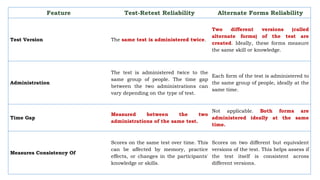
The document discusses the concepts of reliability and validity in behavioral research, emphasizing the importance of measuring instruments for accurate observation of human behavior. It outlines several methods for estimating reliability, including test-retest reliability, alternative forms, and internal consistency, along with their advantages and disadvantages. Additionally, it highlights the significance of reliability testing in ensuring consistency and accuracy in psychological assessments.



































![Norms[1]](https://cdn.slidesharecdn.com/ss_thumbnails/norms1-110821093015-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























































