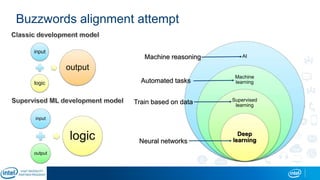
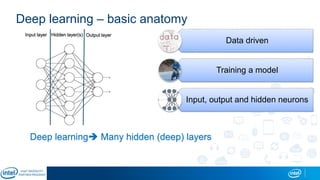
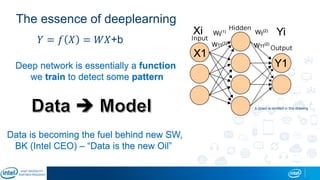
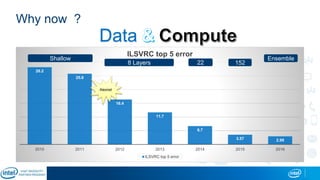
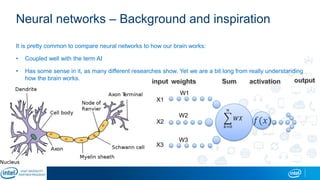
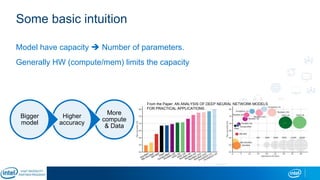
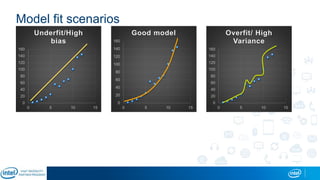
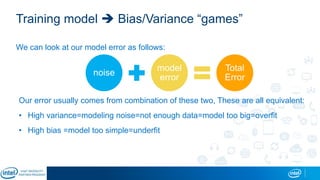
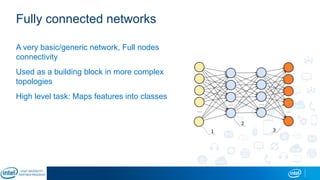
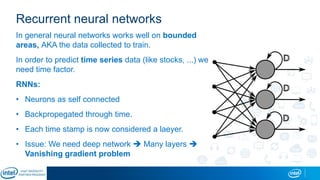
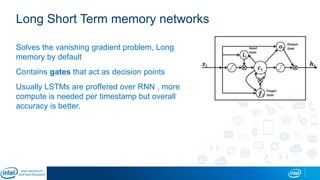
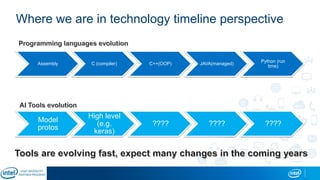
The document is a presentation by Eran Shlomo, a tech lead at Intel, focusing on deep learning, its various network topologies, and the tools and hardware involved in the field. It discusses the evolution of neural networks, challenges like overfitting and underfitting, and the importance of data in training models, emphasizing the rise of deep learning and its integration in technology. Additionally, it highlights cloud services, the competitive landscape of hardware for deep learning, and Intel's initiatives in the AI sector.