Download to read offline





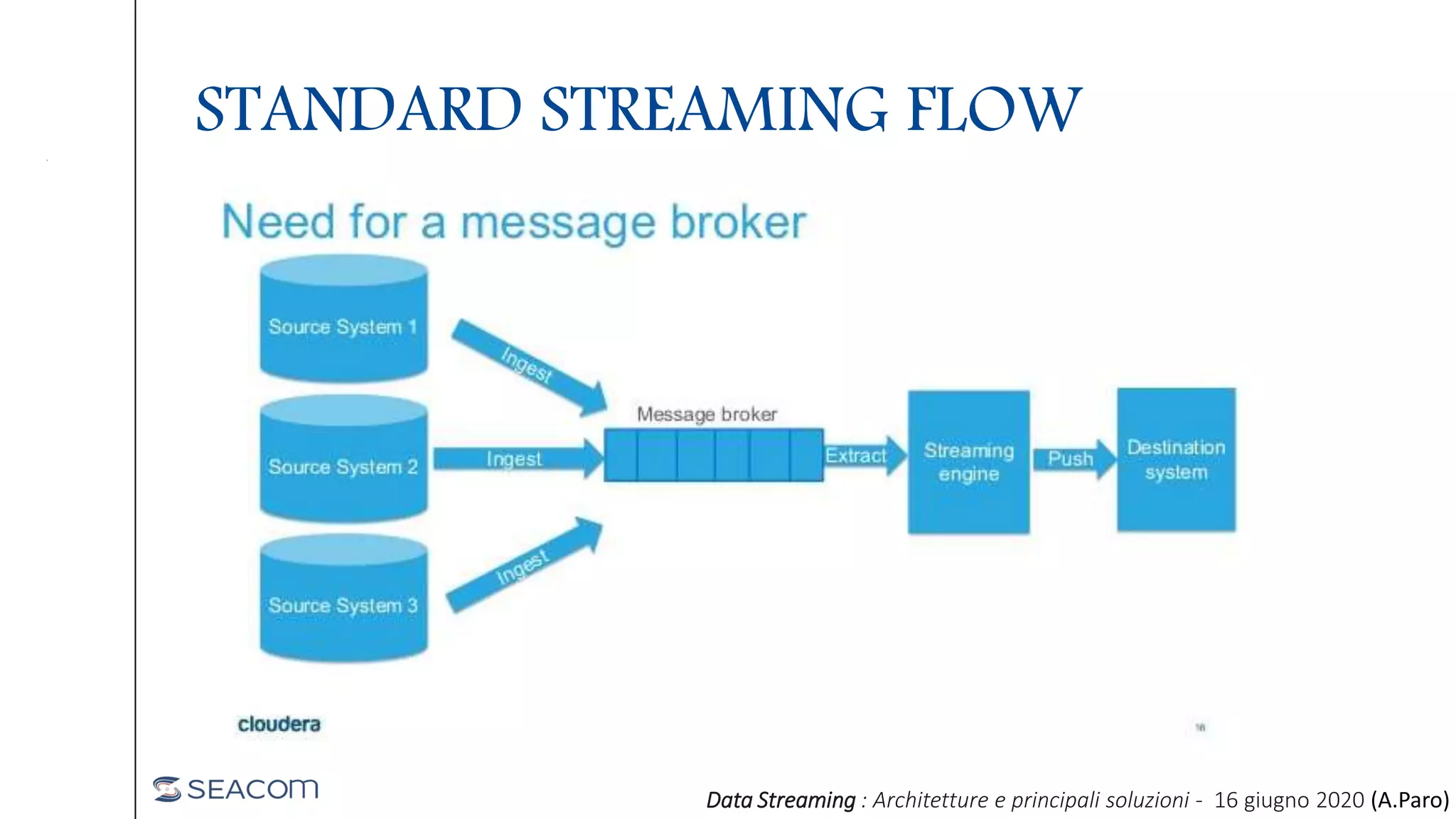
