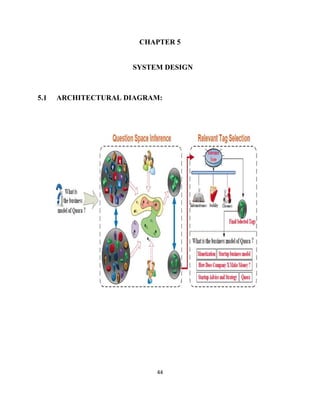
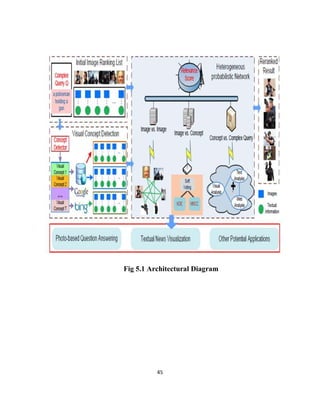
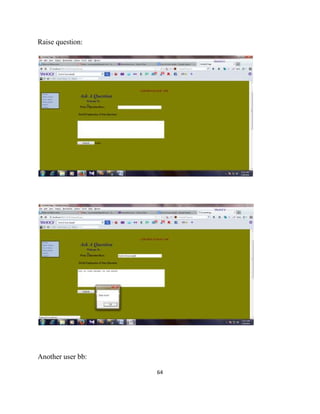
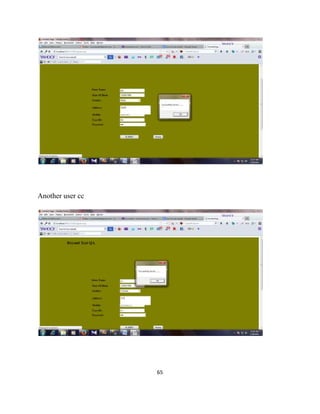
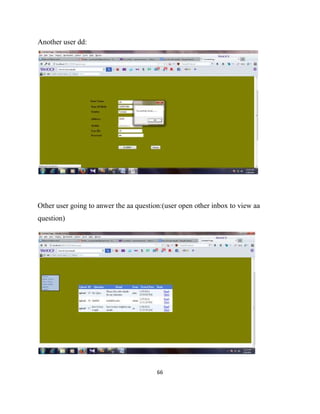
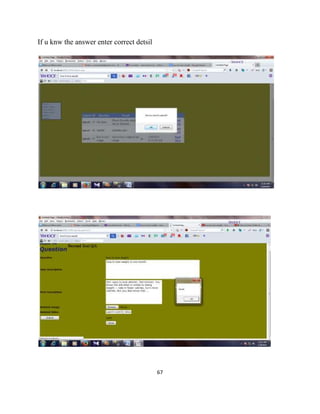
The document describes a project report submitted by three students - Prasanth, Surya, and Vembarasu - for their bachelor's degree in computer science and engineering. It discusses developing a system called "Relevant Multimedia Question Answering" that can enrich textual answers found in community question answering forums by adding relevant images and videos. The system aims to determine what type of media to add, generate queries to search for multimedia data, and select and present appropriate images and videos to enhance the original textual answers.











































![46
5.2 ALGORITHM
Relevance ranking algorithm:
There exist multiple variations of neighborhood-based CF
techniques. In this paper, to estimate R*(u, i), i.e., the rating that user u would give
to item i, we first compute the similarity between user u and other users u' using a
cosine similarity metric.
Formula : for finding prediction by using recommendation techniques:
Sim(u,u’)=sum[R(u,i).R(u’,i)]/sqrt[sum[R(u,i)2].sqrt[sum[R(u’,i)]
Where I (u, u') represents the set of all items rated by both user u and user u'. Based
on the similarity calculation, set N (u) of nearest neighbors of user u is obtained.
The size of set N (u) can range anywhere from 1 to |U|-1, i.e., all other users in the
dataset.
Then, R*(u, i) is calculated as the adjusted weighted sum of all
known ratings R (u', i) Here R (u) represents the average rating of user u. A
neighborhood-based CF technique can be user-based or item-based, depending on
whether the similarity is calculated between users or items, the user-based
approach, but they can be straightforwardly rewritten for the item-based approach
because of the symmetry between users and items in all neighborhood-based CF
calculations. In our experiments we used both user-based and item-based
approaches for rating estimation](https://image.slidesharecdn.com/relevantmultimediaquestionanswering-140426114308-phpapp02/85/Relevant-multimedia-question-answering-46-320.jpg)



