Researcher perspectives on publication and peer review of data.
•
3 likes•1,154 views

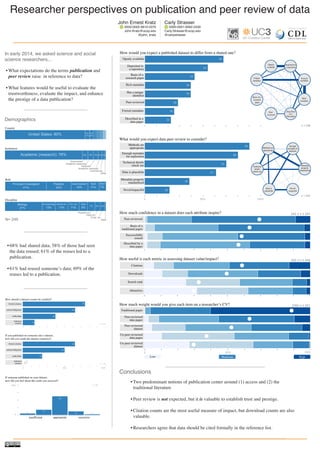
In early 2014, we asked science and social science researchers... • What expectations do the terms publication and peer review raise in reference to data? • What features would be useful to evaluate the trustworthiness, evaluate the impact, and enhance the prestige of a data publication?
Recommended

Recommended
More Related Content
What's hot
What's hot (20)
Viewers also liked
Viewers also liked (20)
Similar to Researcher perspectives on publication and peer review of data.
Similar to Researcher perspectives on publication and peer review of data. (20)
More from University of California Curation Center
More from University of California Curation Center (17)
Recently uploaded
Recently uploaded (20)
Researcher perspectives on publication and peer review of data.
- 1. Researcher perspectives on publication and peer review of data Government Academic (teaching) Academic (medical) Nonprofit Commercial United States: 80% UK 4% CA 4% Country Other Principal Investigator 41% Postdoc 24% Grad student 16% Tech 11% Other 7% Role Biology 37% Archaeology 13% Social sci. 13% Env. sci. 11% Discipline 7% 5% 4% 1 Other 9% Physical sci. Earth sci. Comp. sci. Math Academic (research): 76% 6% 5% 5% 4% 2 2 Institution N= 249 If you published on someone else’s dataset, how did you credit the dataset creator(s)? If someone published on your dataset, how did you feel about the credit you recieved? ∅ informal citation authorship acknowledgment formal citation How should a dataset creator be credited? 75 39 63 14 63 23 50 n = 249 n = 129 insufficient appropriate excessive 0 100% n = 86 63 17 5 13 2 0 50% 100% informal citation authorship acknowledgment formal citation How would you expect a published dataset to differ from a shared one? Rich metadata Basis of a research paper Deposited in a repository Openly available Described in a data paper Peer-reviewed Formal metadata Has a unique identifier What would you expect data peer review to consider? Methods are appropriate Enough metadata for replication Metadata properly standardized Technical details check out Data is plausibile Novel/impactful 68 54 43 39 39 28 25 22 80 70 61 39 22 n = 246 n = 244 Deposited in a repository Formal metadata Openly available Rich metadata Unique identifier Peer-reviewed Basis of a research paper Described in a data paper Enough metadata to replicate Methods are appropriate Metadata properly standardized Technical details check out Data is plausibile Novel/ impactful Low Citations Downloads Search rank Altmetrics Traditional paper Peer-reviewed data paper Peer-reviewed dataset Un-peer-reviewed data paper Un-peer-reviewed dataset How much weight would you give each item on a researcher’s CV? How useful is each metric in assessing dataset value/impact? Basis of a traditional paper Described by a data paper Successfullly reused Peer-reviewed How much confidence in a dataset does each attribute inspire? 0 50% 100% Moderate High 0 50% 100% 242 ≤ n ≤ 247 242 ≤ n ≤ 244 238≤ n ≤ 241 90 • What expectations do the terms publication and peer review raise in reference to data? • What features would be useful to evaluate the trustworthiness, evaluate the impact, and enhance the prestige of a data publication? • Two predominant notions of publication center around (1) access and (2) the traditional literature • Peer review is not expected, but it is valuable to establish trust and prestige. • Citation counts are the most useful measure of impact, but download counts are also valuable. • Researchers agree that data should be cited formally in the reference list. • 68% had shared data; 58% of those had seen the data reused; 61% of the reuses led to a publication. • 61% had reused someone’s data; 69% of the reuses led to a publication. Demographics John Ernest Kratz 0000-0002-9610-5370 John.Kratz@ucop.edu @john_kratz Carly Strasser 0000-0001-9592-2339 Carly.Strasser@ucop.edu @carlystrasser In early 2014, we asked science and social science researchers... Conclusions