Download as PDF, PPTX















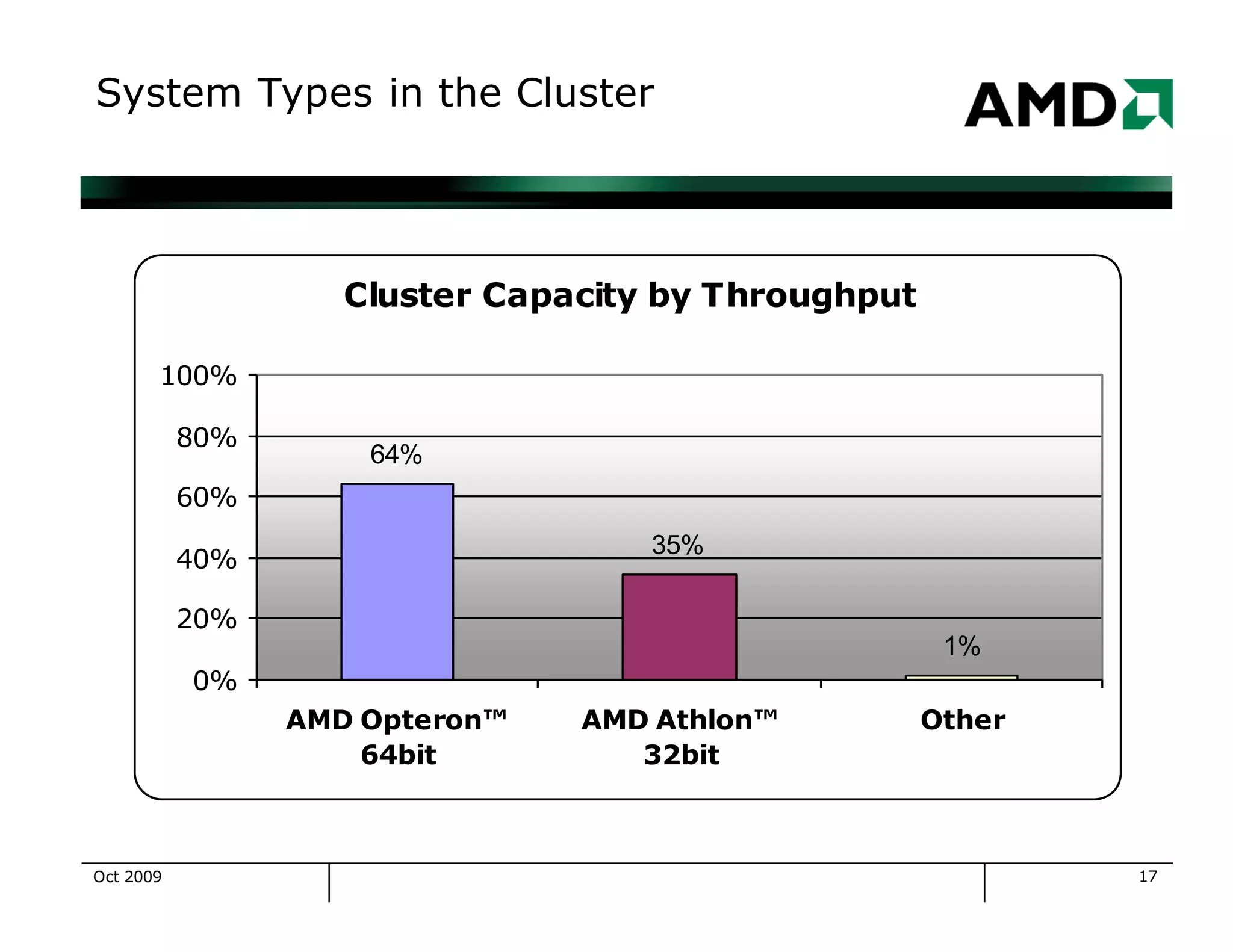
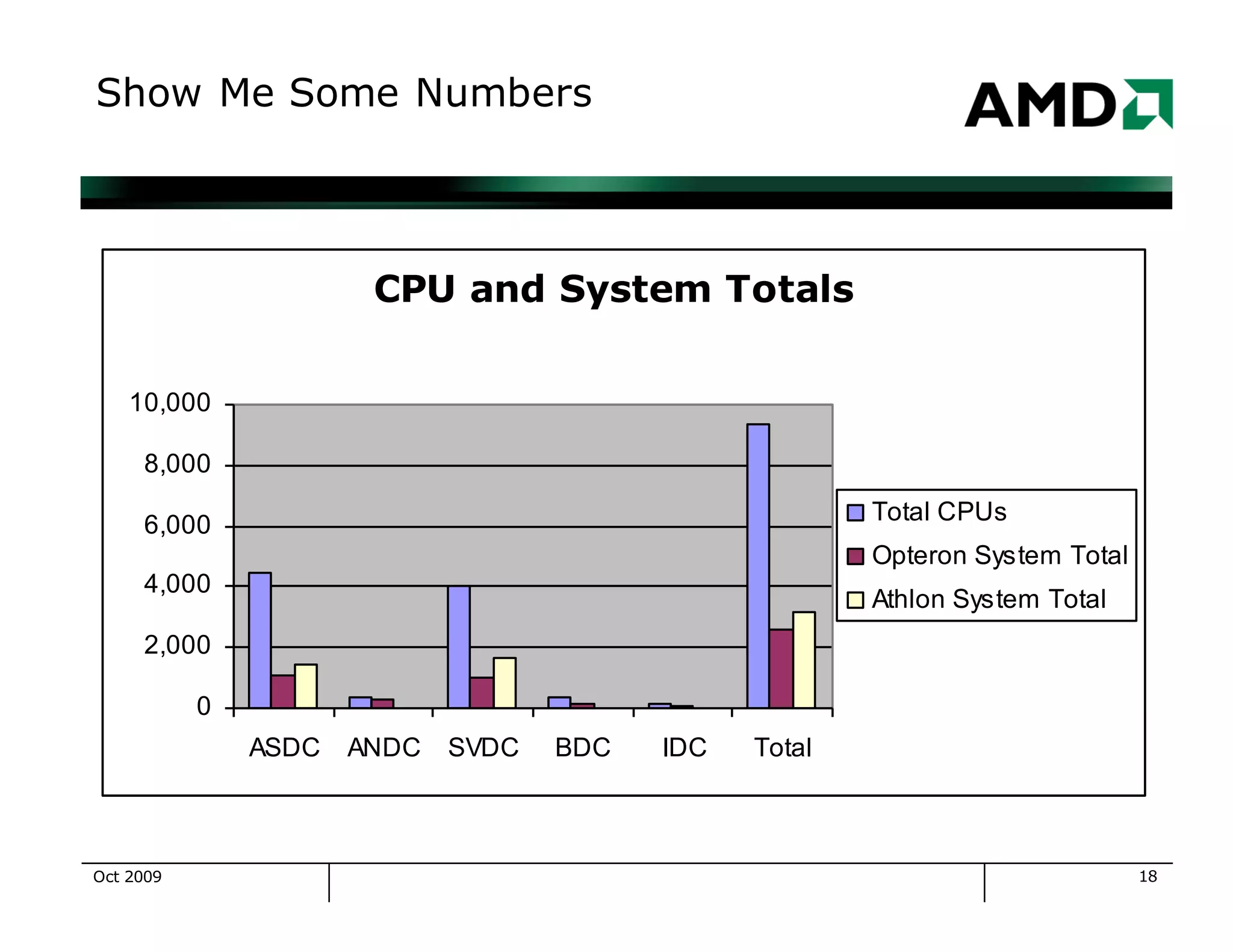