![50
APPENDICES-1
Source Code:
Admin Login:
using System;
using System.Data;
using System.Configuration;
using System.Collections;
using System.Web;
using System.Web.Security;
using System.Web.UI;
using System.Web.UI.WebControls;
using System.Web.UI.WebControls.WebParts;
using System.Web.UI.HtmlControls;
using System.Data.SqlClient;
public partial class adminlogin : System.Web.UI.Page
{
SqlConnection con = new
SqlConnection(System.Configuration.ConfigurationManager.AppSettings["con"]);
protected void Button1_Click(object sender, EventArgs e)
{
SqlCommand cmd=new SqlCommand ("select count(*) from login where
uid='"+TextBox1 .Text +"' and pwd='"+ TextBox2 .Text +"' ", con);
con.Open();](https://image.slidesharecdn.com/relevantmultimediaquestionanswering-140426114308-phpapp02/85/Relevant-multimedia-question-answering-50-320.jpg)

![52
public partial class Askquest : System.Web.UI.Page
{
SqlConnection con = new
SqlConnection(System.Configuration.ConfigurationManager.AppSettings["con"]);
protected void Page_Load(object sender, EventArgs e)
{
DateTime d = Convert.ToDateTime(DateTime.Now.ToLongTimeString());
Label3.Text = d.ToString();
Label6.Text = Session["uid"].ToString();
}
protected void Button1_Click(object sender, EventArgs e)
{
string str = "insert into askqust (ques,qdetail,mailfrom,today)values ('" +
TextBox5.Text + "','" + TextBox1.Text + "','" + Label6.Text + "','" + Label3.Text +
"')";
Connection.ExecuteQuery(str);
MessageBox.Show("Datas Saved");
TextBox1.Text = "";
TextBox5.Text = "";
}
}
Doc Details:
using System;
using System.Data;](https://image.slidesharecdn.com/relevantmultimediaquestionanswering-140426114308-phpapp02/85/Relevant-multimedia-question-answering-52-320.jpg)
![53
using System.Configuration;
using System.Collections;
using System.Web;
using System.Web.Security;
using System.Web.UI;
using System.Web.UI.WebControls;
using System.Web.UI.WebControls.WebParts;
using System.Web.UI.HtmlControls;
using System.Data.SqlClient;
using System.IO;
using System.Windows.Forms;
public partial class docdetails : System.Web.UI.Page
{
SqlConnection con = new
SqlConnection(System.Configuration.ConfigurationManager.AppSettings["con"]);
protected void Page_Load(object sender, EventArgs e)
{
string qry = string.Empty;
qry="select *from askqust where qid='"+Request.QueryString["id"]+"'";
DataSet ds=new DataSet();
ds=Connection.ExecuteQuery(qry);
if (ds != null)
{
Label7.Text=ds.Tables[0].Rows[0]["ques"].ToString();
TextBox1.Text=ds.Tables[0].Rows[0]["qdetail"].ToString();](https://image.slidesharecdn.com/relevantmultimediaquestionanswering-140426114308-phpapp02/85/Relevant-multimedia-question-answering-53-320.jpg)

