Downloaded 22 times













![my_aggregation:
24
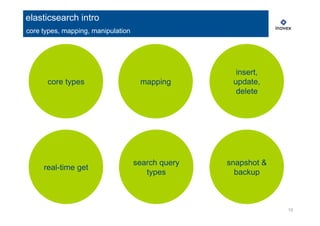
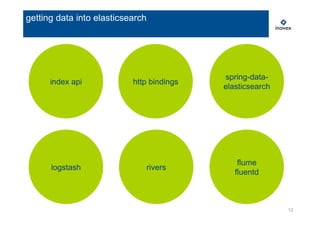
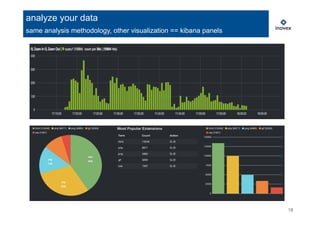
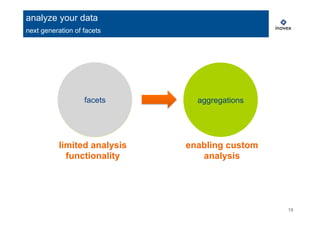
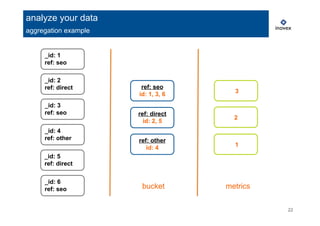
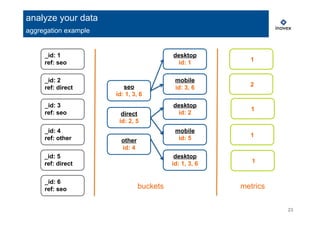
analyze your data
customize your analysis with nested aggregators
"aggregations": {!
!"<aggregation_name>": {!
! !"<aggregation_type>": {!
! ! !<aggregation_body>!
! !},!
! !["aggregations": { [<sub_aggregation>]* }]!
!}!
![,"<aggregation_name_2>": { … }]*!
}!
bucket 1 bucket 2 bucket n metrics…](https://image.slidesharecdn.com/real-time-data-analytics-mit-elasticsearch-bernhard-pflugfelder-jax2014-140516081126-phpapp01/85/Real-time-Data-Analytics-mit-Elasticsearch-24-320.jpg)


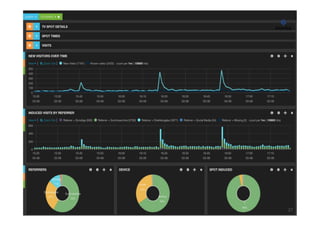



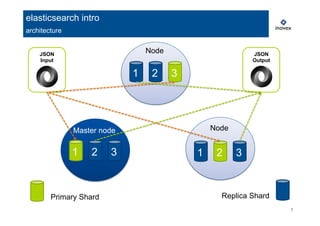
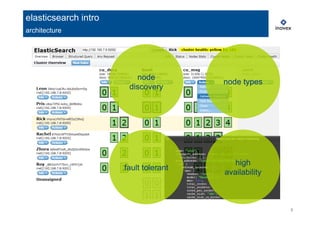
The document provides an overview of real-time data analytics using Elasticsearch, covering its architecture, data ingestion methods, analysis capabilities, and visualization tools. It discusses key components such as Logstash for data collection and management, as well as the integration of Elasticsearch with Hadoop for enhanced analytics. Additionally, it highlights the use of aggregations for data analysis and the visualization capabilities through Kibana.






















































![[Virtual Meetup] Using Elasticsearch as a Time-Series Database in the Endpoin...](https://cdn.slidesharecdn.com/ss_thumbnails/2020-200909133305-thumbnail.jpg?width=640&height=640&fit=bounds)




















