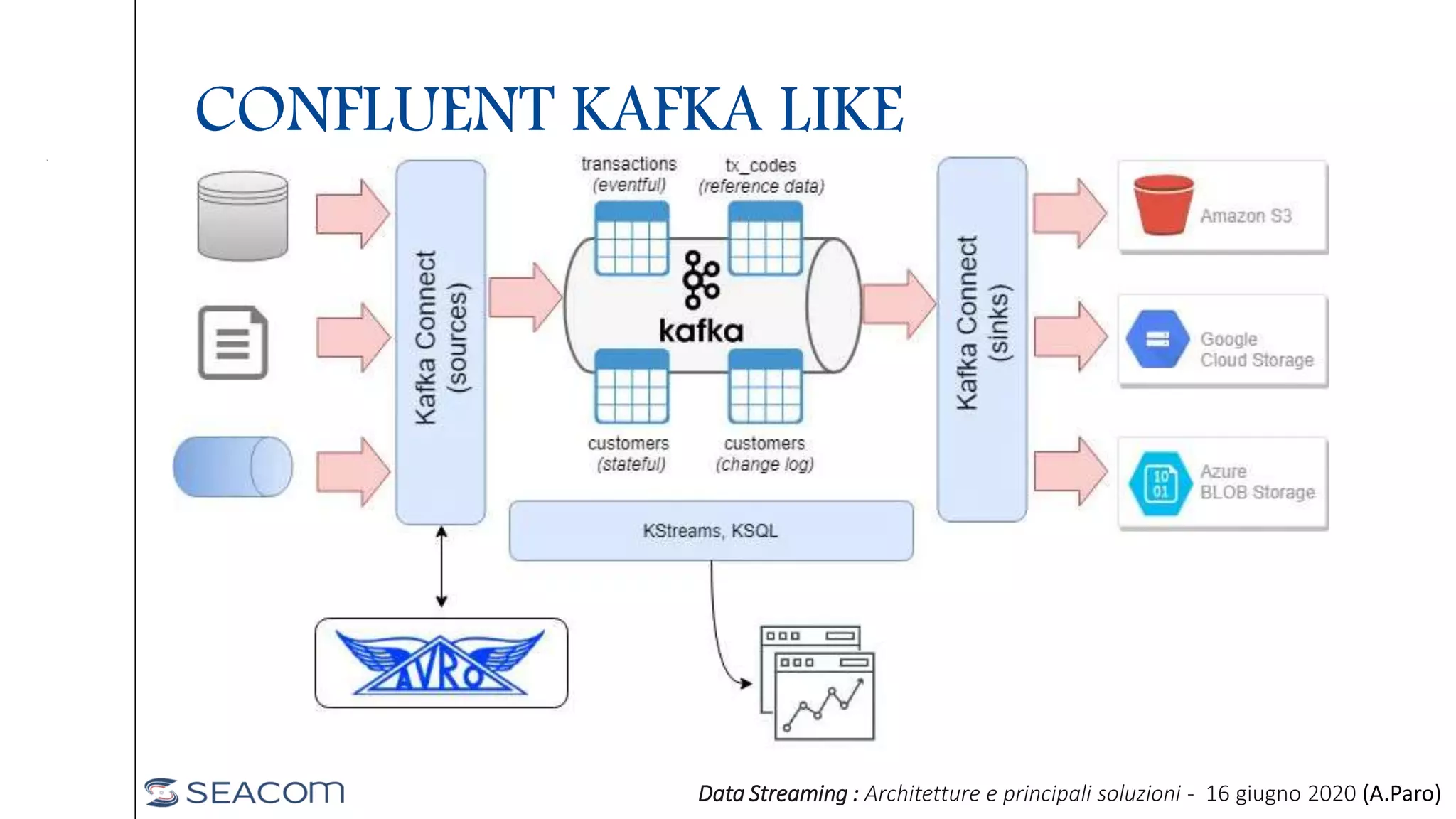

