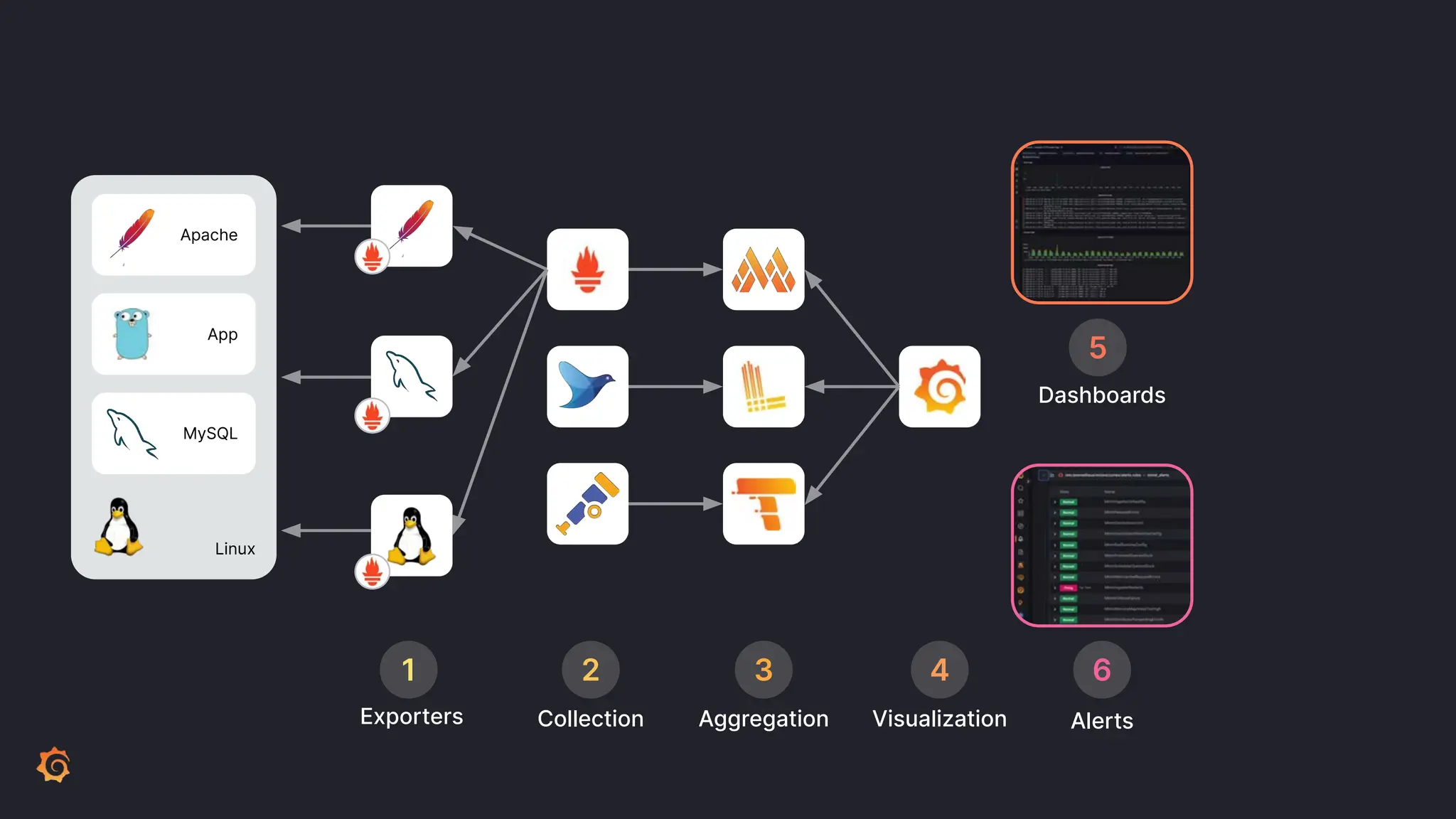
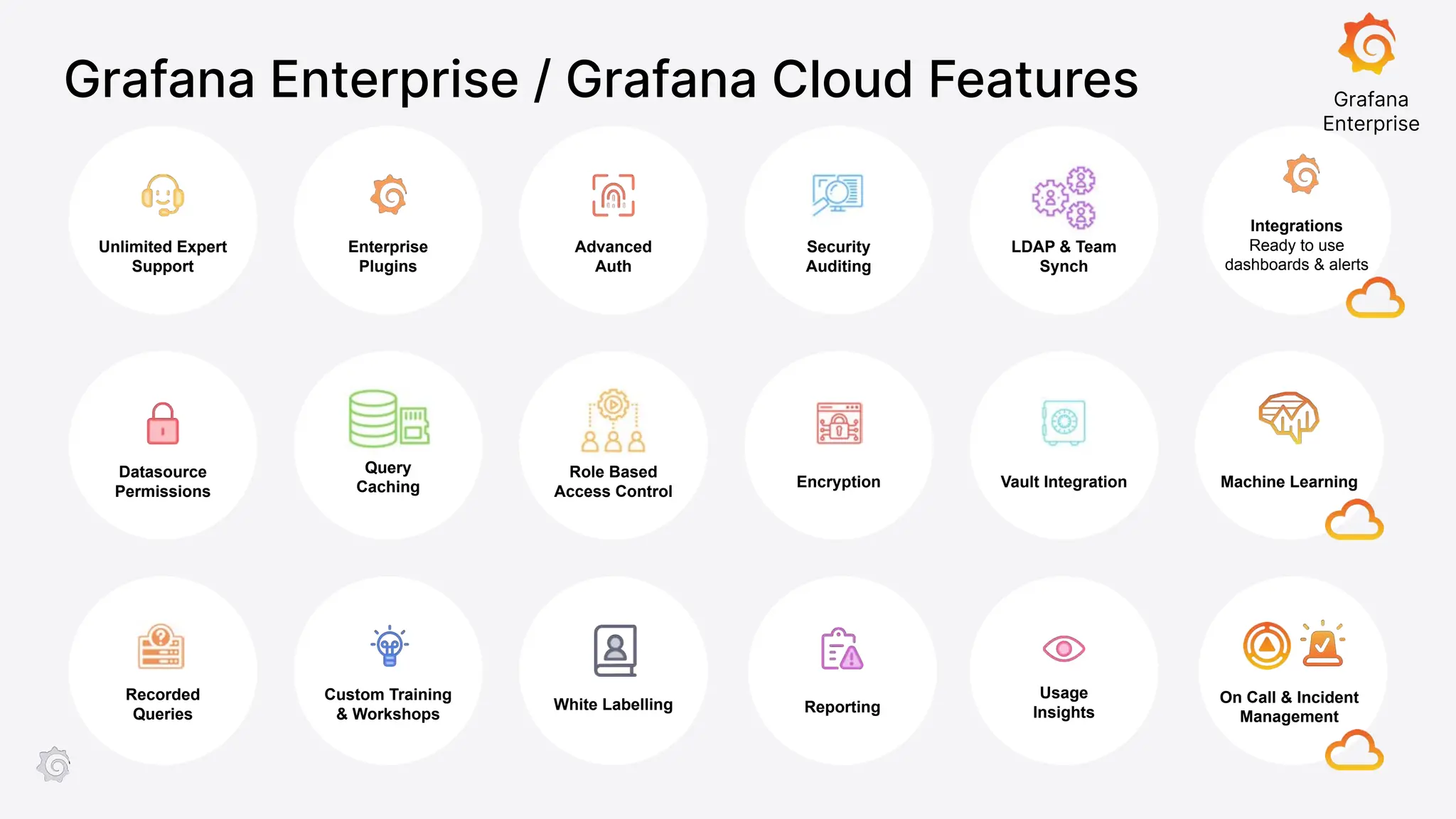
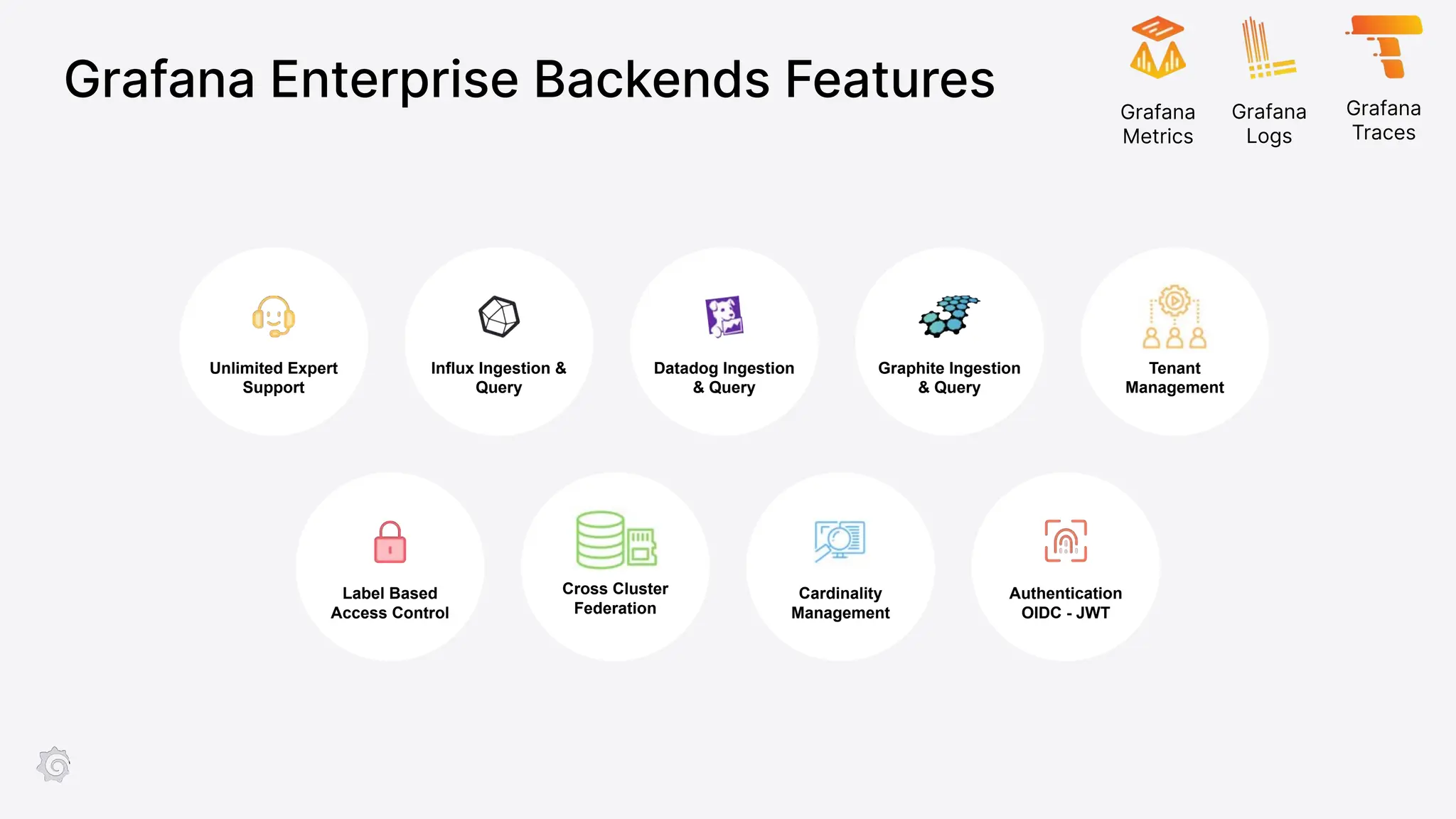
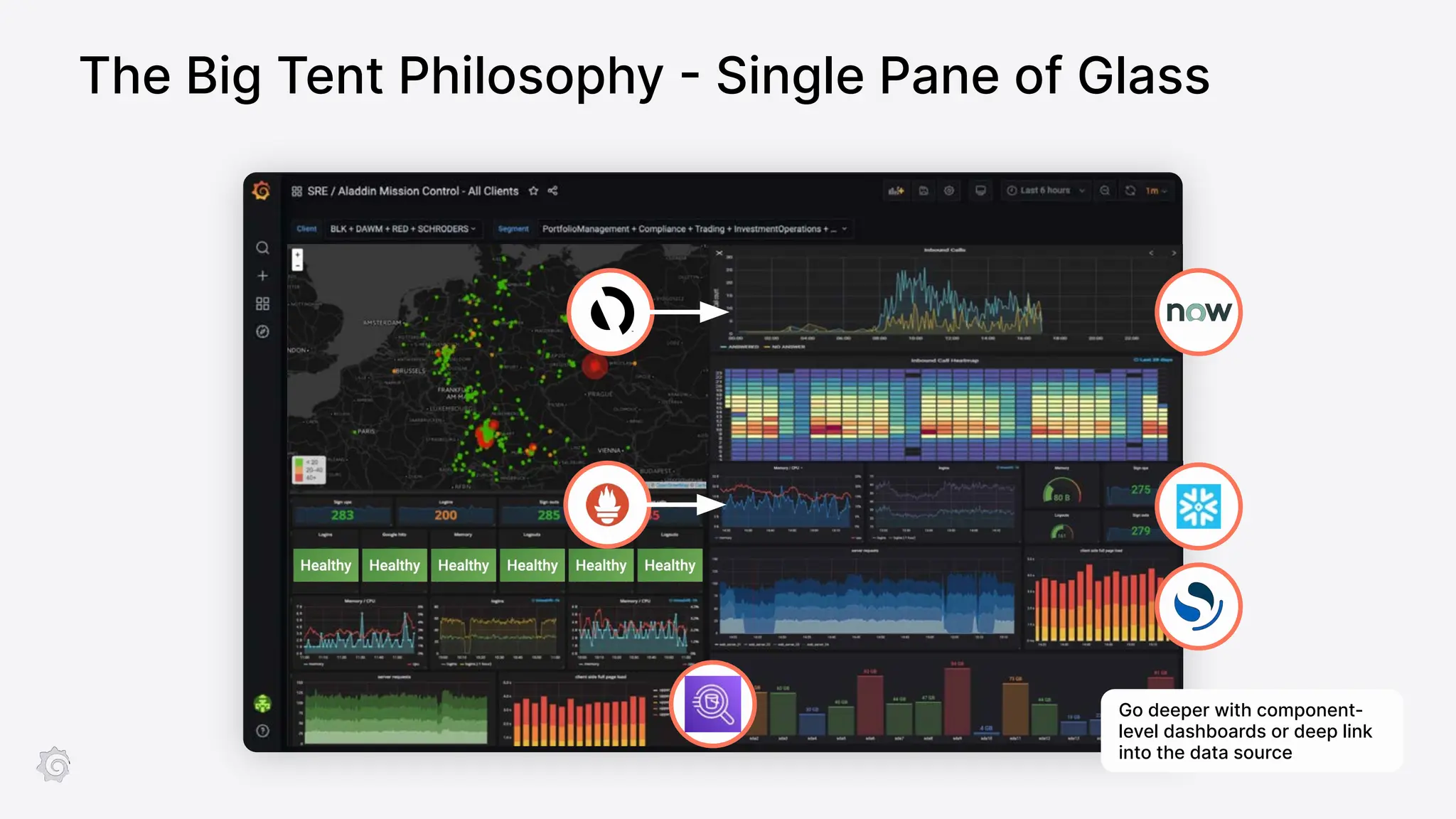