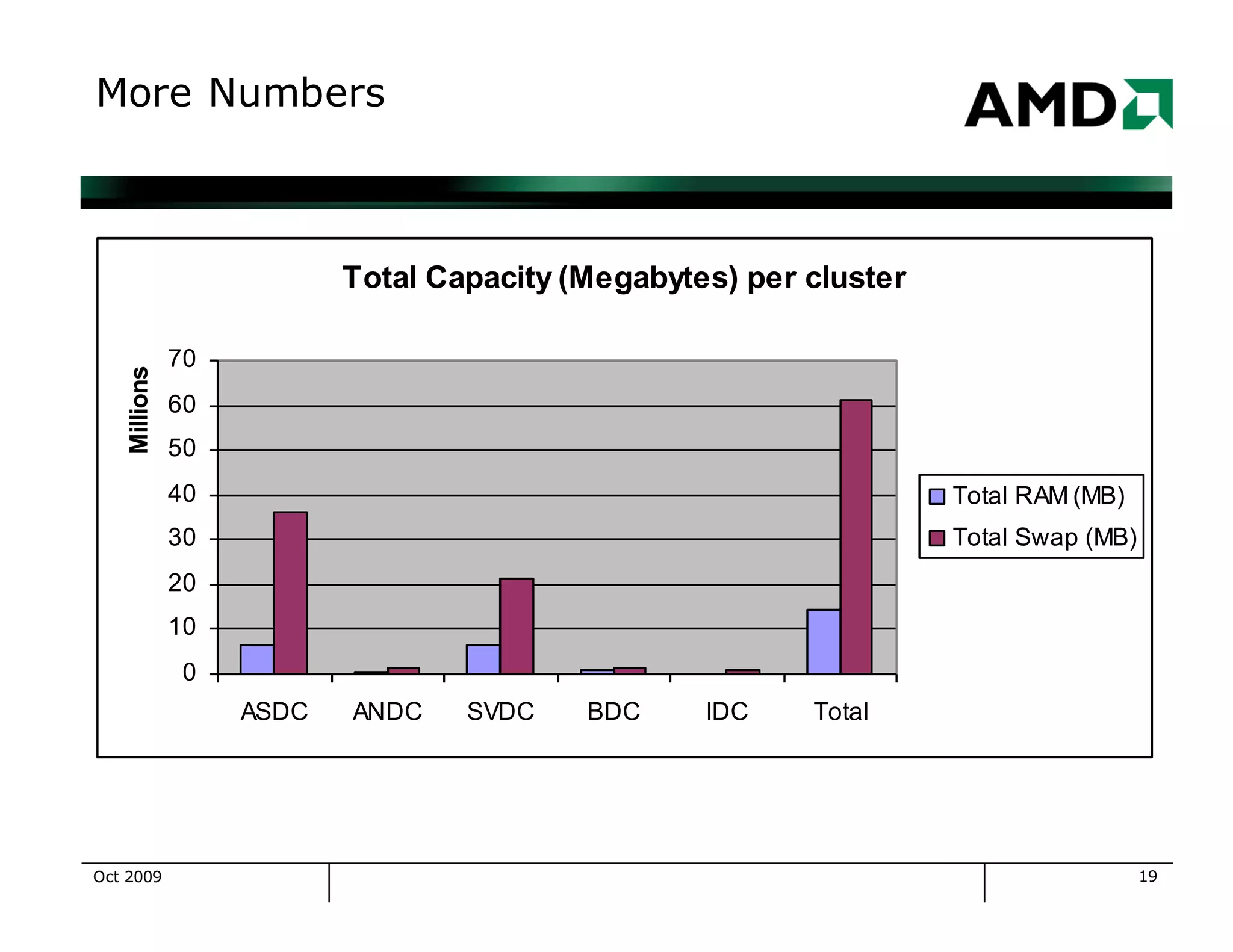
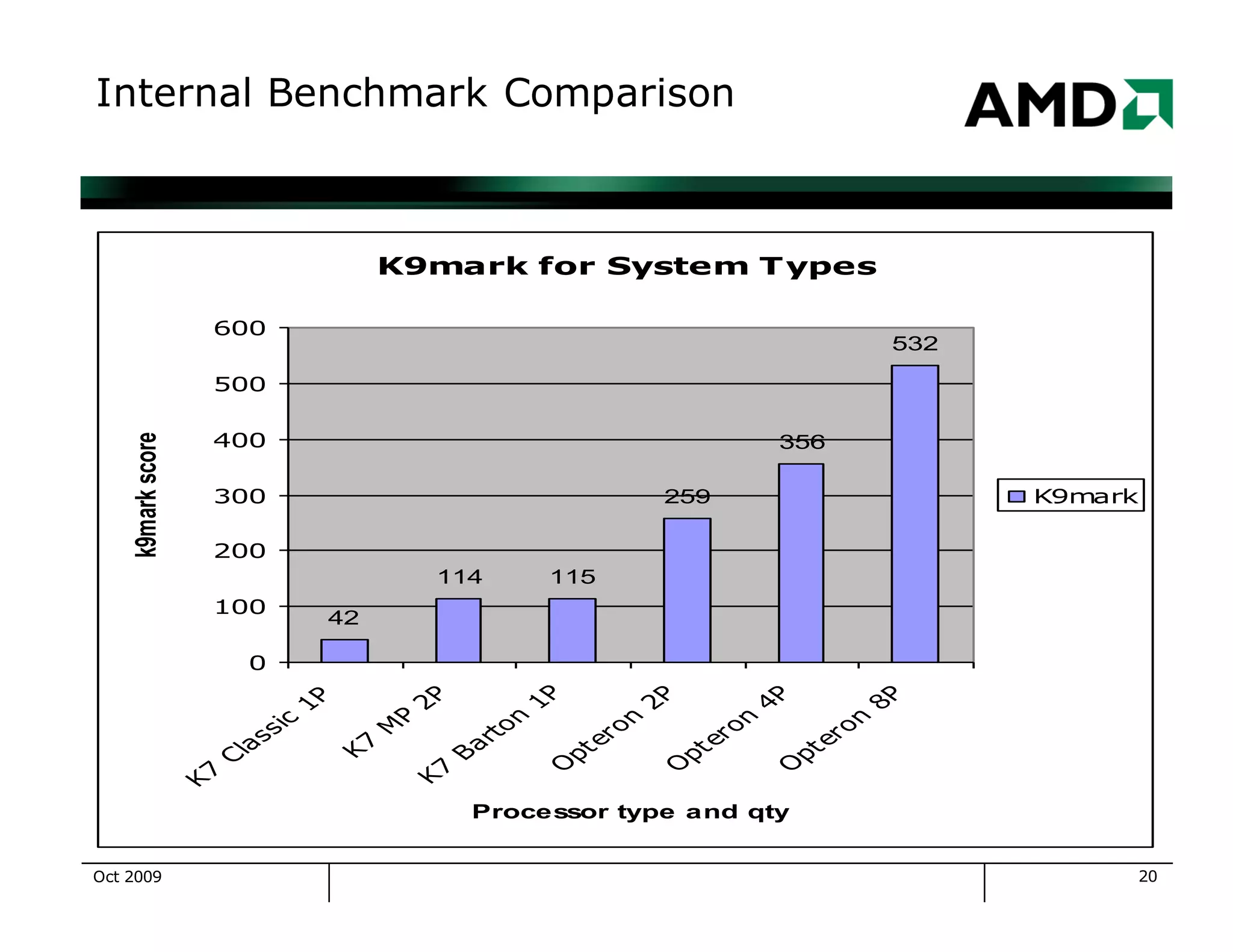
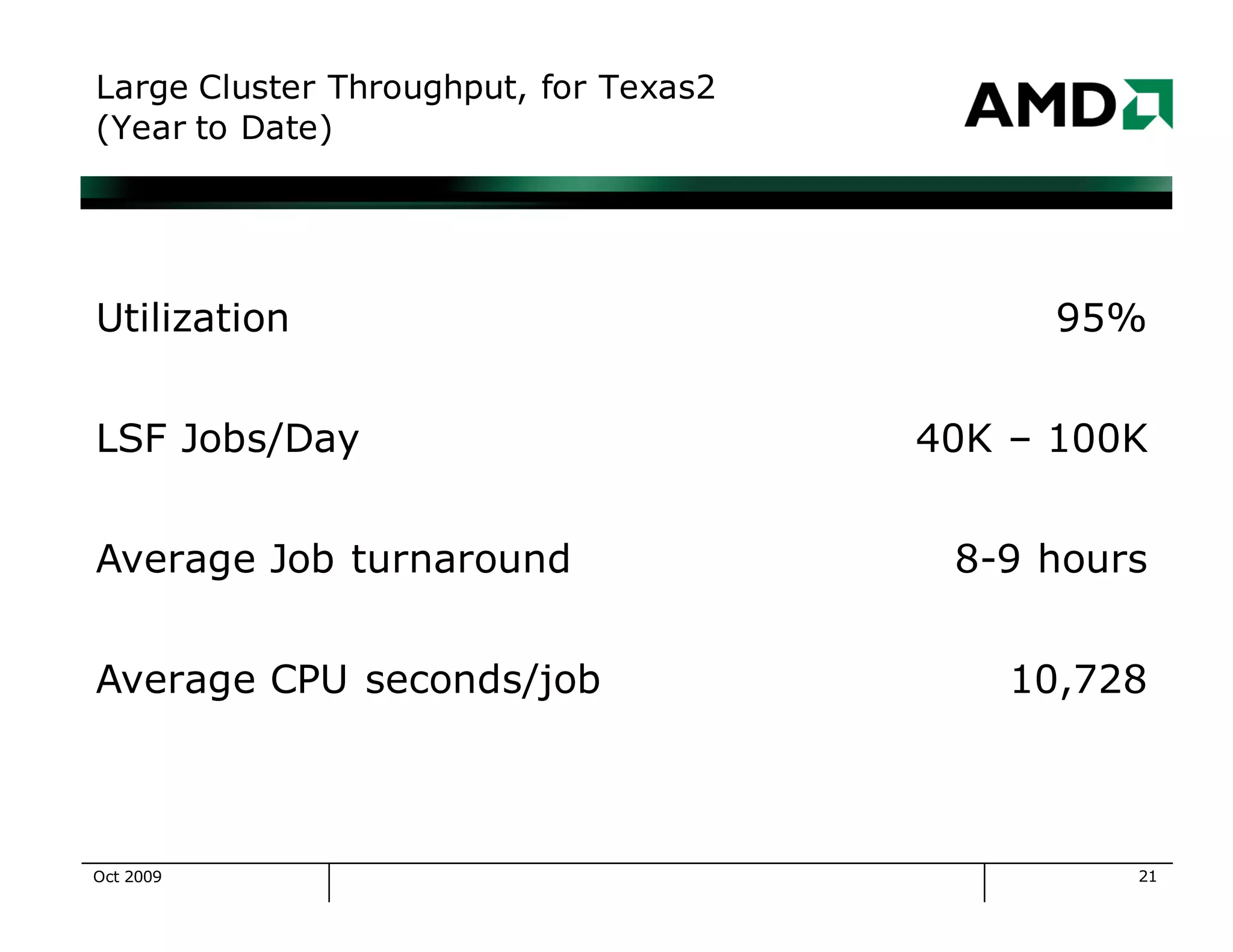
