Downloaded 11 times




![PRESENTED BY
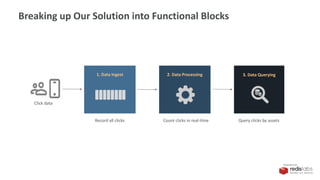
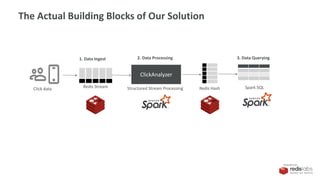
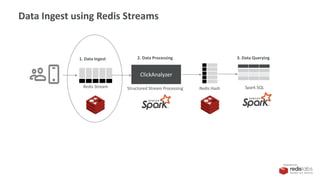
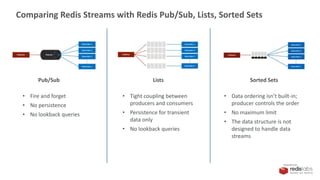
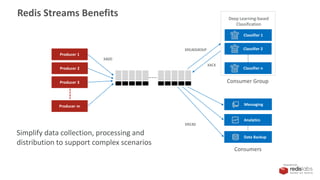
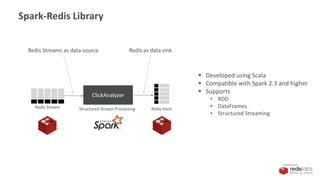
Our Ingest Solution
Redis Stream
1. Data Ingest
Command
xadd clickstream * img [image_id]
Sample data
127.0.0.1:6379> xrange clickstream - +
1) 1) "1553536458910-0"
2) 1) ”image_1"
2) "1"
2) 1) "1553536469080-0"
2) 1) ”image_3"
2) "1"
3) 1) "1553536489620-0"
2) 1) ”image_3"
2) "1”
.
.
.
.](https://image.slidesharecdn.com/redis-streams-redis-spark-structured-streaming-190905175520/85/Redis-Streams-plus-Spark-Structured-Streaming-18-320.jpg)



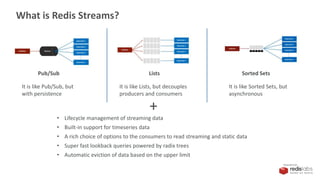
![PRESENTED BY
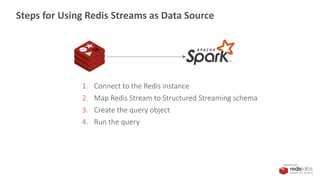
Redis Streams as Data Source
1. Connect to the Redis instance
val spark = SparkSession.builder()
.appName("redis-df")
.master("local[*]")
.config("spark.redis.host", "localhost")
.config("spark.redis.port", "6379")
.getOrCreate()
val clickstream = spark.readStream
.format("redis")
.option("stream.keys","clickstream")
.schema(StructType(Array(
StructField("img", StringType)
)))
.load()
val queryByImg = clickstream.groupBy("img").count](https://image.slidesharecdn.com/redis-streams-redis-spark-structured-streaming-190905175520/85/Redis-Streams-plus-Spark-Structured-Streaming-26-320.jpg)
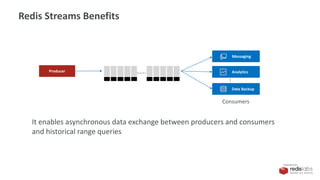
![PRESENTED BY
Redis Streams as Data Source
2. Map Redis Stream to Structured Streaming schema
val spark = SparkSession.builder()
.appName("redis-df")
.master("local[*]")
.config("spark.redis.host", "localhost")
.config("spark.redis.port", "6379")
.getOrCreate()
val clickstream = spark.readStream
.format("redis")
.option("stream.keys","clickstream")
.schema(StructType(Array(
StructField("img", StringType)
)))
.load()
val queryByImg = clickstream.groupBy("img").count
xadd clickstream * img [image_id]](https://image.slidesharecdn.com/redis-streams-redis-spark-structured-streaming-190905175520/85/Redis-Streams-plus-Spark-Structured-Streaming-27-320.jpg)
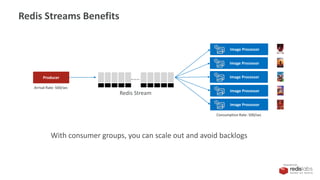
![PRESENTED BY
Redis Streams as Data Source
3. Create the query object
val spark = SparkSession.builder()
.appName("redis-df")
.master("local[*]")
.config("spark.redis.host", "localhost")
.config("spark.redis.port", "6379")
.getOrCreate()
val clickstream = spark.readStream
.format("redis")
.option("stream.keys","clickstream")
.schema(StructType(Array(
StructField("img", StringType)
)))
.load()
val queryByImg = clickstream.groupBy("img").count](https://image.slidesharecdn.com/redis-streams-redis-spark-structured-streaming-190905175520/85/Redis-Streams-plus-Spark-Structured-Streaming-28-320.jpg)

![PRESENTED BY
How to Setup Redis as Output Sink
override def process(record: Row) = {
var img = record.getString(0);
var count = record.getLong(1);
if(jedis == null){
connect()
}
jedis.hset("clicks:"+img, "img", img)
jedis.hset("clicks:"+img, "count", count.toString)
}
Create a custom class extending ForeachWriter and override the method, process()
Save as Hash with structure
clicks:[image]
img [image]
count [count]
Example
clicks:image_1001
img image_1001
count 1029
clicks:image_1002
img image_1002
count 392
.
.
.
img count
image_1001 1029
image_1002 392
. .
. .
Table: Clicks](https://image.slidesharecdn.com/redis-streams-redis-spark-structured-streaming-190905175520/85/Redis-Streams-plus-Spark-Structured-Streaming-30-320.jpg)


![PRESENTED BY
1. Initialize
scala> import org.apache.spark.sql.SparkSession
scala> val spark = SparkSession.builder().appName("redis-
test").master("local[*]").config("spark.redis.host","localhost").config("spark.redis.port","6379").getOrCreate()
scala> val sc = spark.sparkContext
scala> import spark.sql
scala> import spark.implicits._
2. Create table
scala> sql("CREATE TABLE IF NOT EXISTS clicks(img STRING, count INT) USING org.apache.spark.sql.redis OPTIONS (table
'clicks’)”)
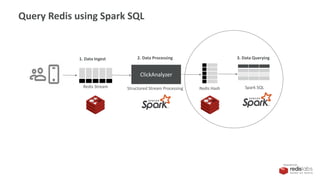
How to Query Redis using Spark SQL](https://image.slidesharecdn.com/redis-streams-redis-spark-structured-streaming-190905175520/85/Redis-Streams-plus-Spark-Structured-Streaming-34-320.jpg)



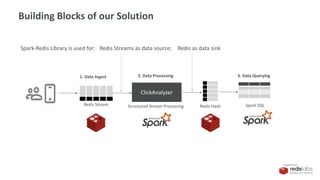



The document discusses the integration of Redis Streams and Apache Spark Structured Streaming for scalable real-time data processing. It outlines the architecture for data ingestion, processing, and querying, emphasizing the advantages of Redis Streams for managing continuous applications with persistence and consumer management. Additionally, it highlights how to implement structured streaming with Redis as both a data source and sink using Spark SQL for efficient analytics.




![[AKIBA.AWS] VGWのルーティング仕様](https://cdn.slidesharecdn.com/ss_thumbnails/akibaaws7-180524115259-thumbnail.jpg?width=640&height=640&fit=bounds)










































