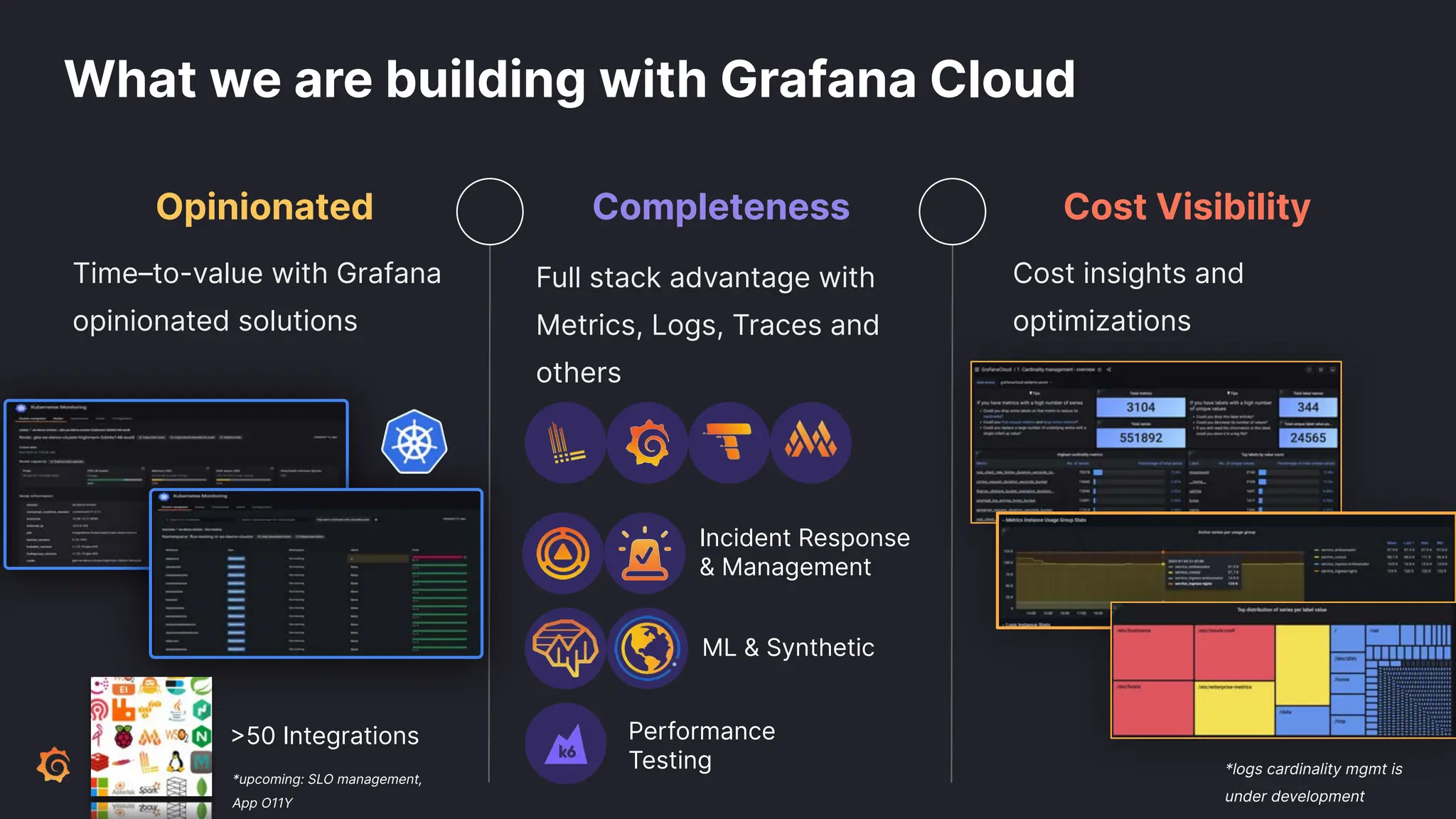
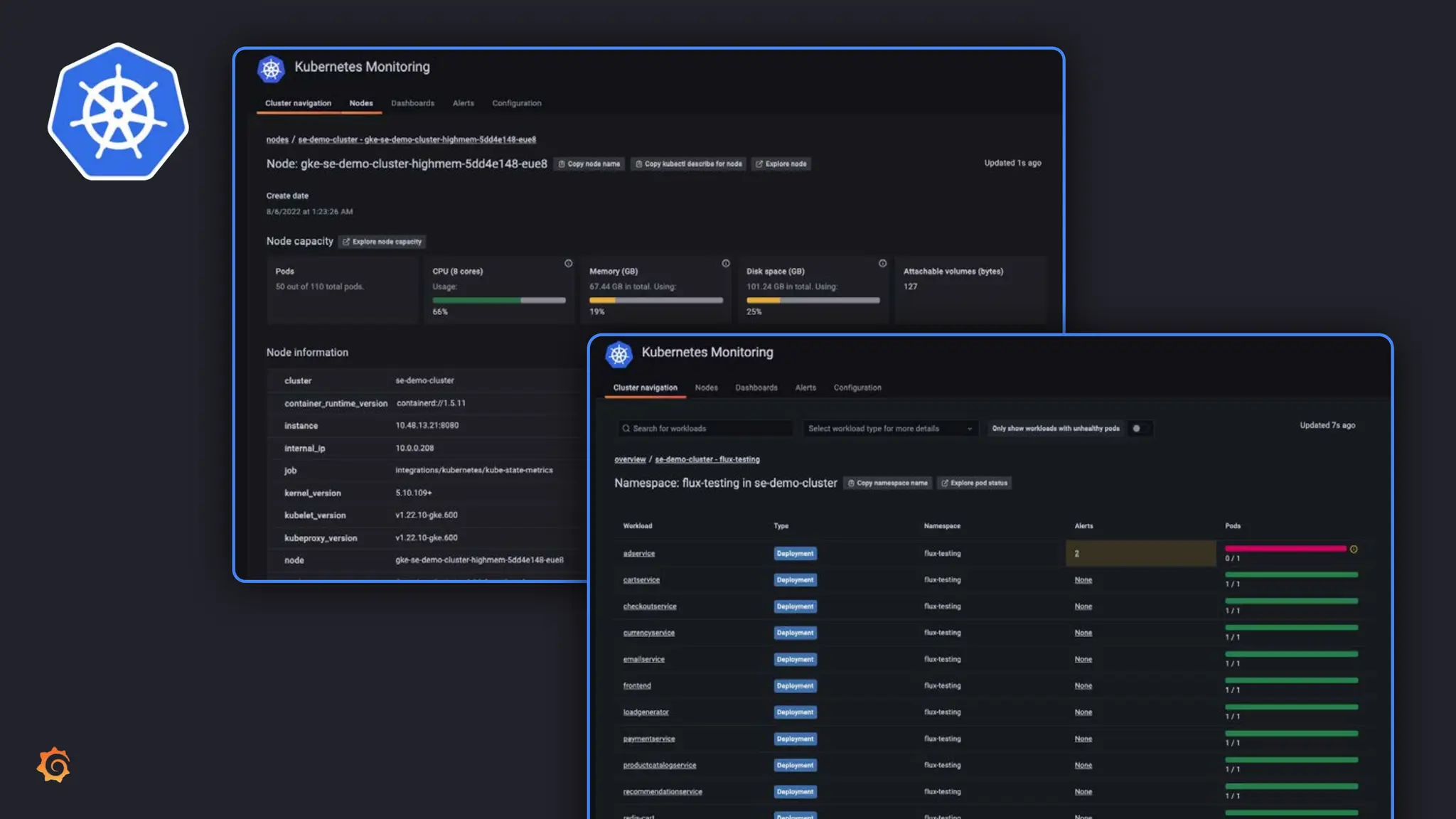
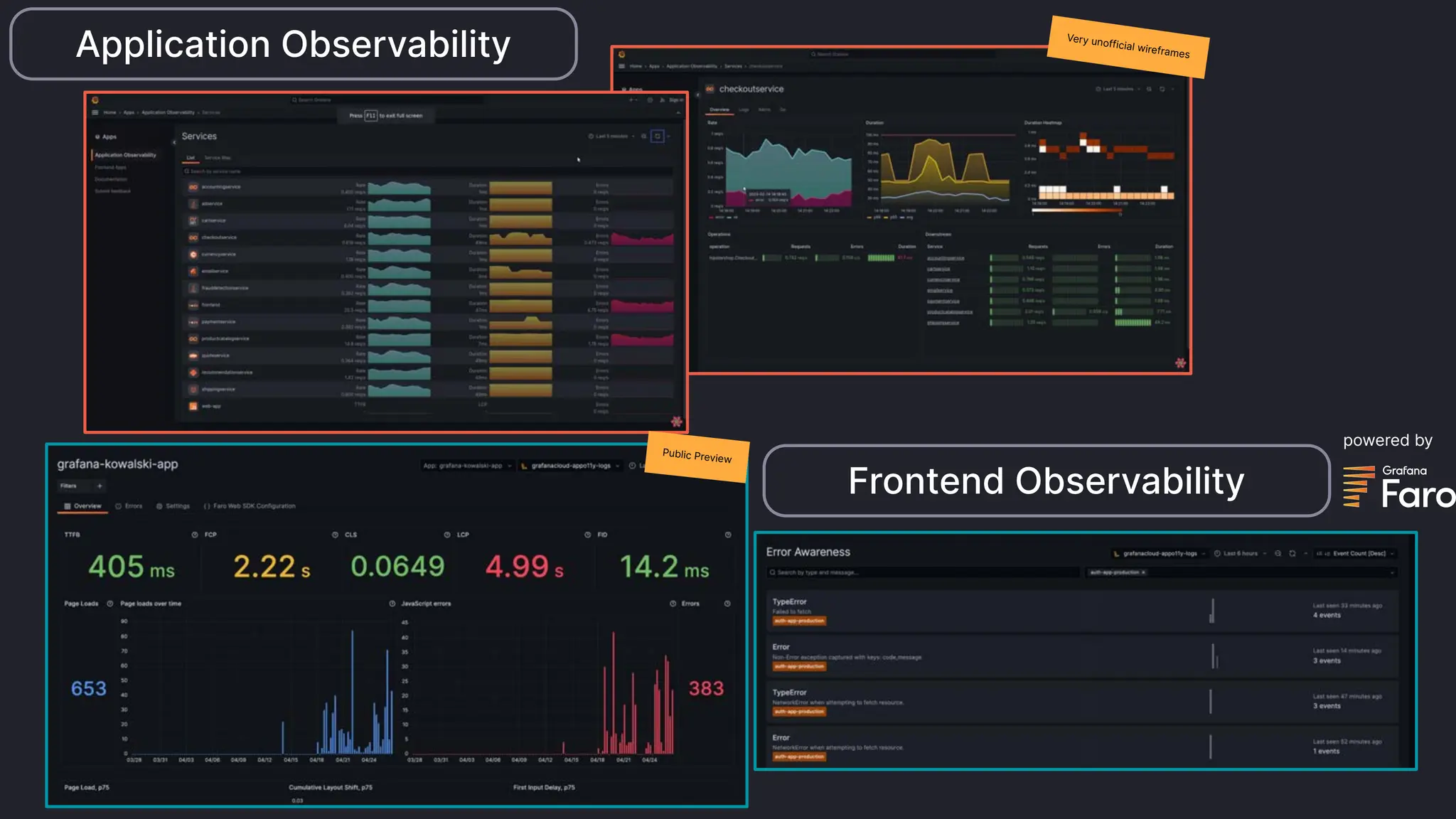
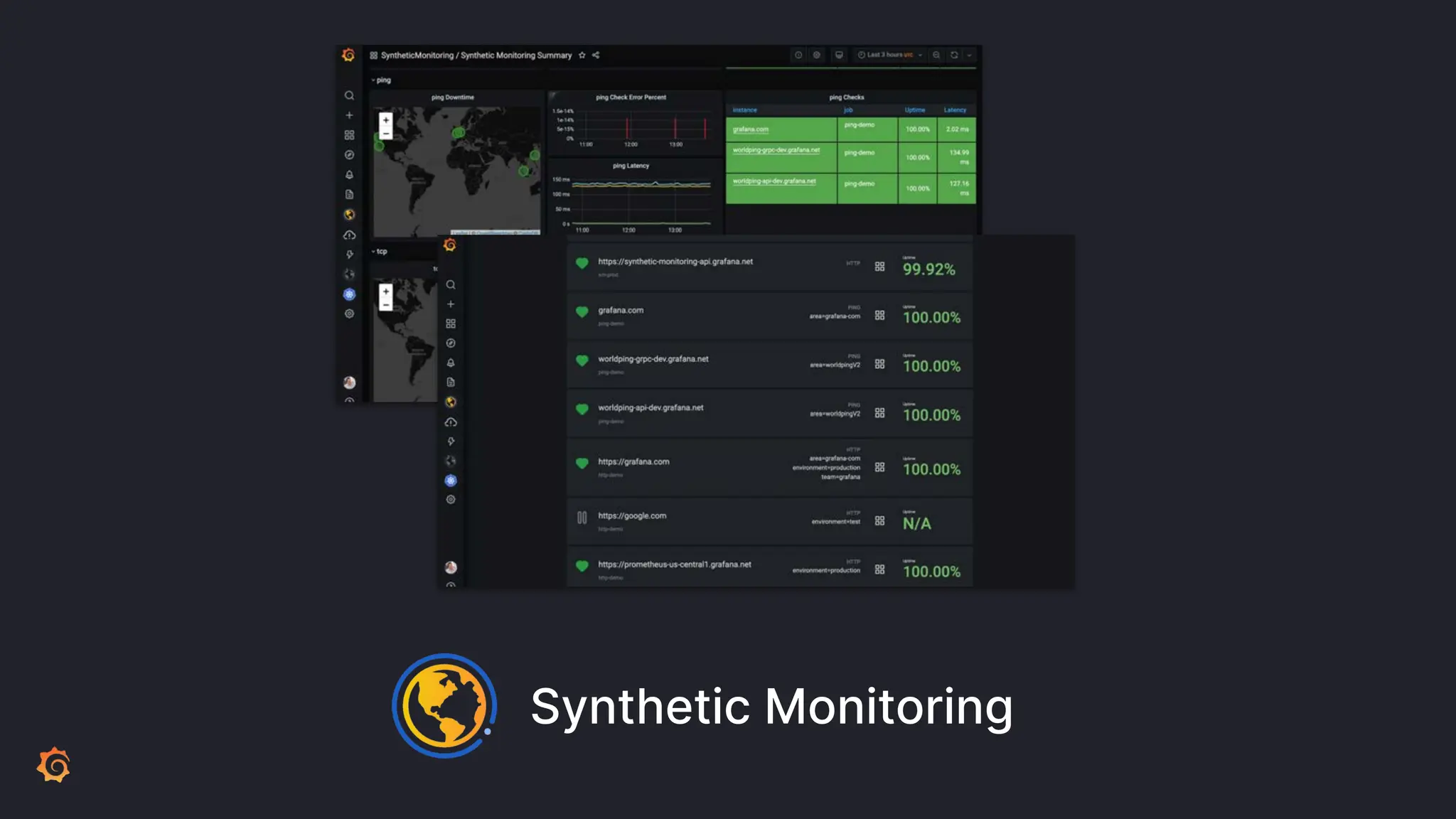
