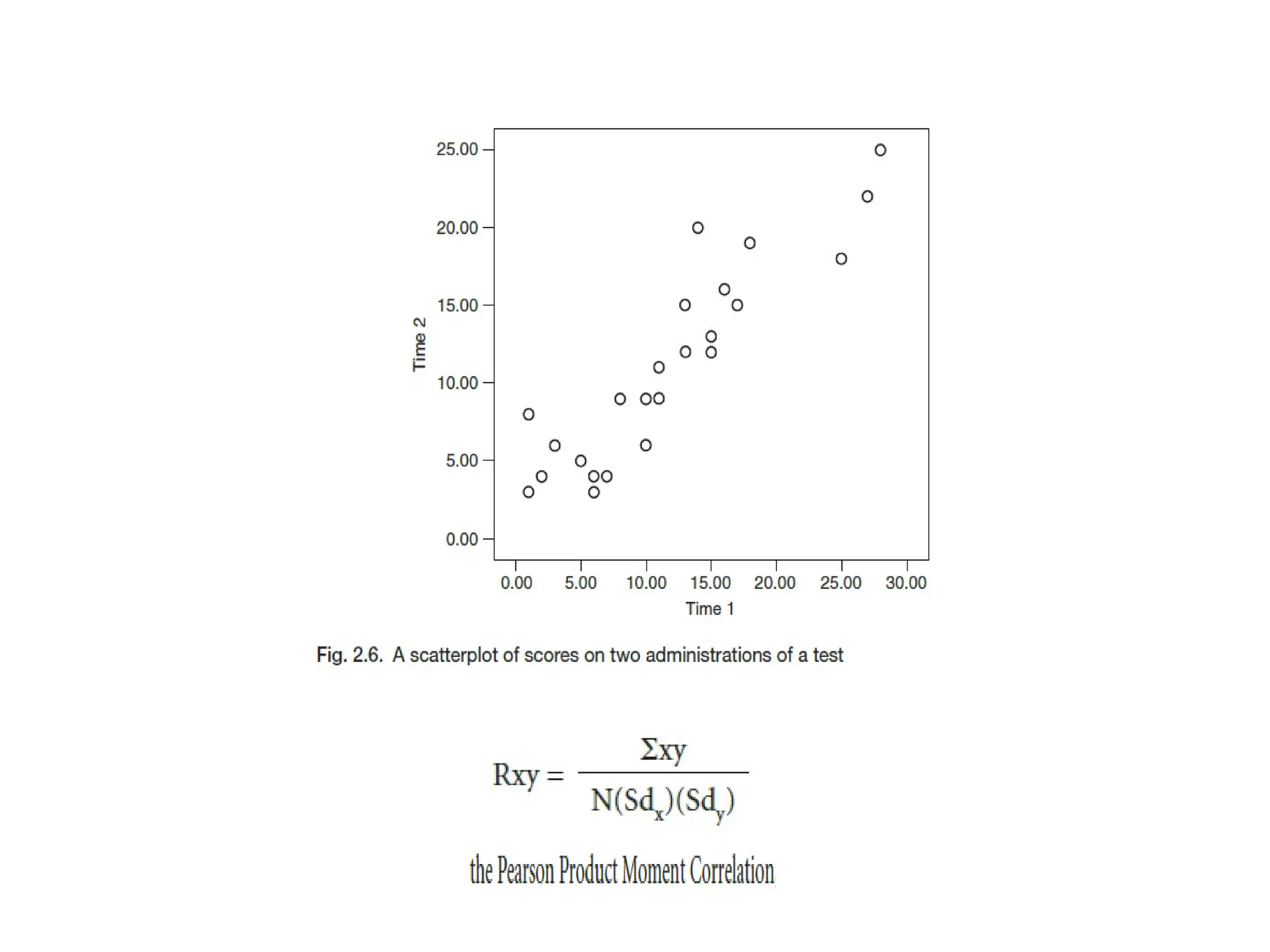
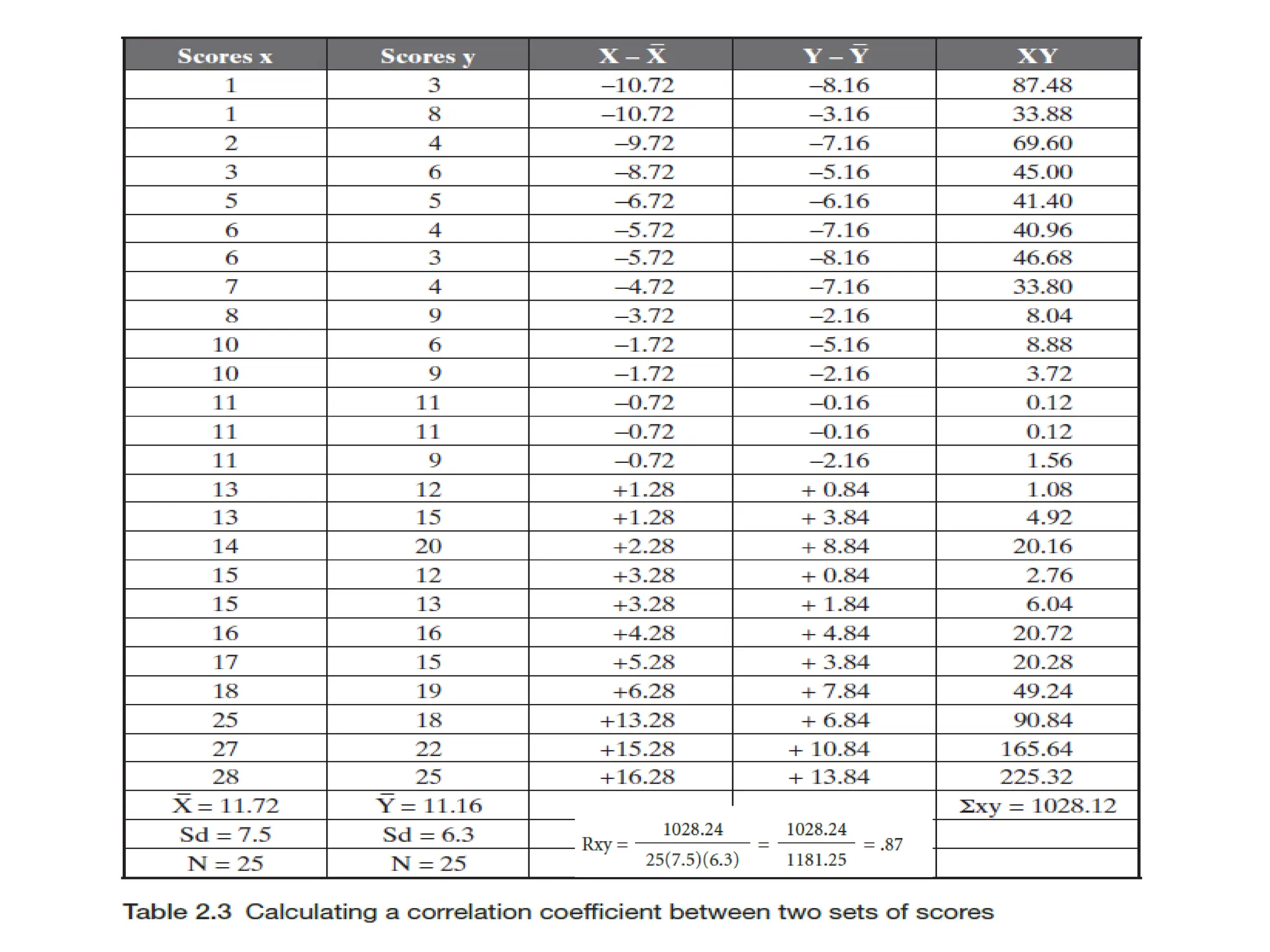
The document discusses the concept of reliability in testing, highlighting various factors that can contribute to unreliability such as student-related issues, rater inconsistencies, test administration conditions, and inherent test characteristics. It explains methods for calculating reliability, including internal consistency measures like the split-half and Kuder-Richardson formulas, as well as external reliability through test-retest and equivalent-forms methods. The overall aim is to establish dependable measures of test scores to ensure accurate evaluations of test-takers' abilities.



























































![[DSC Europe 25] Djordje Hirs - Revolutionizing Telco Customer Experience with...](https://cdn.slidesharecdn.com/ss_thumbnails/zif75aur3qscnckv6tnc-djordje-hirs-cc-dsc2025-1-251219145617-679178aa-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dobrica Cosic - From Electrons to Innovation: How Granular Da...](https://cdn.slidesharecdn.com/ss_thumbnails/h4qk69zereaumbceubgr-dobrica-cosic-from-electrons-to-innovation-how-granular-data-and-analytics-are--251218085301-b982fb14-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Djordjevic - AI can help Agriculture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/c0huq0ztiubmgccem2hc-marko-djordjevic-ai-can-help-agriculture-251218125253-7606f036-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Maria Kokiasmenos - AI Governance US Perspective.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/eszqnbzlsqa2vch6dmci-6-251215095918-6fcdf45f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Francisco Prado Moreno - Model Validation in the Age of AI: T...](https://cdn.slidesharecdn.com/ss_thumbnails/2igqvkir1yd2yzlhoylg-3-251215095918-6676c4e6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)