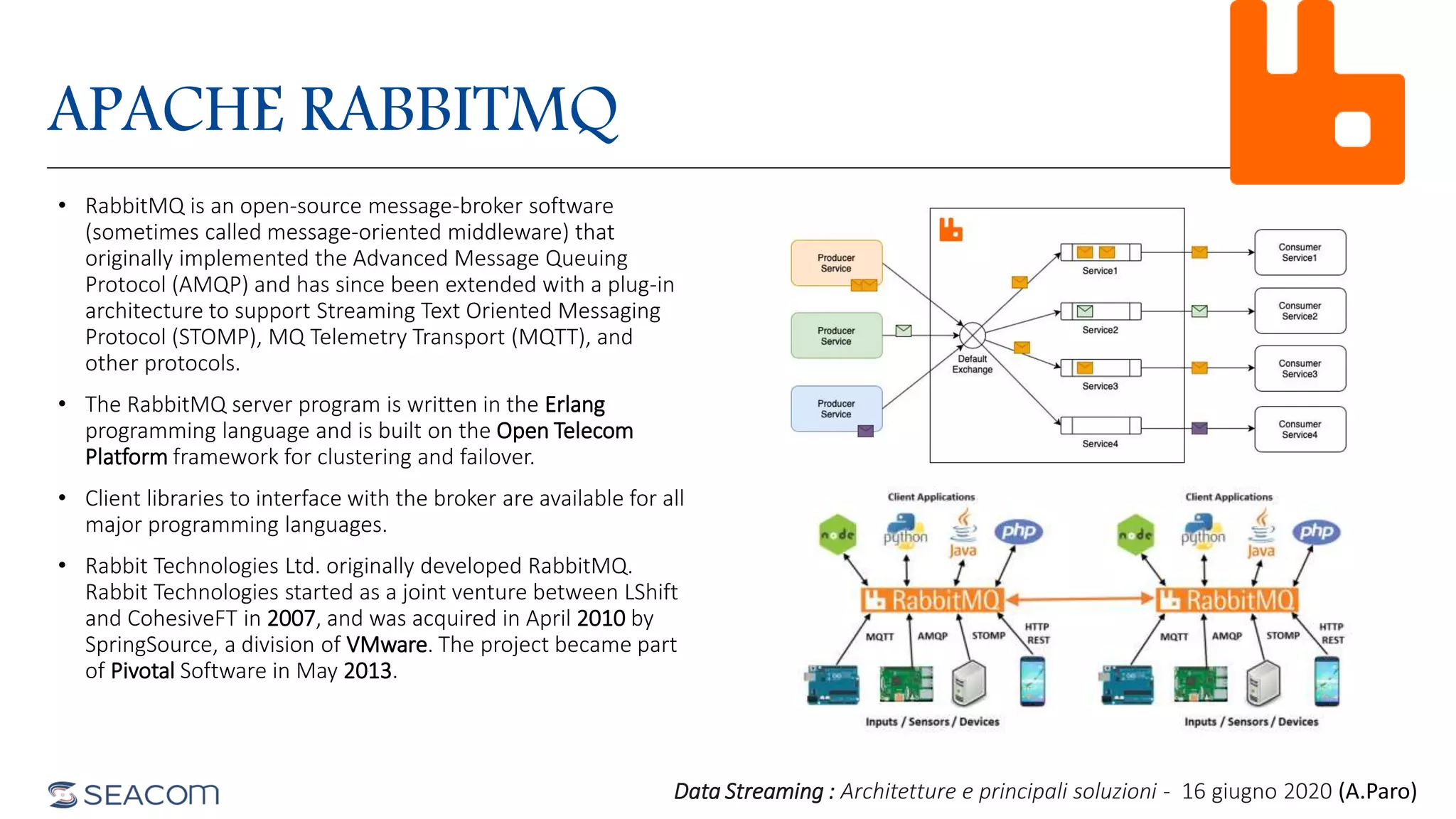