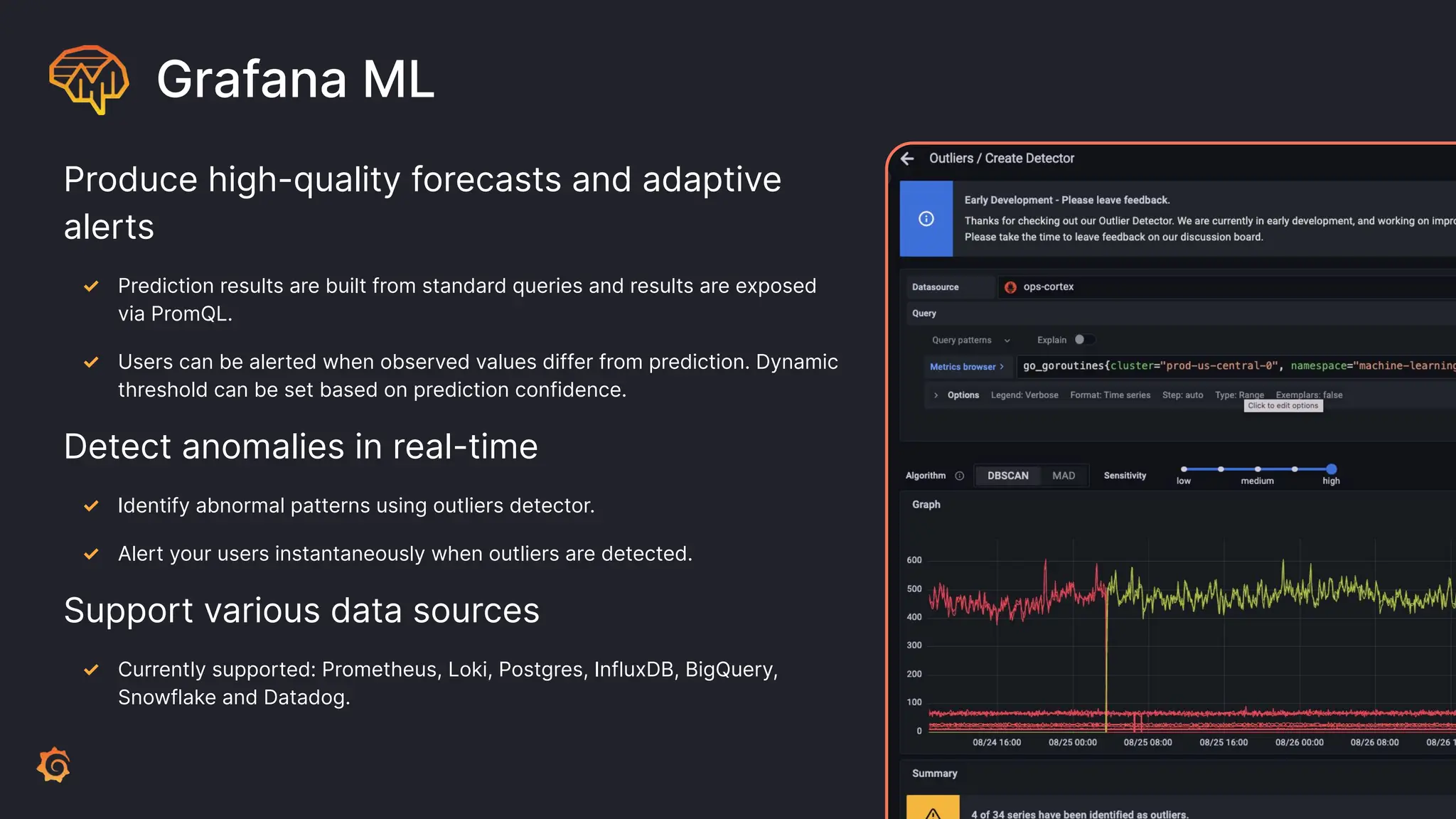
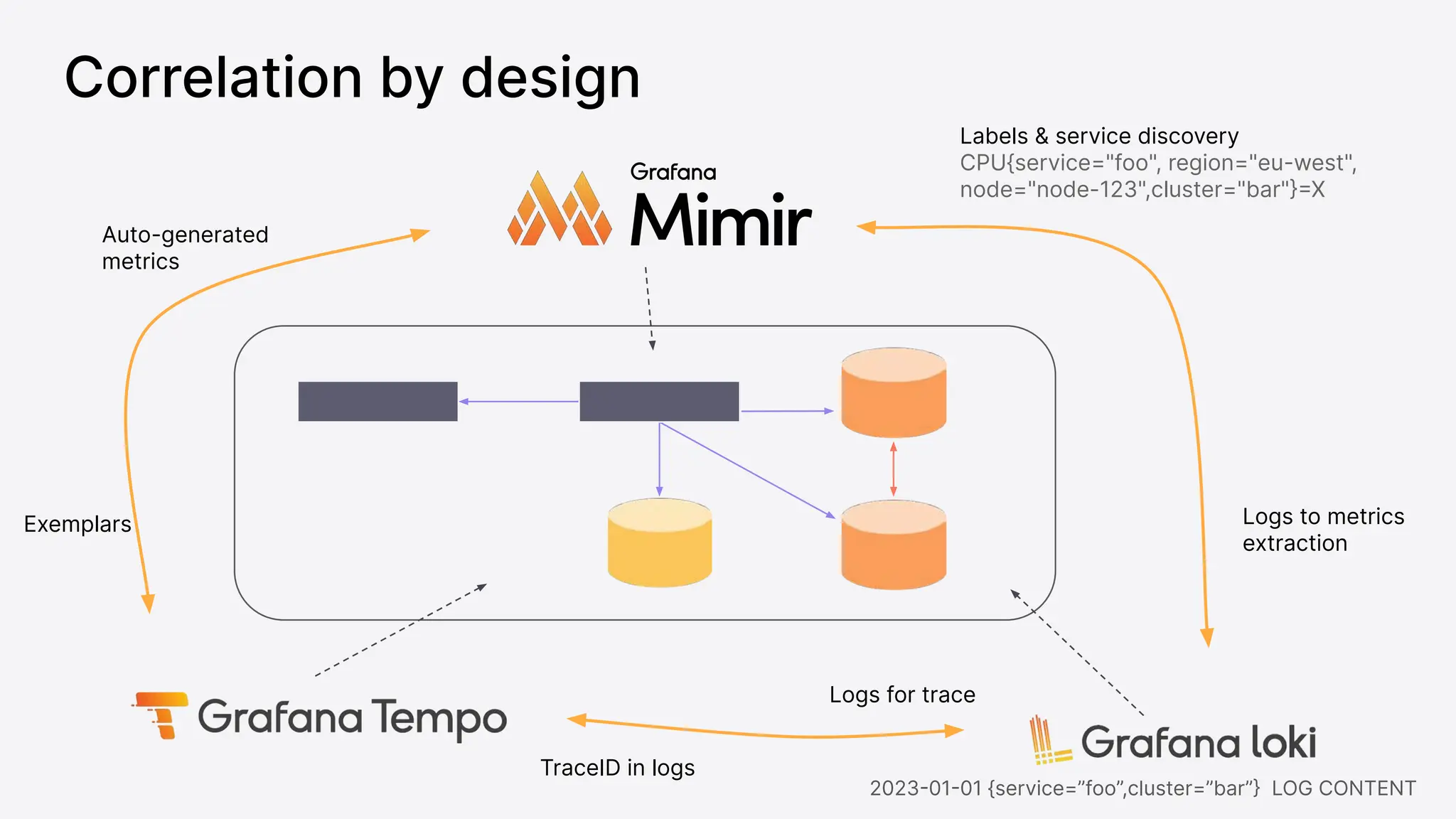
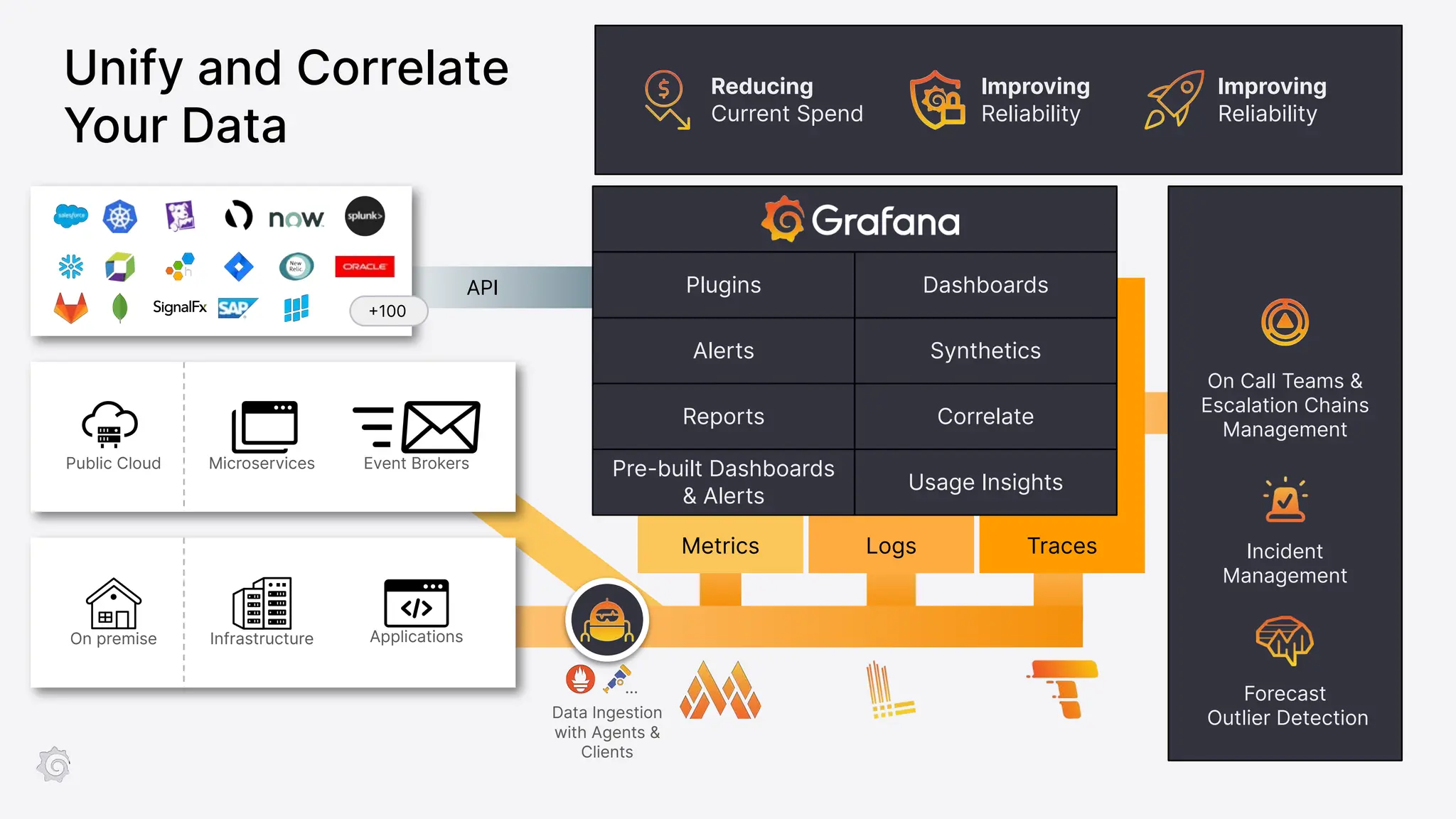
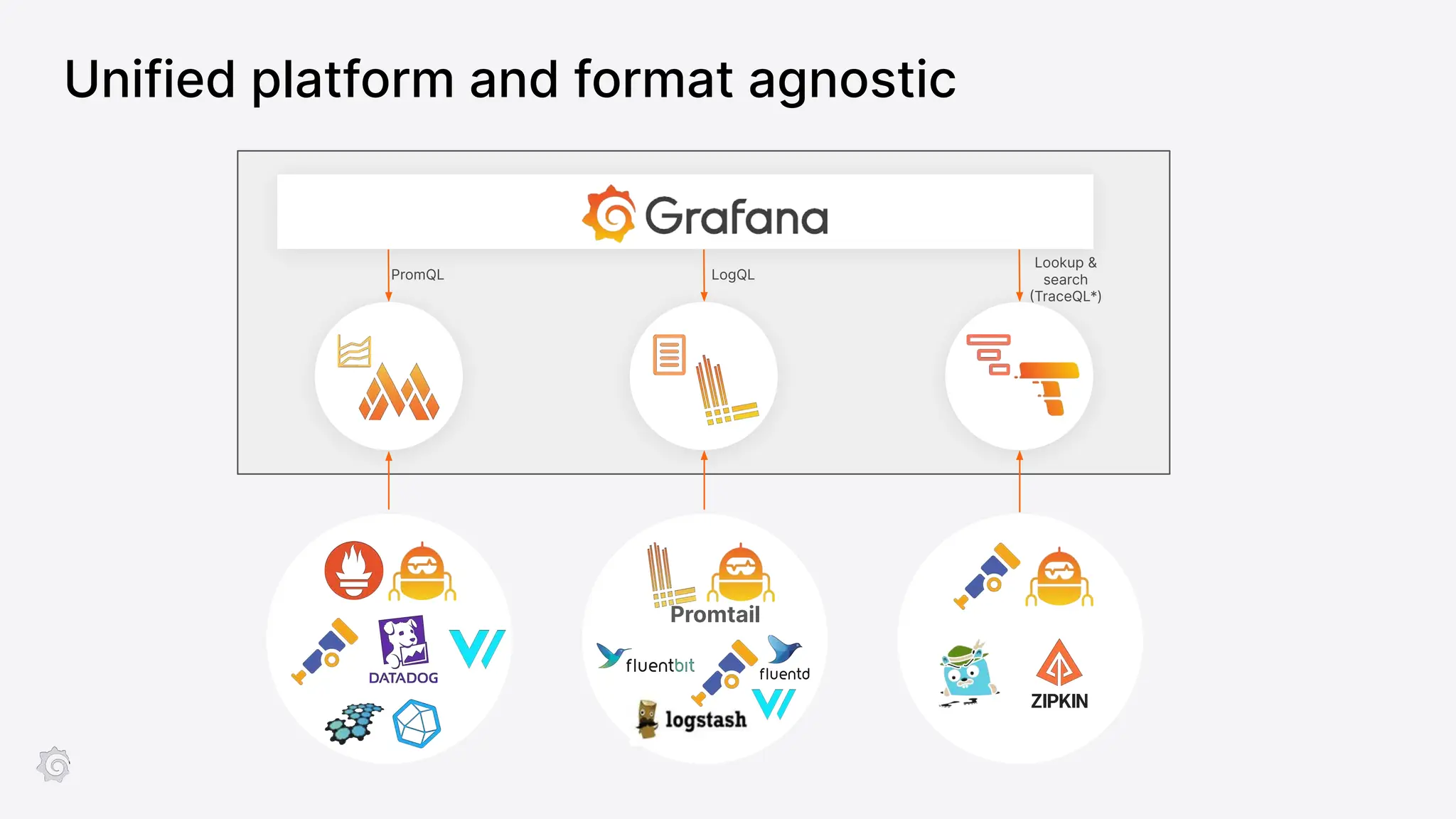