![55
SqlConnection con = new
SqlConnection(System.Configuration.ConfigurationManager.AppSettings["con"])
protected void Button1_Click(object sender, EventArgs e)
{
try
{
string str = "insert into docreg values('" + TextBox1.Text + "','" + TextBox2.Text +
"'," + TextBox3.Text + ",'" + TextBox4.Text + "','" + TextBox5.Text + "','" +
TextBox6.Text + "','"+TextBox7.Text+"')";
SqlCommand cmd = new SqlCommand(str , con);
con.Open();
int c = cmd.ExecuteNonQuery();
if (c > 0)
{
Label8.Text = "Successfully Register";
}
con.Close();
TextBox1.Text = "";
TextBox2.Text = "";
TextBox3.Text = " ";
TextBox4.Text = "";
TextBox5.Text = "";
TextBox6.Text = "";
TextBox7.Text = "";
}](https://image.slidesharecdn.com/relevantmultimediaquestionanswering-140426114308-phpapp02/85/Relevant-multimedia-question-answering-55-320.jpg)

![57
public partial class register : System.Web.UI.Page
{
SqlConnection con = new
SqlConnection(System.Configuration.ConfigurationManager.AppSettings["con"]);
protected void Button1_Click(object sender, EventArgs e)
{
try
{
string str="insert into register values('"+TextBox1.Text+ "','" + TextBox2.Text +
"','" + DropDownList1.SelectedItem.Value + "','" + TextBox4.Text + "','" +
TextBox5.Text + "','" + TextBox7.Text + "','" + TextBox8.Text + "')";
Connection.ExecuteQuery(str);
TextBox1.Text = "";
TextBox2.Text = "";
TextBox4.Text = "";
TextBox5.Text = "";
TextBox7.Text = "";
TextBox8.Text = "";
}
catch (Exception ex)
{
Response.Redirect(ex.Message);
}
finally
{
if (con.State == ConnectionState.Open)](https://image.slidesharecdn.com/relevantmultimediaquestionanswering-140426114308-phpapp02/85/Relevant-multimedia-question-answering-57-320.jpg)