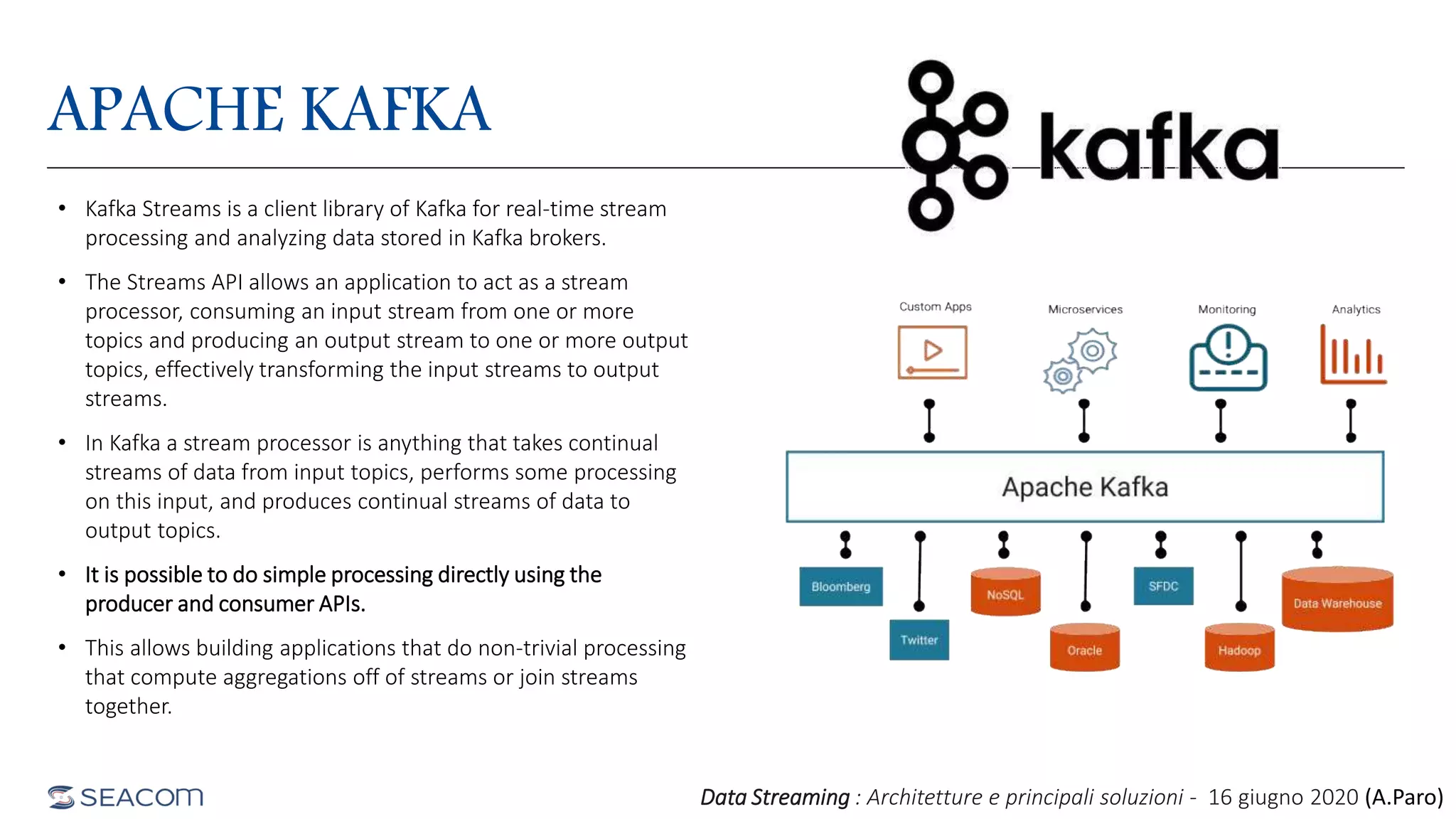
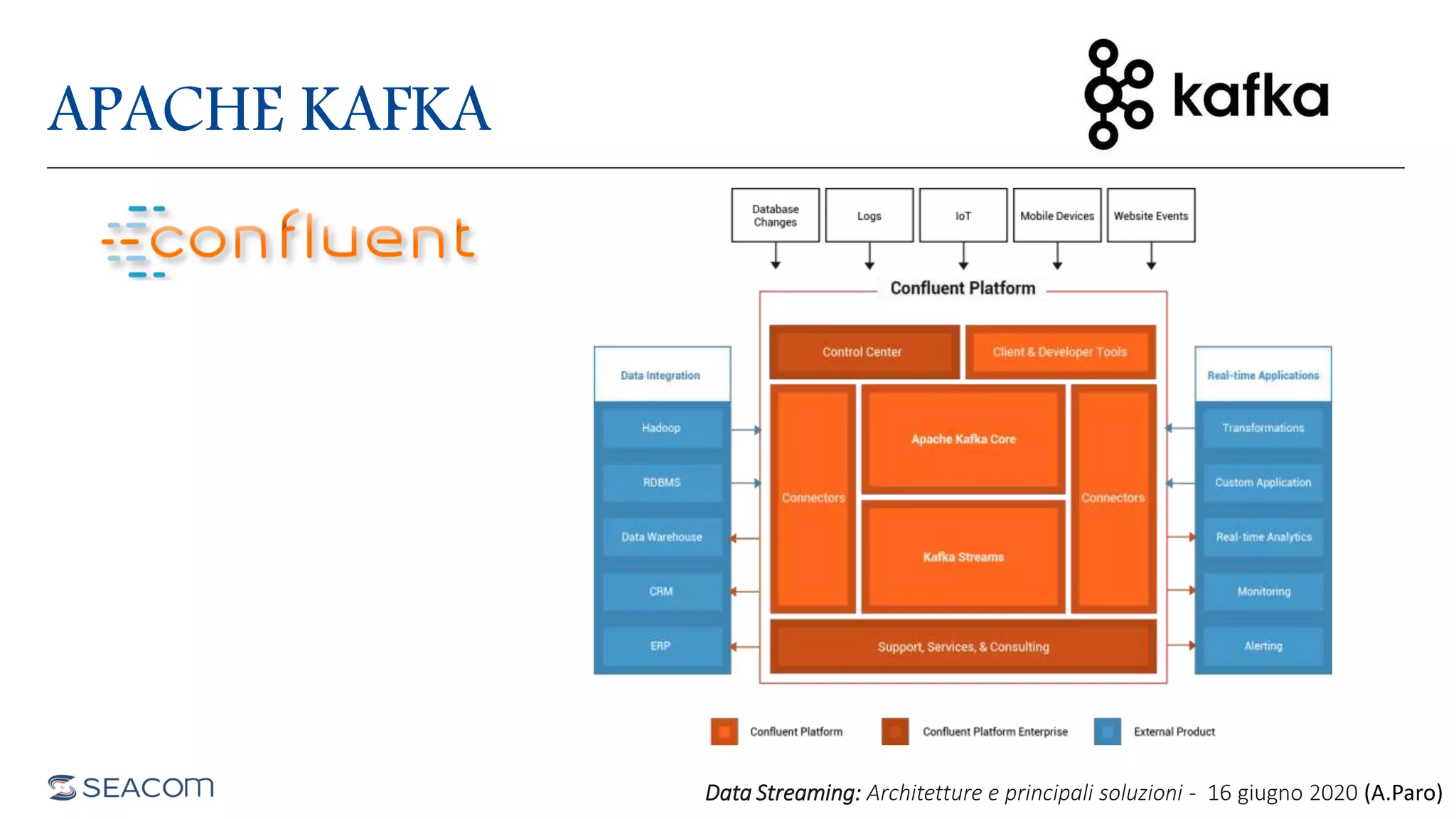