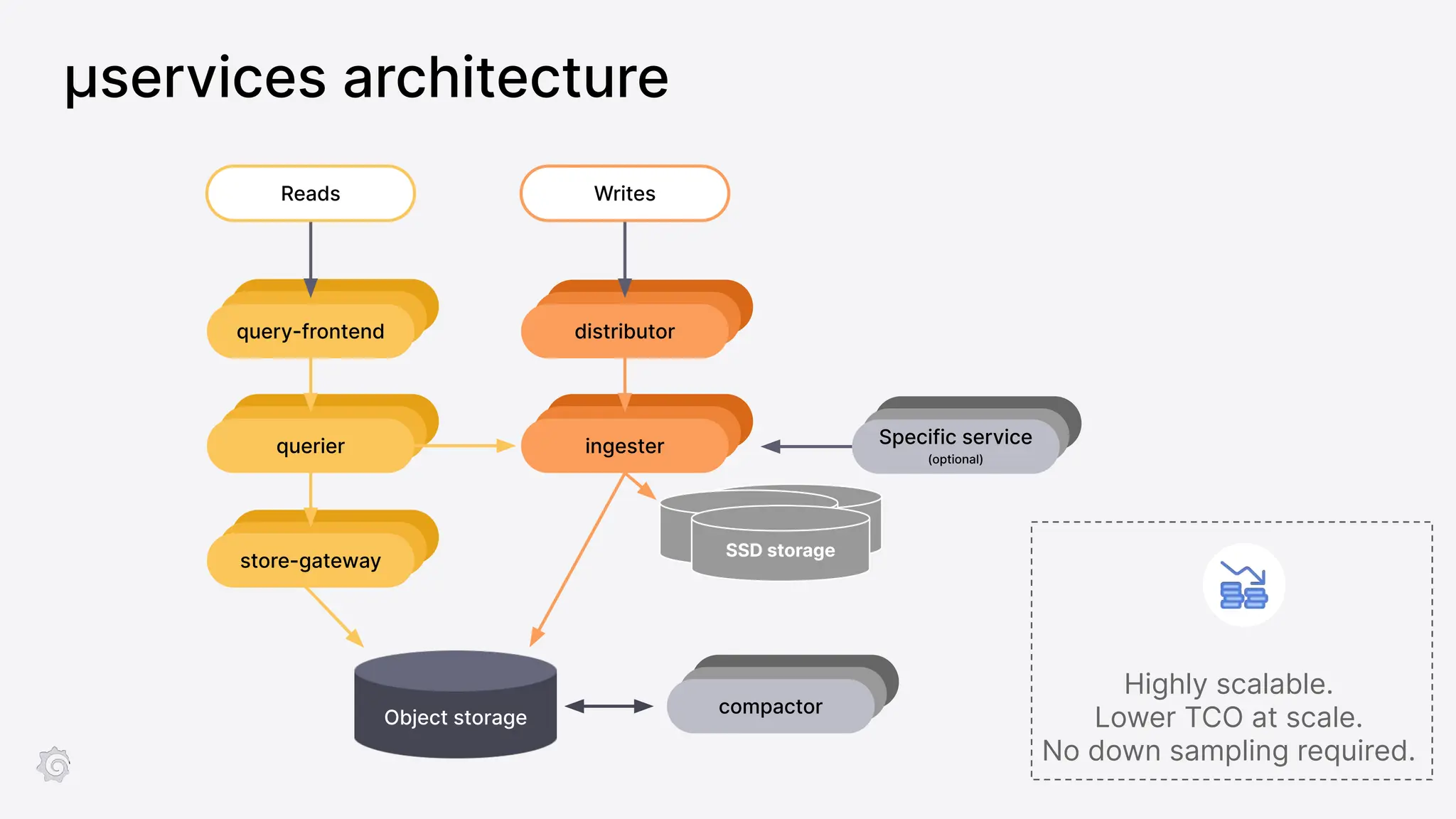
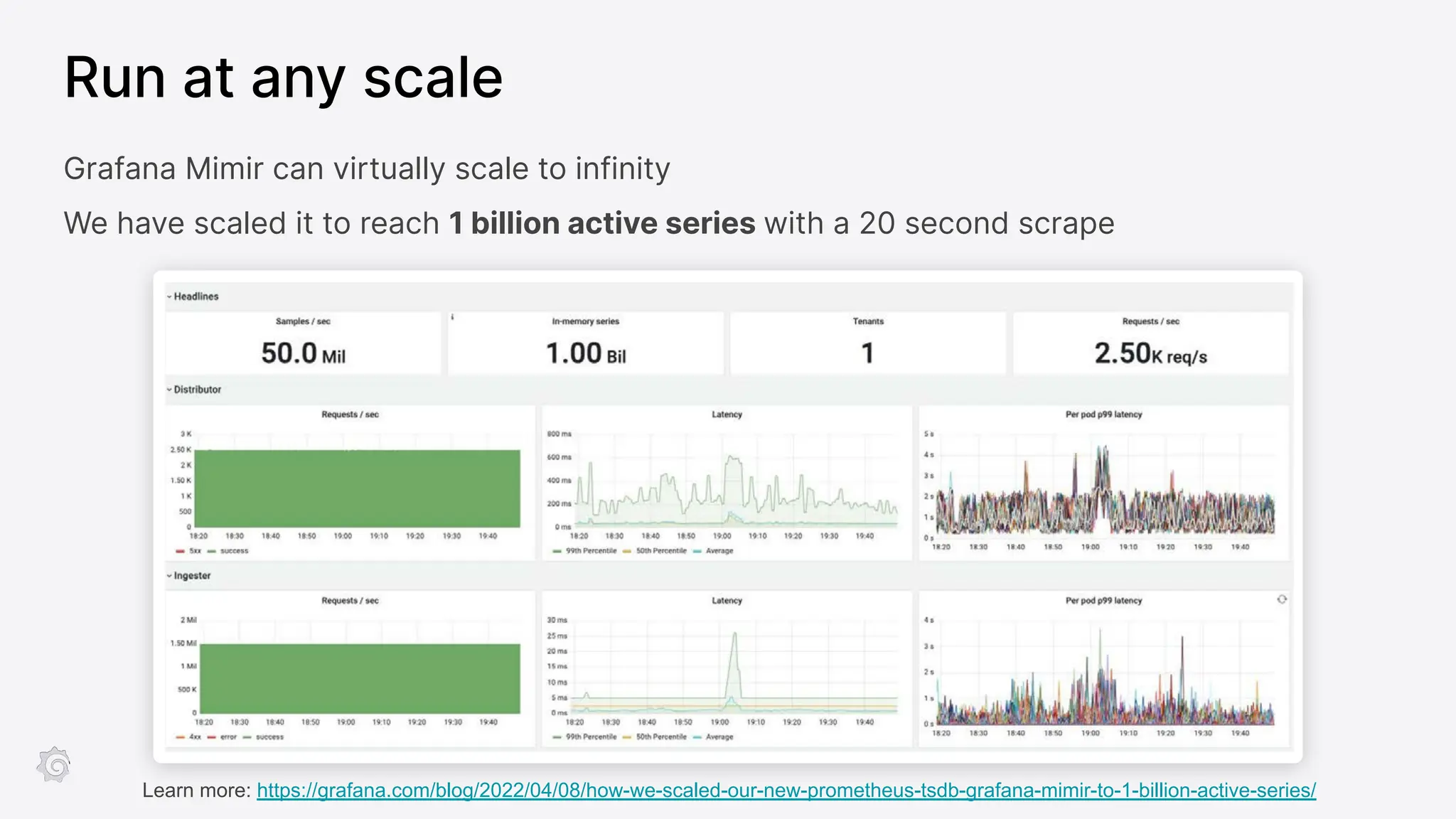
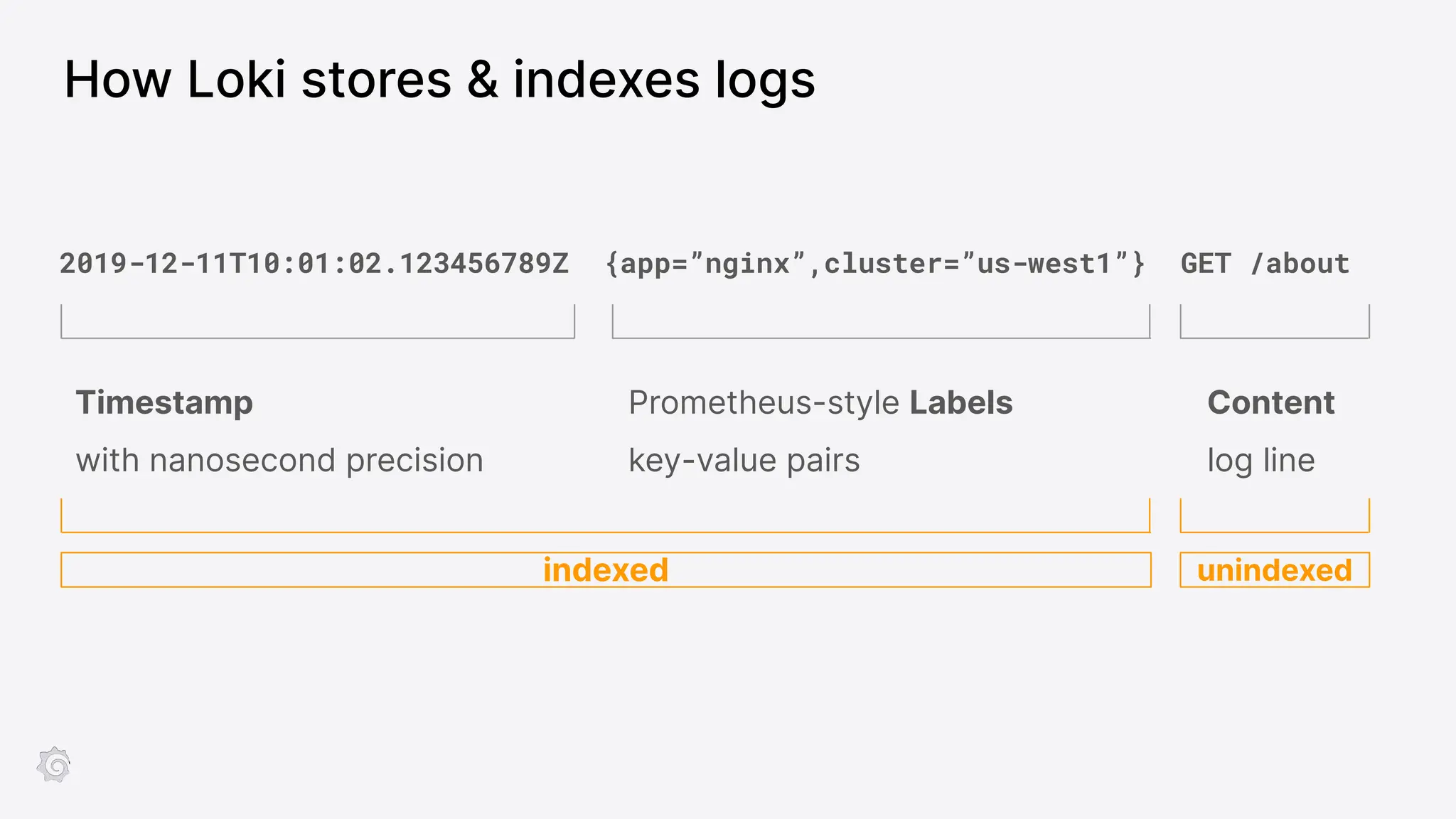
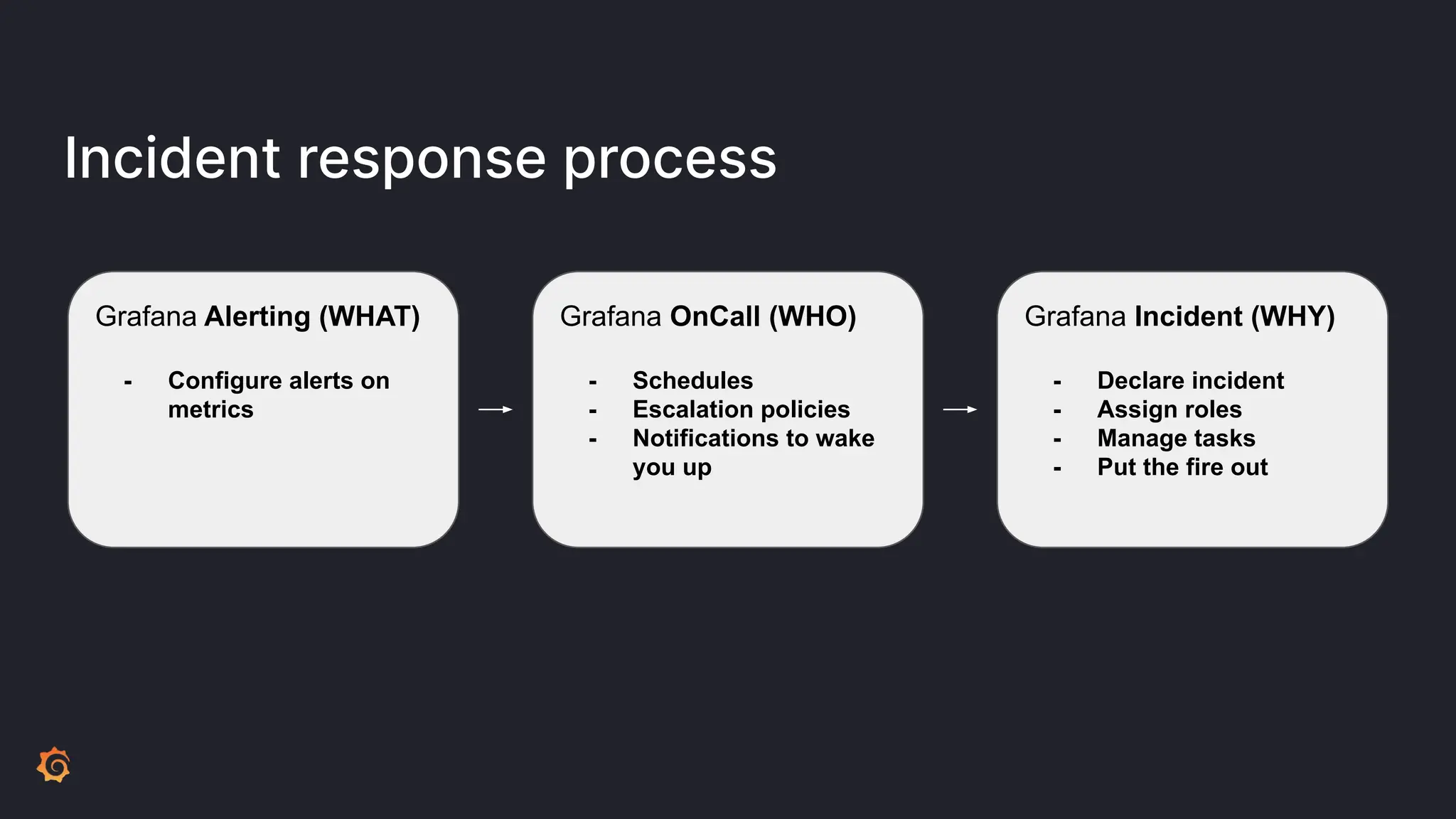