![59
SqlConnection connection = new
SqlConnection(ConfigurationManager.ConnectionStrings["con"].ConnectionString
);
SqlCommand command = new SqlCommand("SELECT * from replydata where
ques like '%"+TextBox1.Text+"%' ", connection);
SqlDataAdapter ada = new SqlDataAdapter(command);
ada.Fill(dt);
gvImages.DataSource = dt;
gvImages.DataBind();
BindGrid();
textbind();
}
private void BindGrid()
{
string strConnString =
ConfigurationManager.ConnectionStrings["con"].ConnectionString;
using (SqlConnection con = new SqlConnection(strConnString))
{
using (SqlCommand cmd = new SqlCommand())
{
cmd.CommandText = "select qid, Name from replydata where ques like'%" +
TextBox1.Text + "%'";
cmd.Connection = con;
con.Open();
DataList1.DataSource = cmd.ExecuteReader();
DataList1.DataBind();](https://image.slidesharecdn.com/relevantmultimediaquestionanswering-140426114308-phpapp02/85/Relevant-multimedia-question-answering-59-320.jpg)
![60
con.Close();
}
}
}
void textbind()
{
SqlConnection connection = new
SqlConnection(ConfigurationManager.ConnectionStrings["con"].ConnectionString
);
SqlCommand command = new SqlCommand("SELECT* from replydata where
ques like '%" + TextBox1.Text + "%'", connection);
SqlDataAdapter ada = new SqlDataAdapter(command);
ada.Fill(dt);
GridView1.DataSource = dt;
GridView1.DataBind();
}
}
View:
using System;
using System.Data;
using System.Configuration;
using System.Collections;
using System.Web;
using System.Web.Security;
using System.Web.UI;](https://image.slidesharecdn.com/relevantmultimediaquestionanswering-140426114308-phpapp02/85/Relevant-multimedia-question-answering-60-320.jpg)
![61
using System.Web.UI.WebControls;
using System.Web.UI.WebControls.WebParts;
using System.Web.UI.HtmlControls;
using System.Data.SqlClient;
public partial class viewdoct : System.Web.UI.Page
{
SqlConnection con = new
SqlConnection(System.Configuration.ConfigurationManager.AppSettings["con"]);
protected void Page_Load(object sender, EventArgs e)
{
DataSet ds = new DataSet();
ds = Connection.ExecuteQuery("select * from askqust");
GridView1.DataSource = ds.Tables[0];
GridView1.DataBind();
}
protected void GridView1_RowDeleting(object sender, GridViewDeleteEventArgs
e)
{
Label txtcity = (Label)GridView1.Rows[e.RowIndex].FindControl("Label3");
string m = txtcity.ToString();
Response.Redirect("docdetails.aspx?id=" + txtcity.Text.ToString());
}](https://image.slidesharecdn.com/relevantmultimediaquestionanswering-140426114308-phpapp02/85/Relevant-multimedia-question-answering-61-320.jpg)
![72
REFERENCES
[1] L. A. Adamic, J. Zhang, E. Bakshy, andM. S. Ackerman,(2008) “Knowledge
sharing and Yahoo answers: Everyone knows something,” in Proc. Int.
World Wide Web Conf.
[2] J. Cao, F. Jay, and J. Nunamaker,(2004)“Question answering on lecture
videos: A multifaceted approach,” in Proc. Int. Joint Conf. Digital Libraries.
[3] H. Cui, M.-Y. Kan, and T.-S. Chua,(2007) “Soft pattern matching models
for definitional question answering,” ACM Trans. Inf. Syst., vol. 25, no. 2,
pp. 30–30.
[4] L. Nie, M. Wang, Z. Zha, G. Li, and T.-S. Chua,(2011)“Multimedia
answering: Enriching text QA with media information,” in Proc. ACM Int.
SIGIR Conf.
[5] S. A. Quarteroni and S. Manandhar,(2008)“Designing an interactive open
domain question answering system,” J. Natural Lang. Eng., vol. 15, no. 1,
pp. 73–95.
[6] M. Wang, X. S. Hua, T. Mei, R. Hong, G. J. Qi, Y. Song, and L. R.
Dai,(2009) “Semi-supervised kernel density estimation for video annotation,”
Comput. Vision Image Understand., vol. 113, no. 3, pp. 384–396.
[7] R. C. Wang, N. Schlaefer, W. W. Cohen, and E. Nyberg,(2008) “Automatic
set expansion for list question answering,” in Proc. Int. Conf. Empirical
Methods in Natural Language Processing.
[8] Z.-J. Zha, X.-S. Hua, T. Mei, J. Wang, G.-J. Qi, and Z. Wang,(2008)“Joint
multi- label multi-instance learning for image classification,” in Proc.
IEEE Conf. Computer Vision and Pattern Recognition, pp. 1–8.](https://image.slidesharecdn.com/relevantmultimediaquestionanswering-140426114308-phpapp02/85/Relevant-multimedia-question-answering-72-320.jpg)









![[AAAI 2019 tutorial] End-to-end goal-oriented question answering systems](https://cdn.slidesharecdn.com/ss_thumbnails/aaai2019tutorialend-to-endgoal-orientedquestionansweringsystems-190128122117-thumbnail.jpg?width=640&height=640&fit=bounds)
![[KDD 2018 tutorial] End to-end goal-oriented question answering systems](https://cdn.slidesharecdn.com/ss_thumbnails/kdd2018tutorialend-to-endgoal-orientedquestionansweringsystems-180821081440-thumbnail.jpg?width=640&height=640&fit=bounds)










































![[IJET-V2I2P5] Authors:Mr. Veer Karan Bharat1, Miss. Dethe Pratima Vilas2, Mis...](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v2i2p5-160427184225-thumbnail.jpg?width=640&height=640&fit=bounds)

