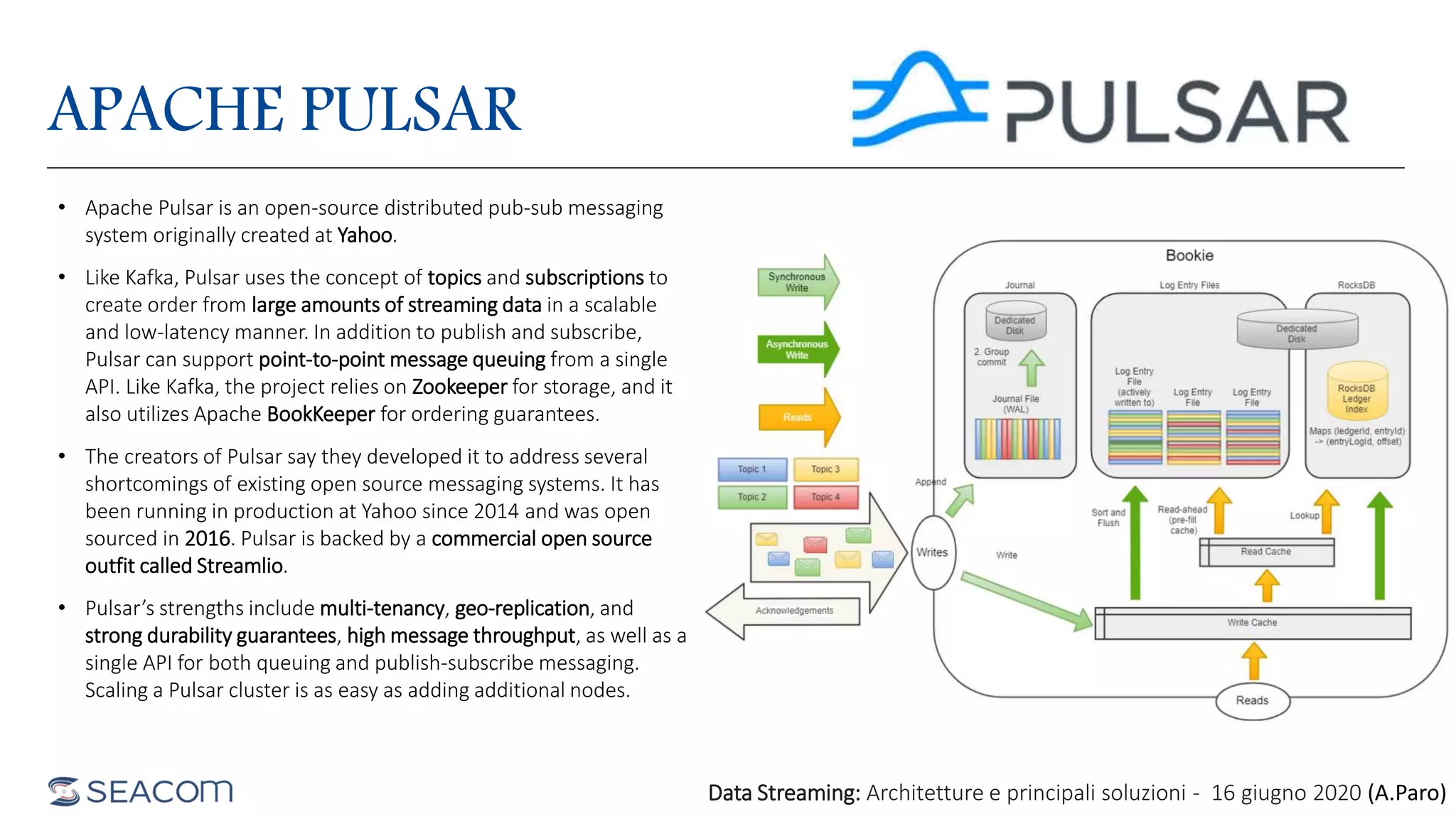