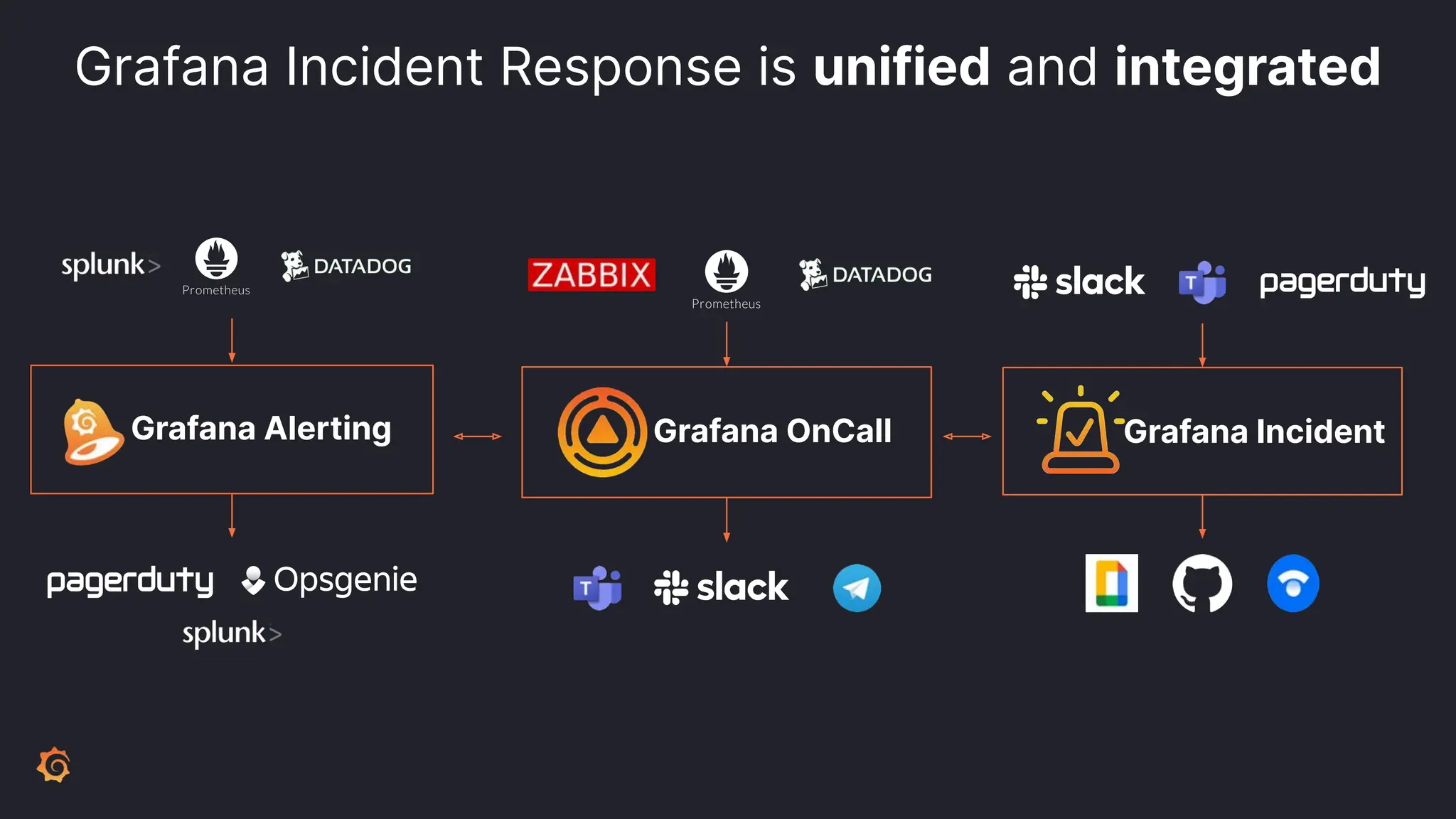
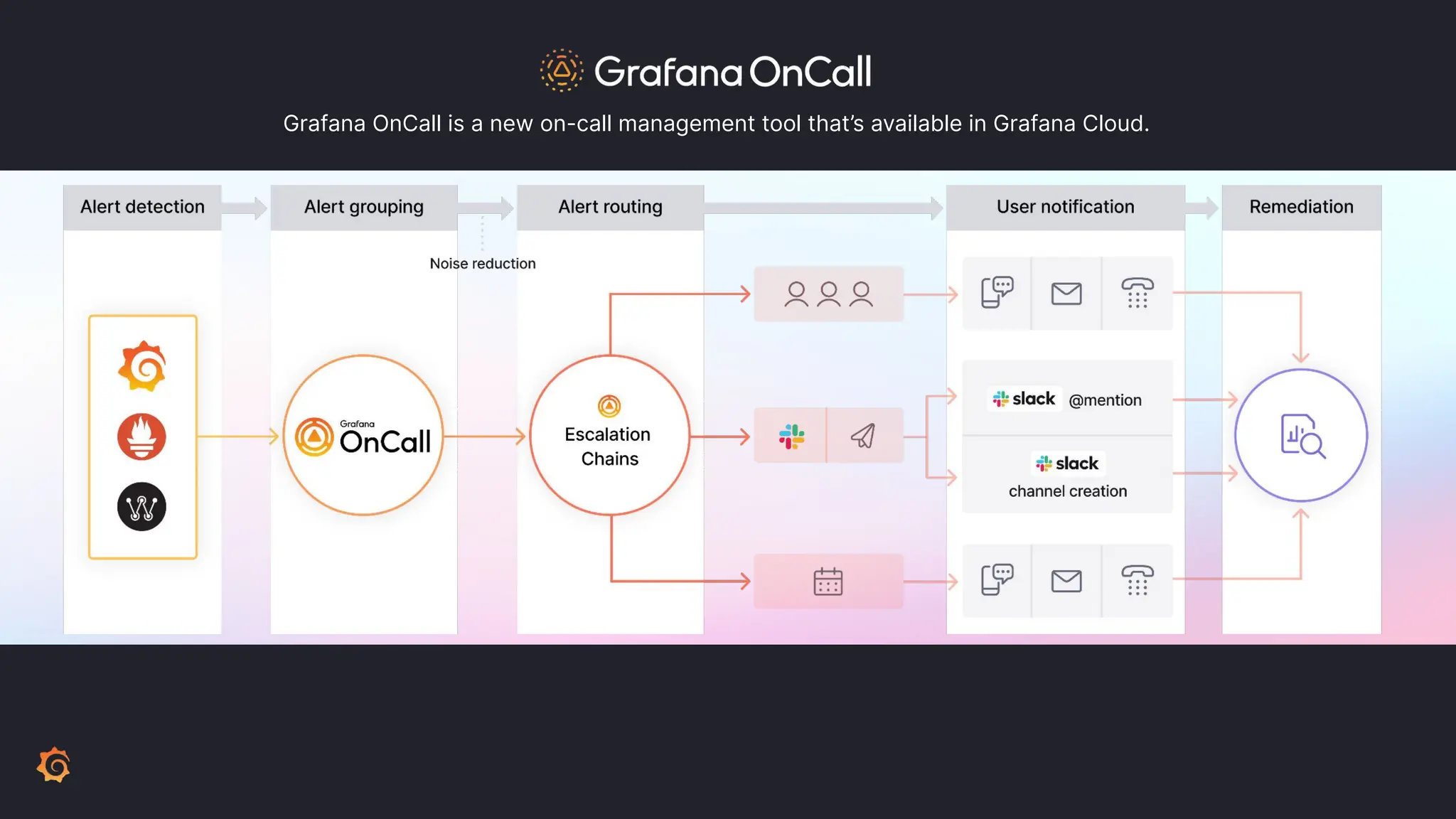
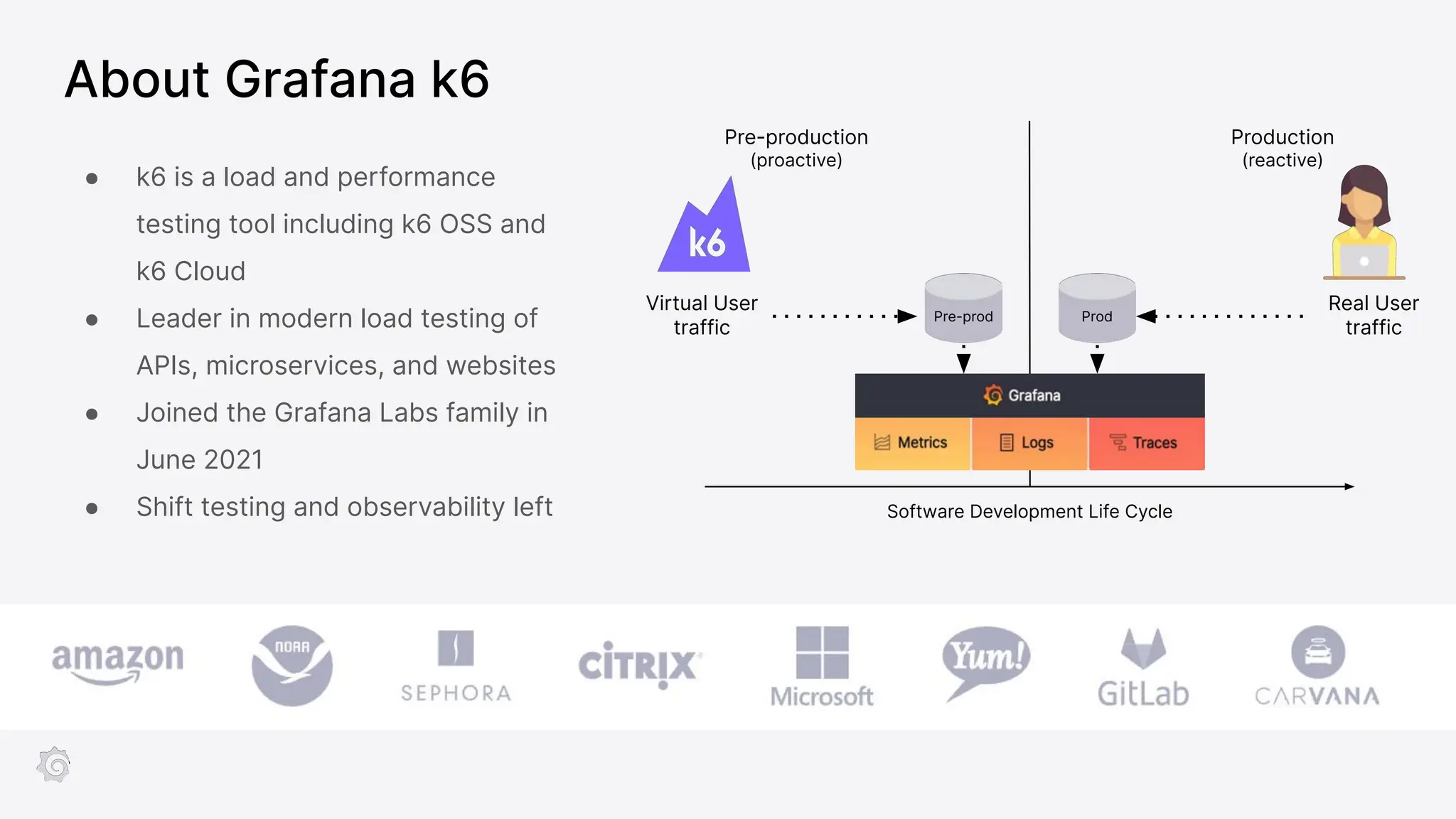
Grafana Labs employs open source developers for many observability projects and has a "big tent" strategy of providing a composable observability stack. This includes tools like Grafana for visualization, Loki for logs, Prometheus for metrics, and Tempo for traces. Grafana Labs offers these tools for self-hosted use as well as via their Grafana Cloud platform, which handles the operations.








































































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)