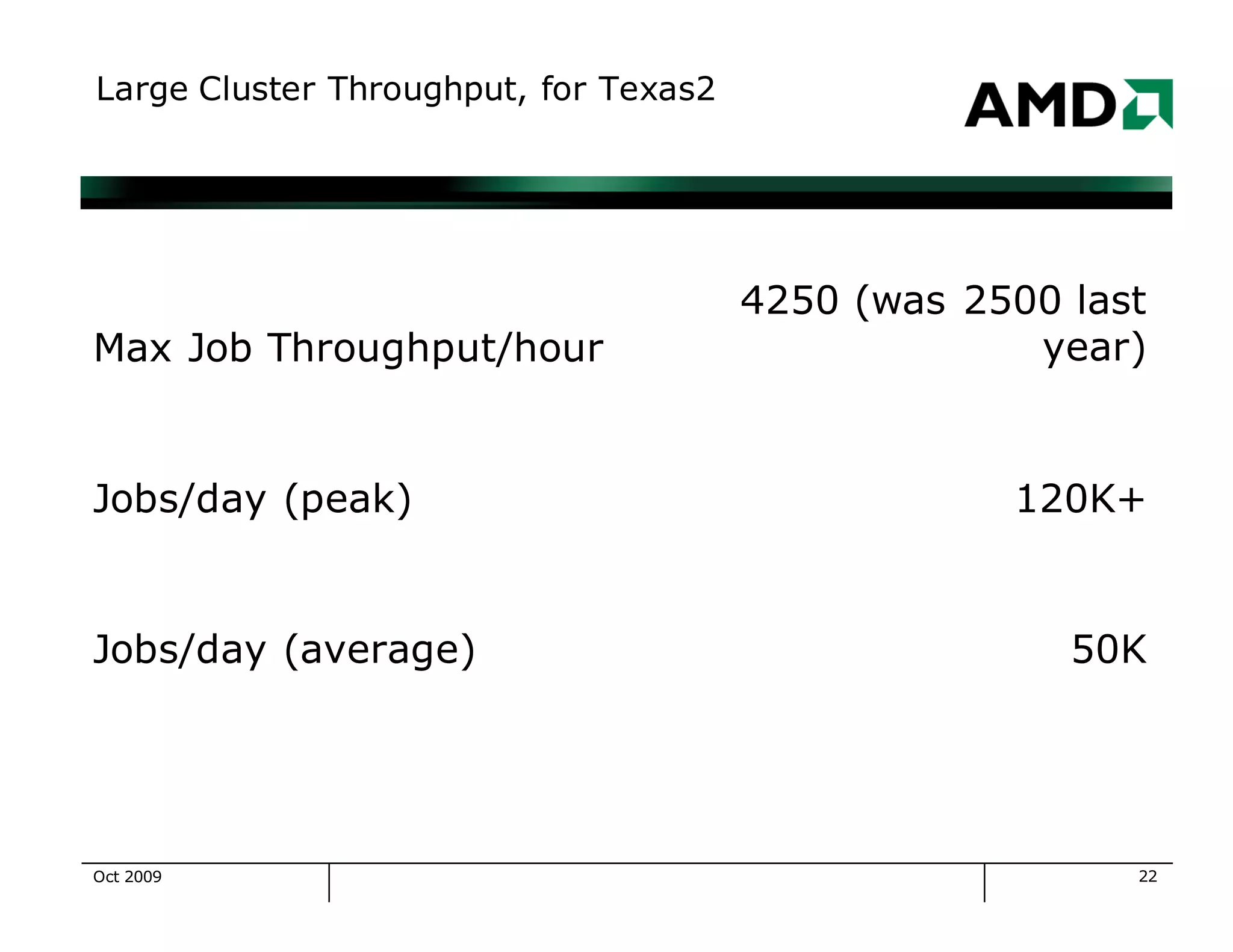


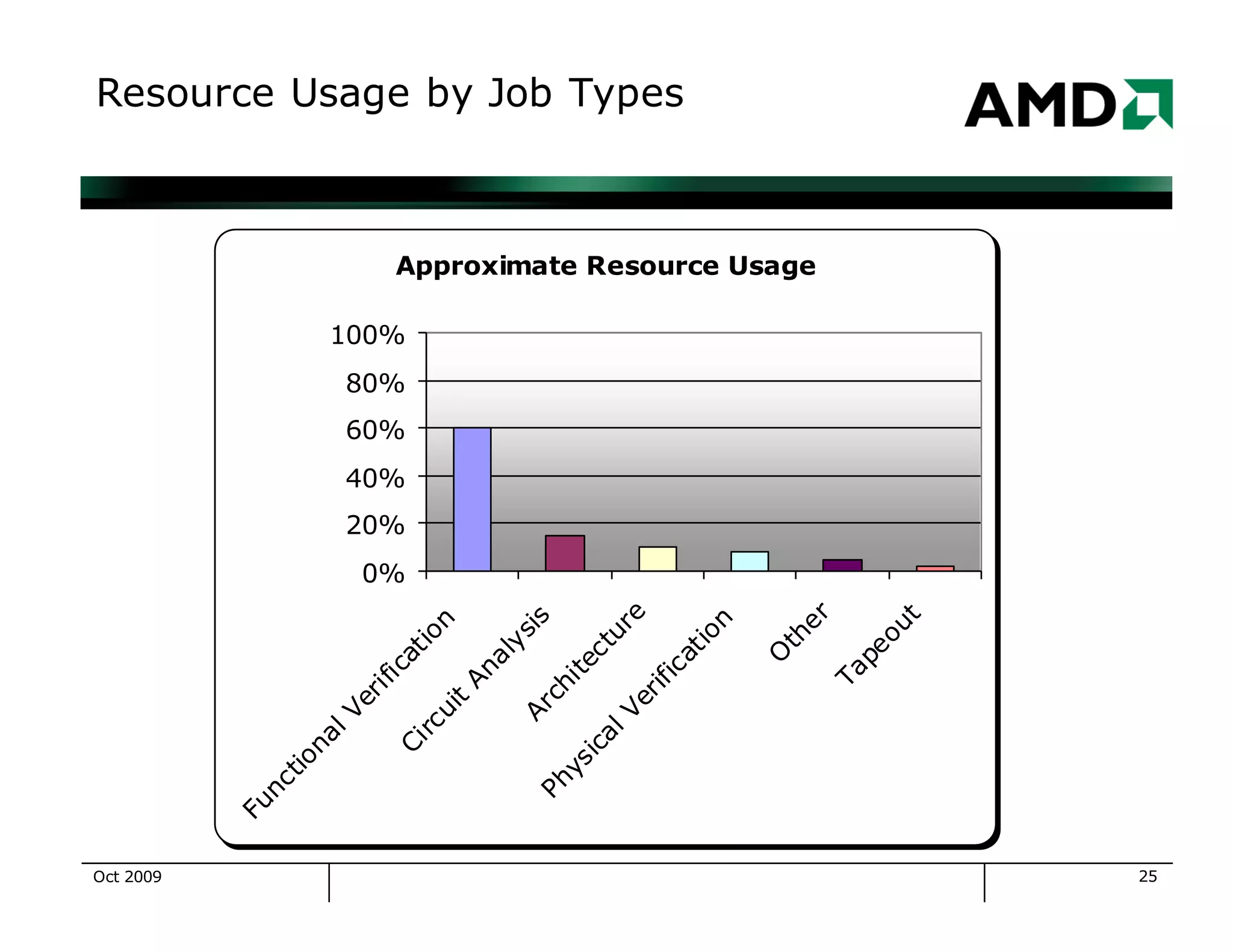













The document outlines the evolution and management of AMD's compute clusters, highlighting their use in developing microprocessor designs efficiently. It details historical transitions in hardware and software, challenges faced, and best practices for management. Additionally, it includes statistics on cluster size, job types, and system performance improvements over time.



















































