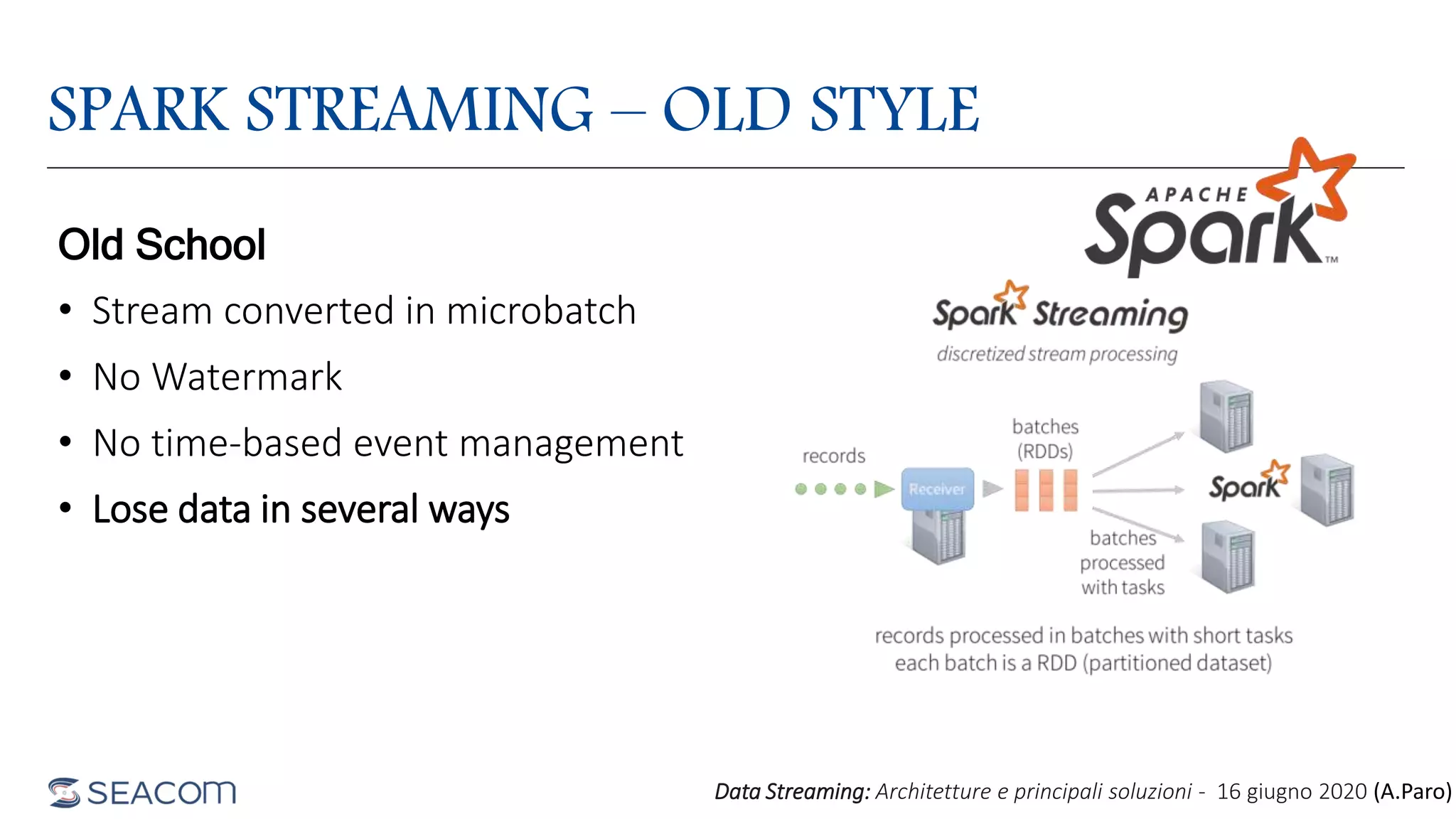
