Download as PDF, PPTX




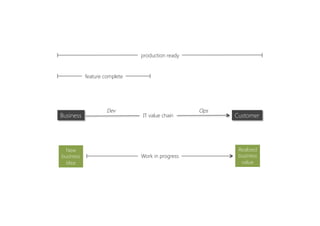







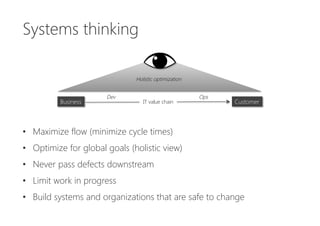
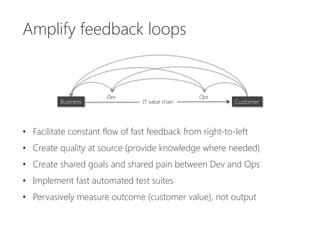
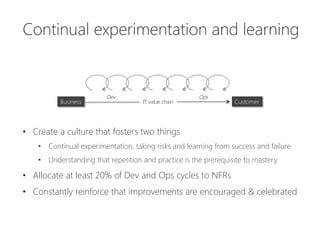

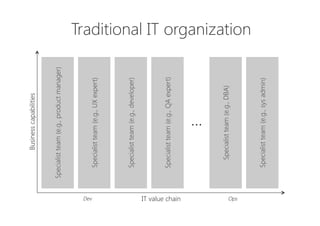

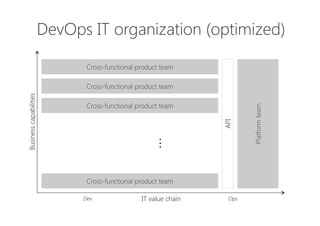































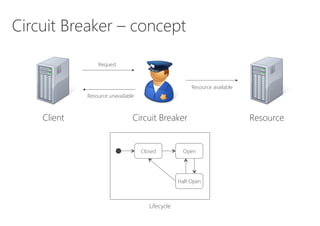




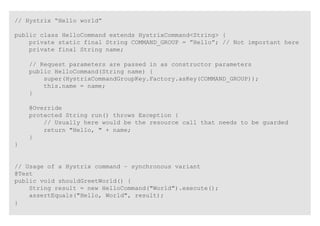
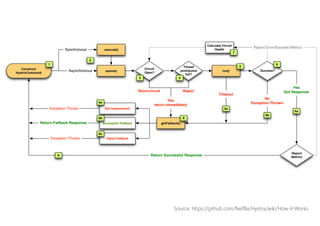















The document discusses the importance of producing software that is not only feature complete but also production-ready, emphasizing DevOps principles such as systems thinking, feedback loops, and continual experimentation. It outlines key design principles for production-ready applications, including manageability, resilience, and transparency, while addressing the challenges faced by developers and operations teams. The content also highlights the need for holistic optimization and effective collaboration between development and operations to achieve organizational goals.