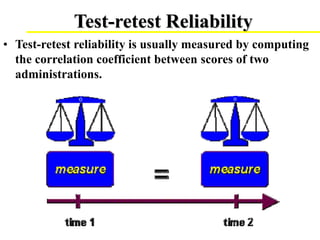
This document discusses various methods for evaluating the reliability of measurement instruments, including internal consistency, test-retest reliability, interrater reliability, split-half methods, and alternate forms methods. It provides details on calculating and interpreting each type of reliability. Factors that can influence reliability are also examined, such as the number of items, characteristics of test takers, heterogeneity of items and groups, and time between test administrations. The document emphasizes that reliability is important for ensuring measurement tools provide consistent results.