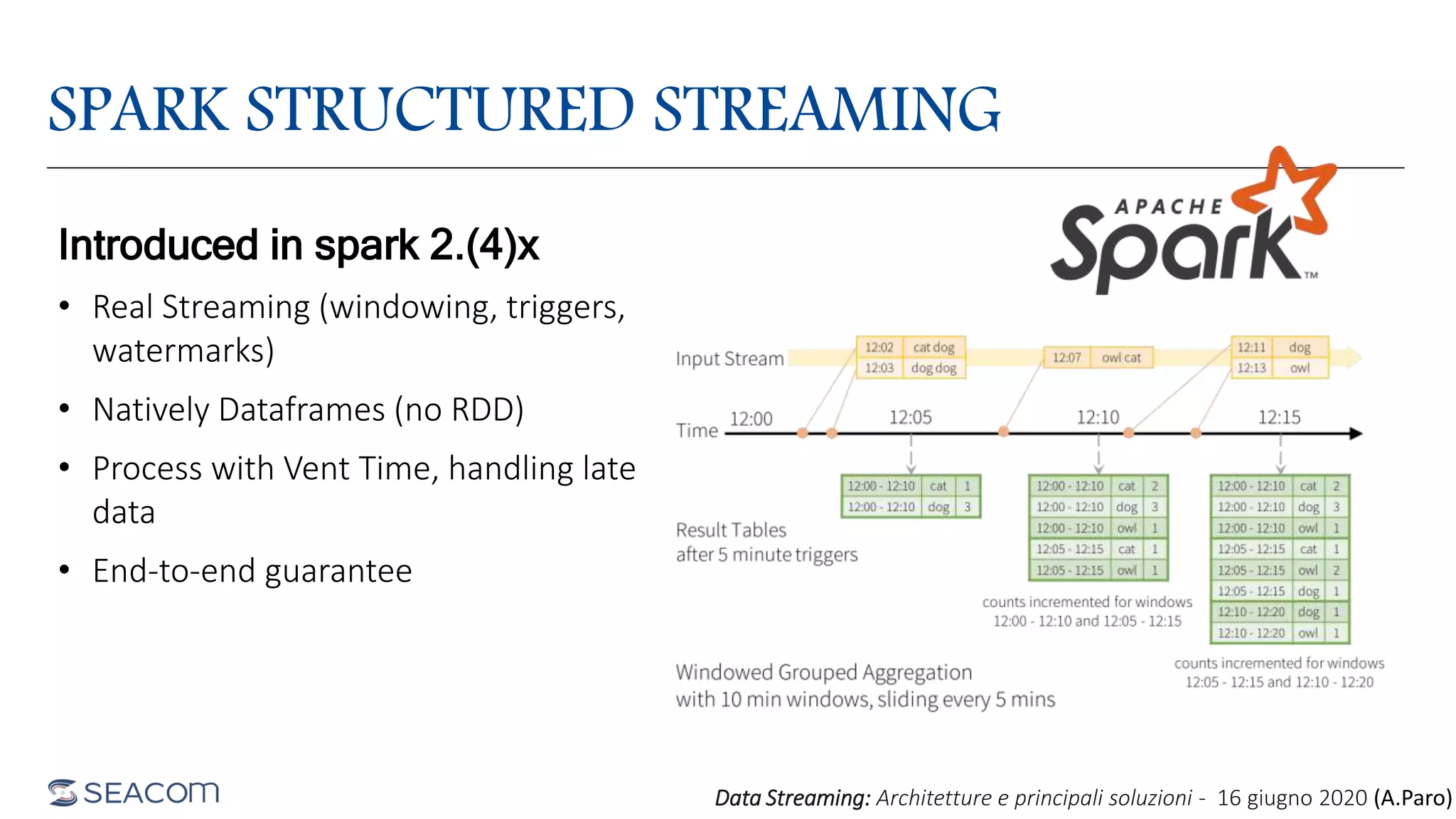
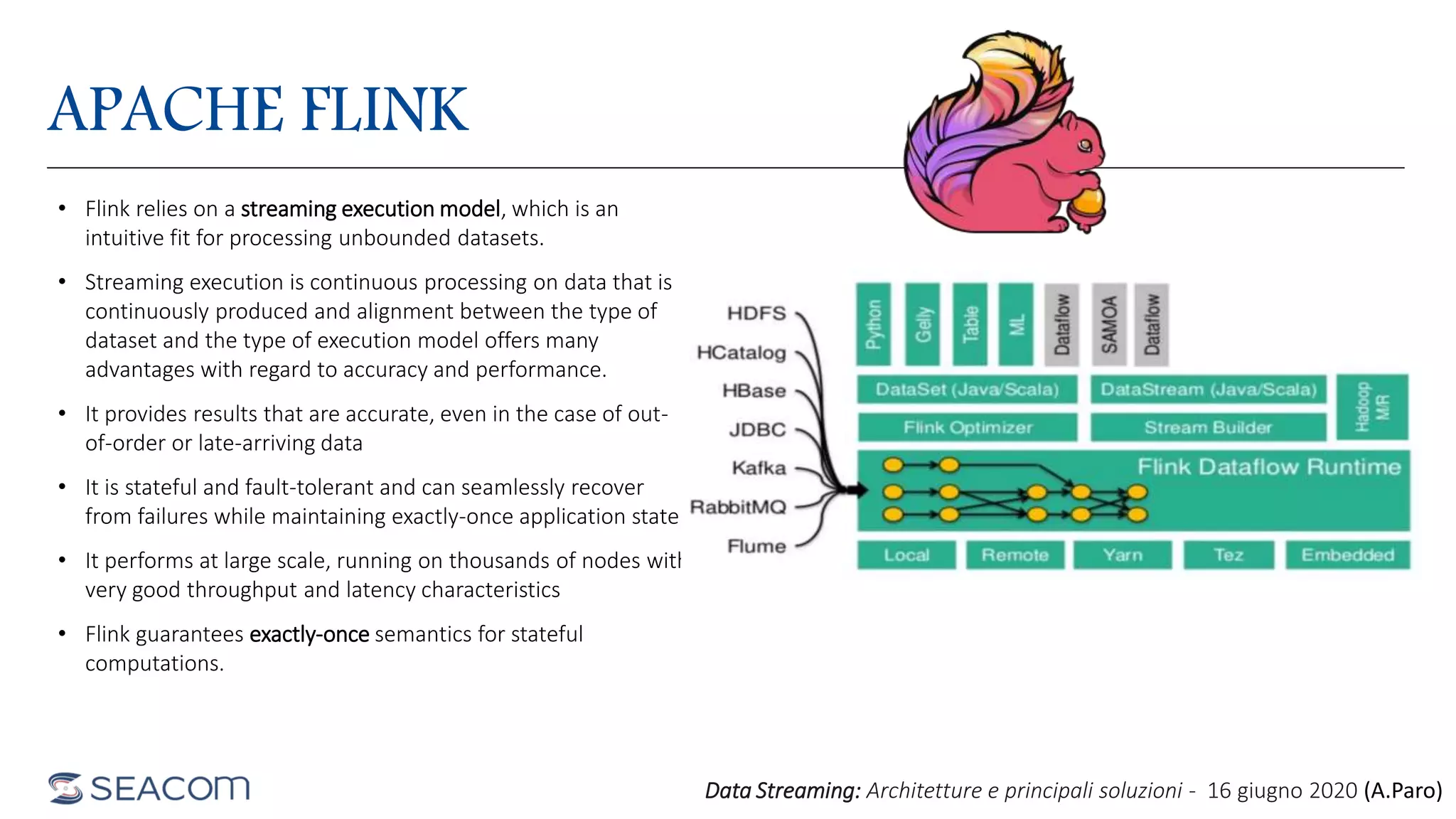



