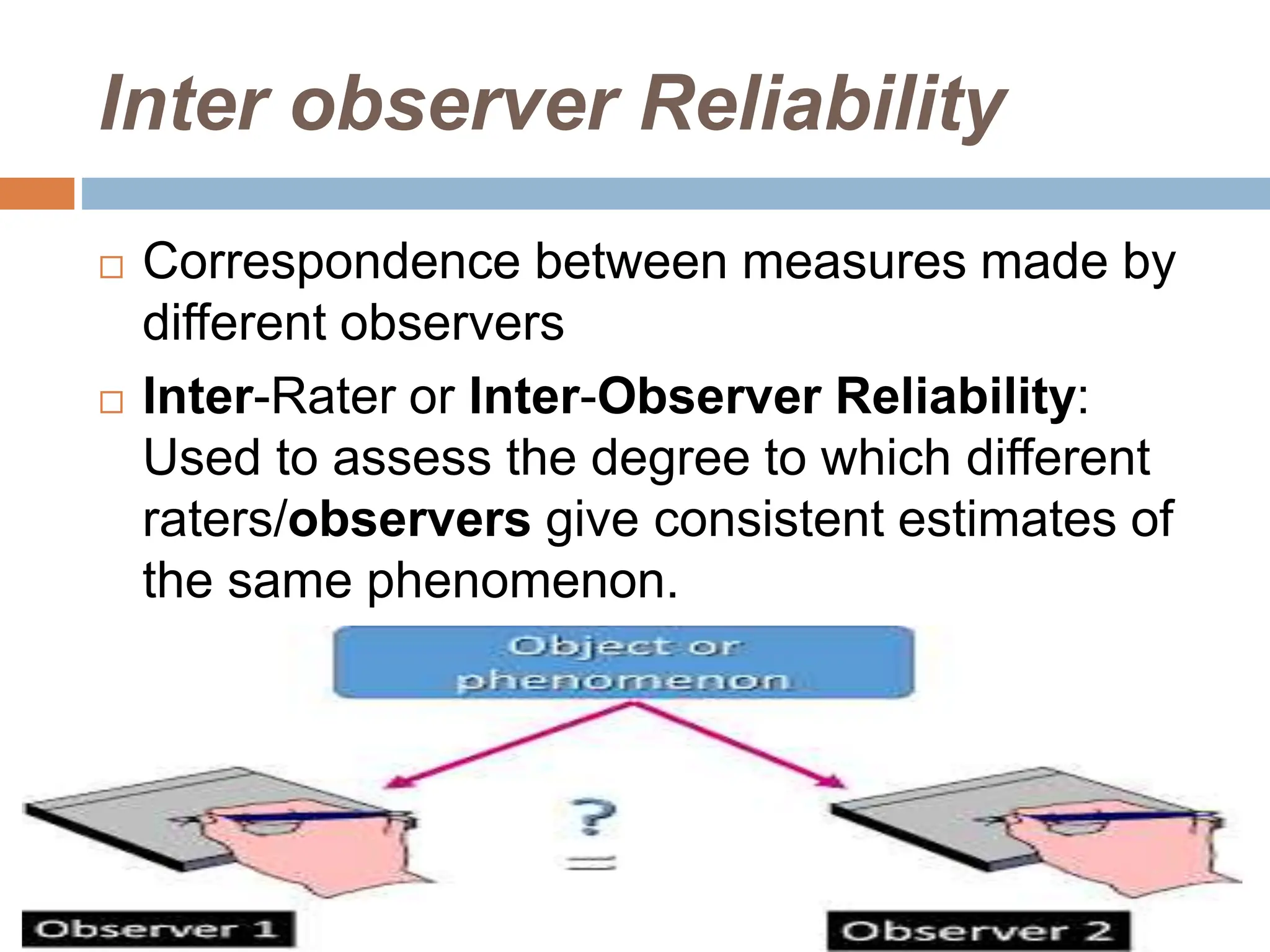
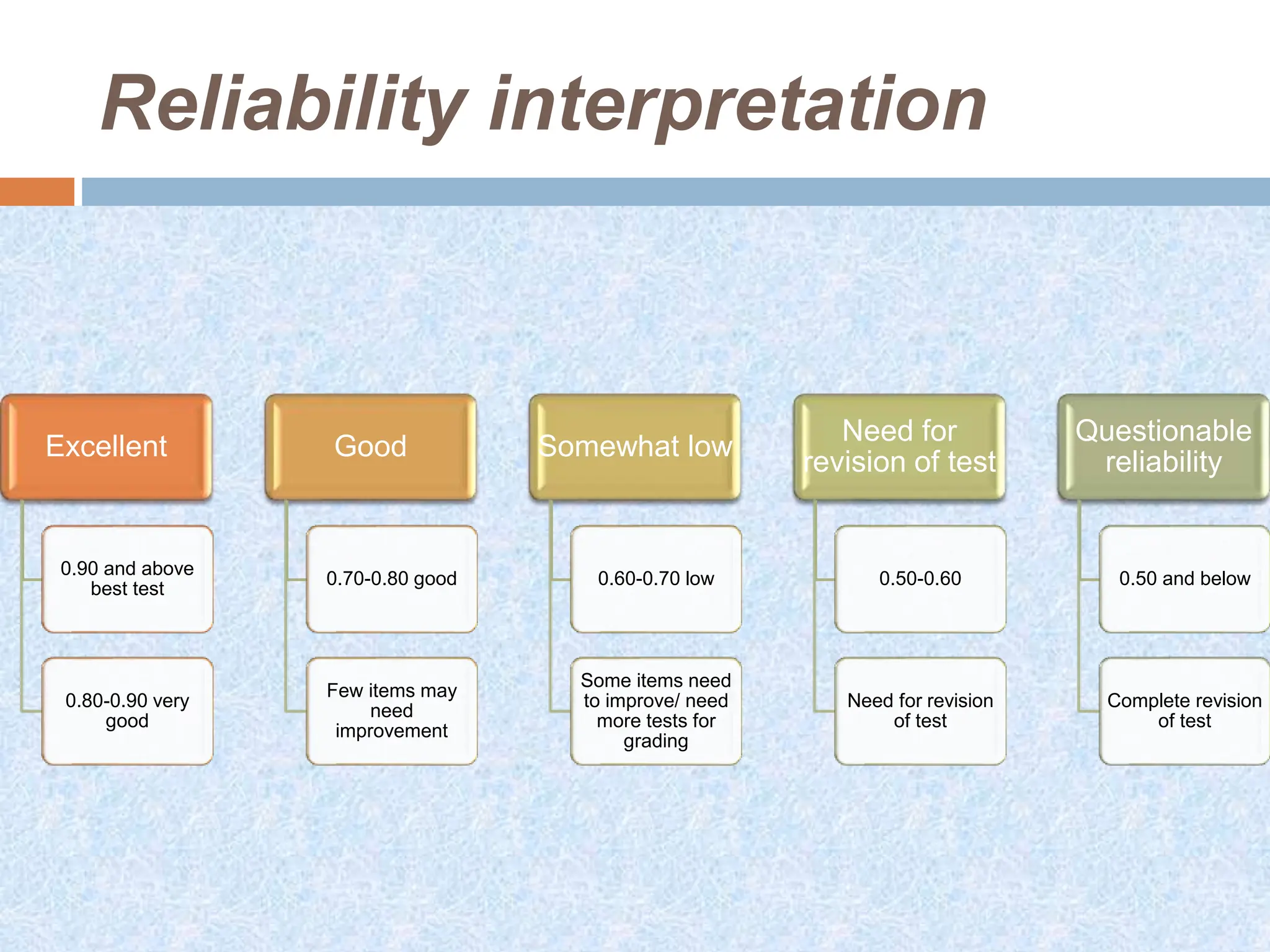
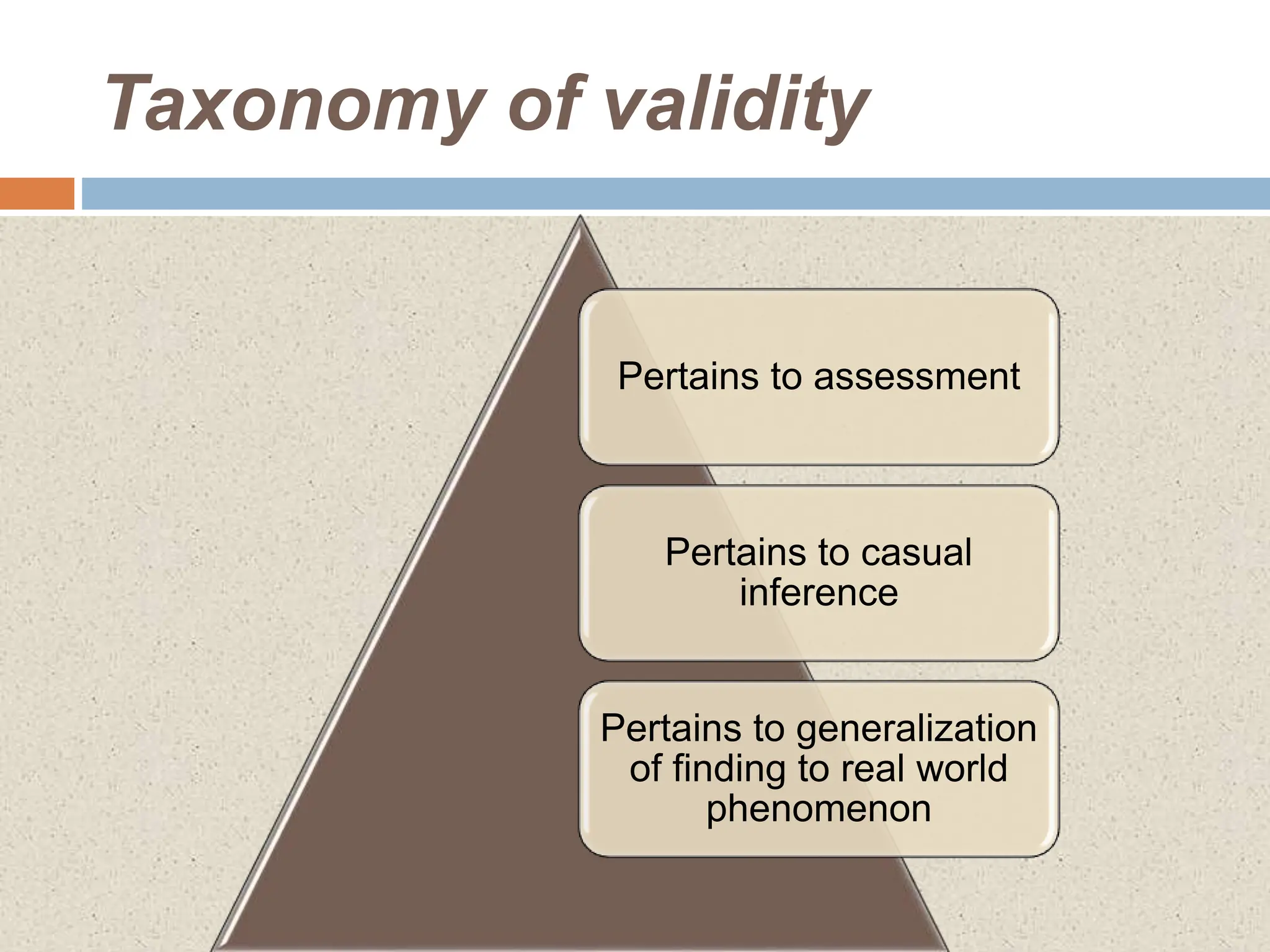
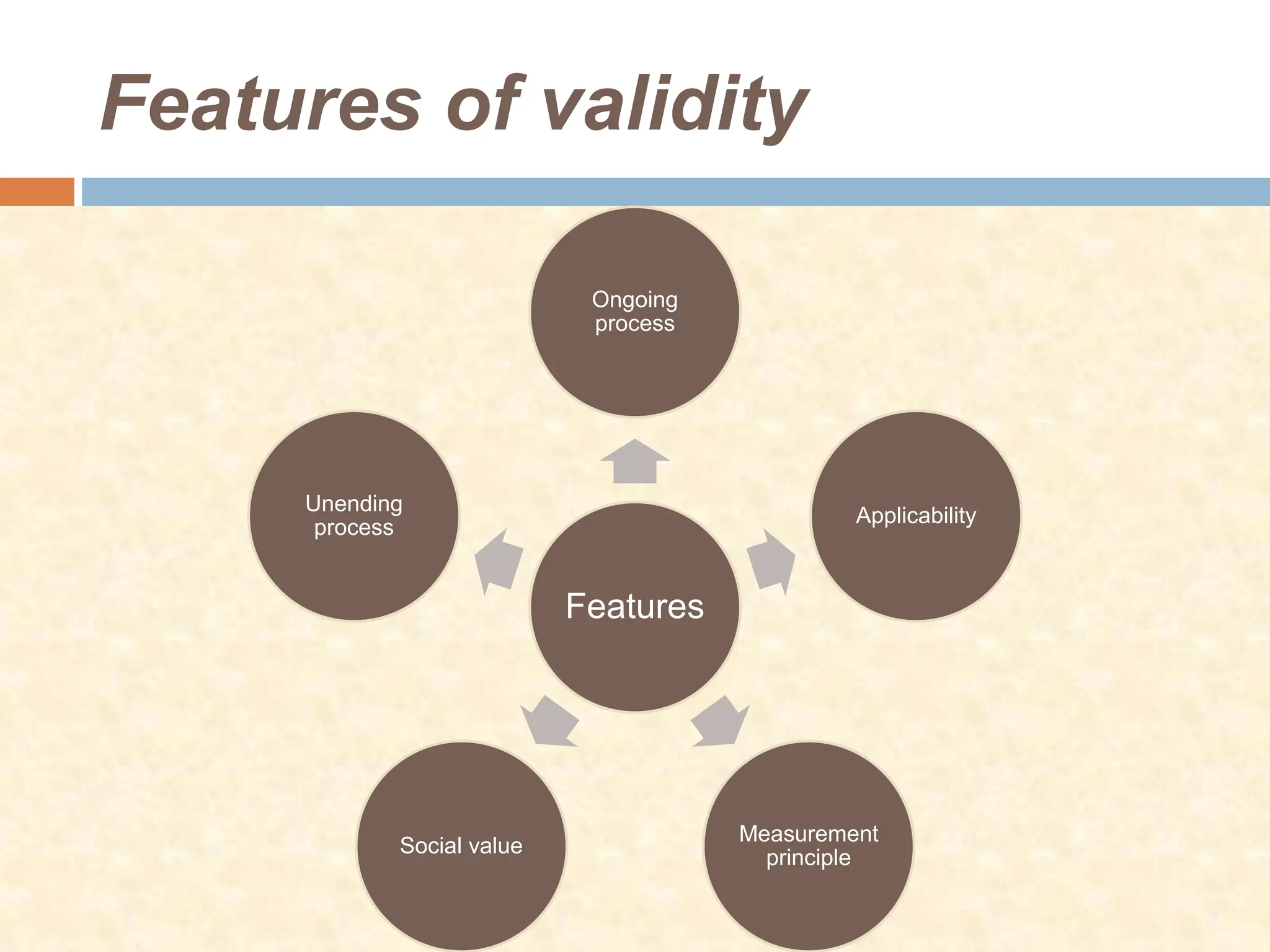
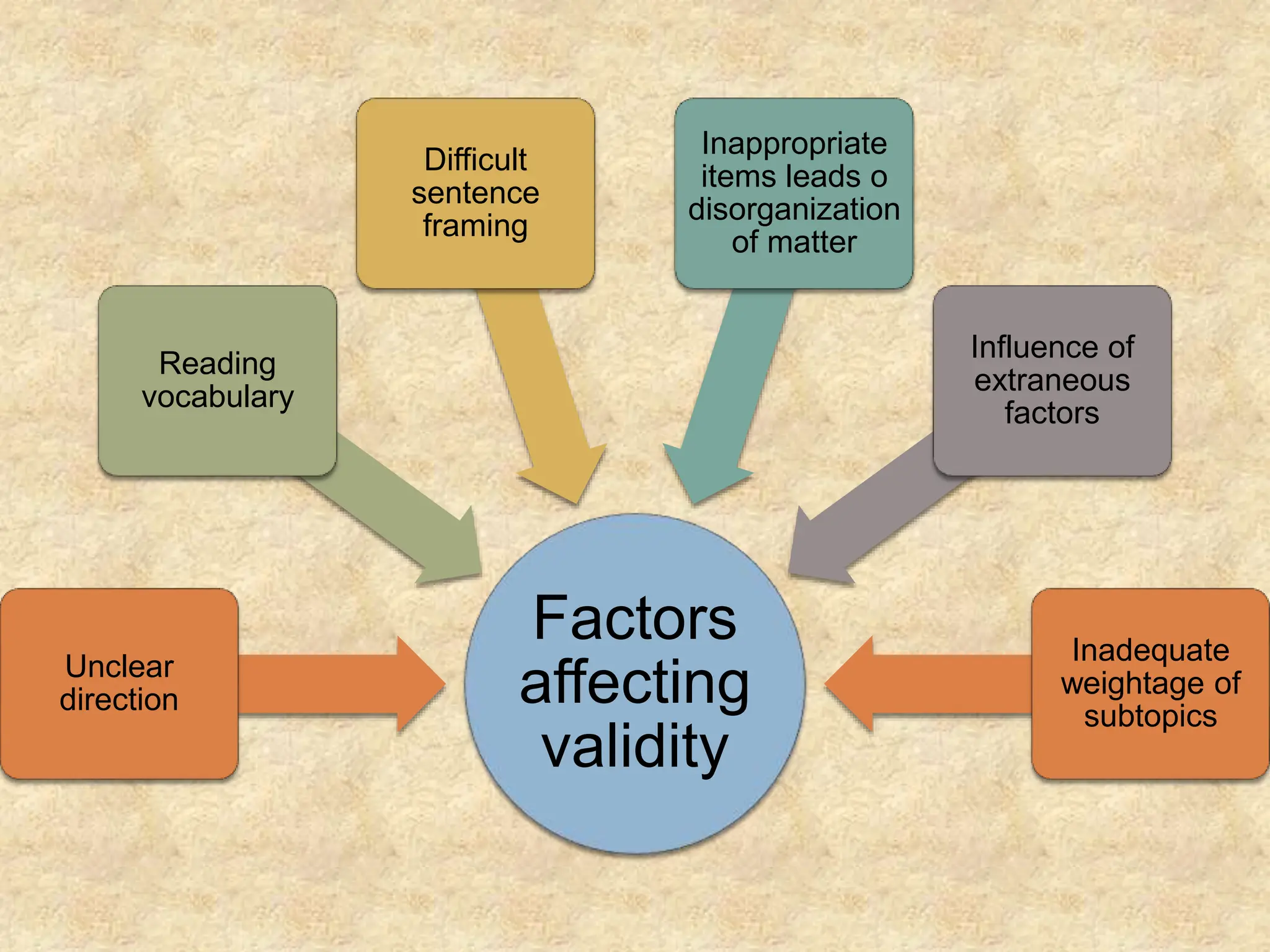
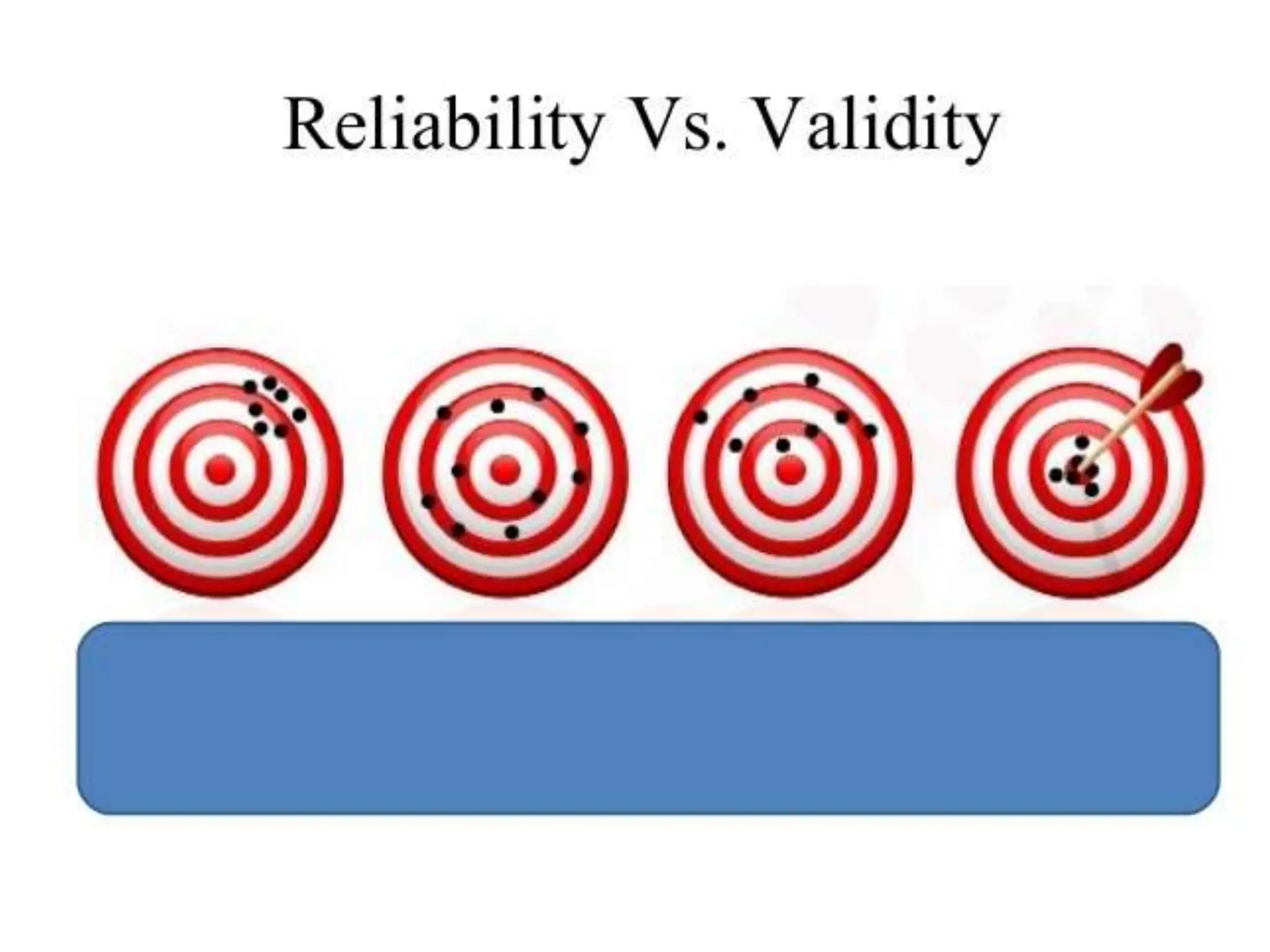
This document discusses the reliability and validity of research tools. It defines reliability as the ability of an instrument to produce consistent results. There are several approaches to assessing reliability, including stability (test-retest), equivalence, and internal consistency. Validity refers to how accurately a tool measures what it is intended to measure. There are different types of validity such as face validity, content validity, criterion validity, construct validity, predictive validity, and concurrent validity. Reliability and validity are important concepts for ensuring research tools provide accurate and reproducible measurements.