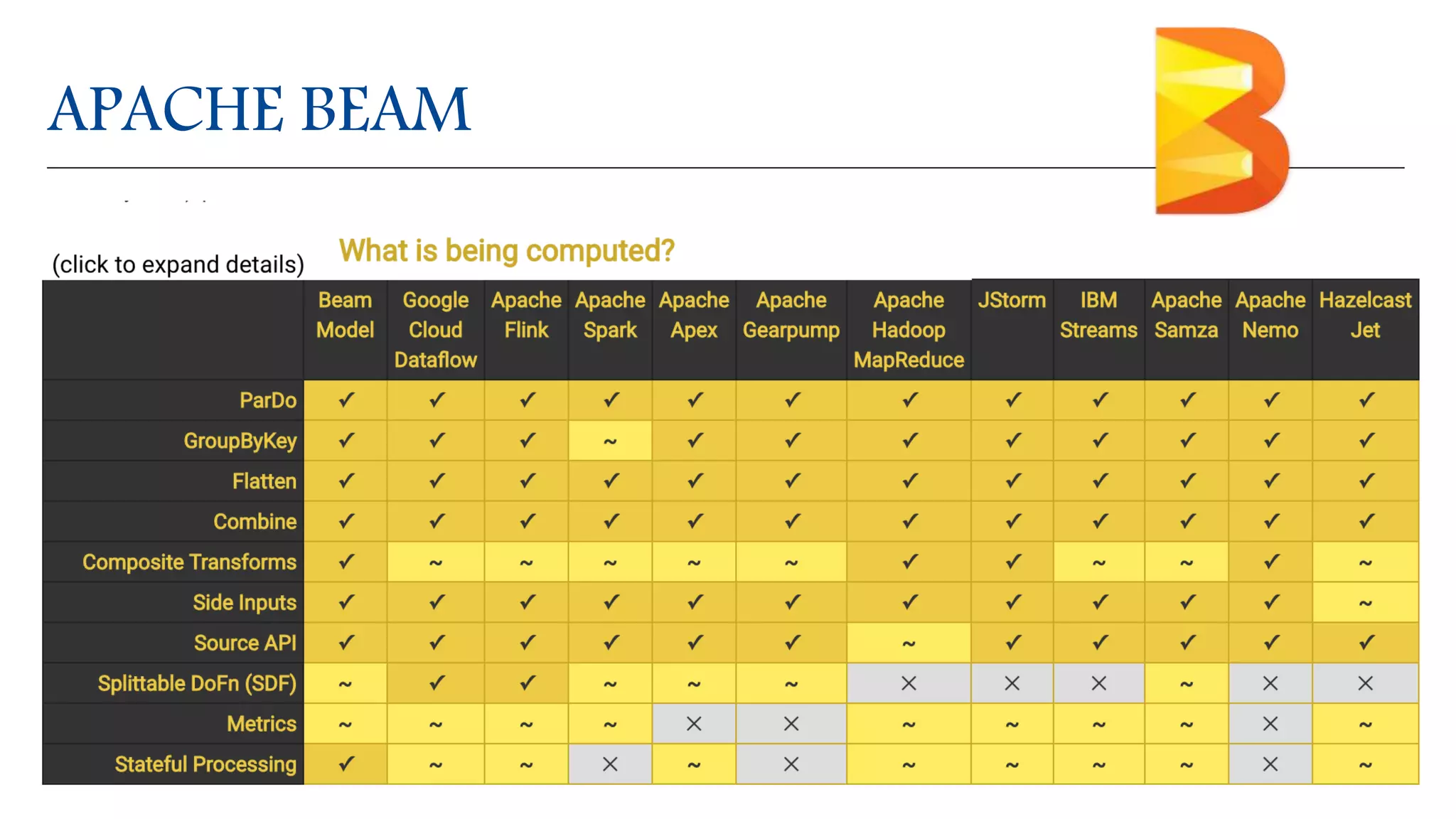




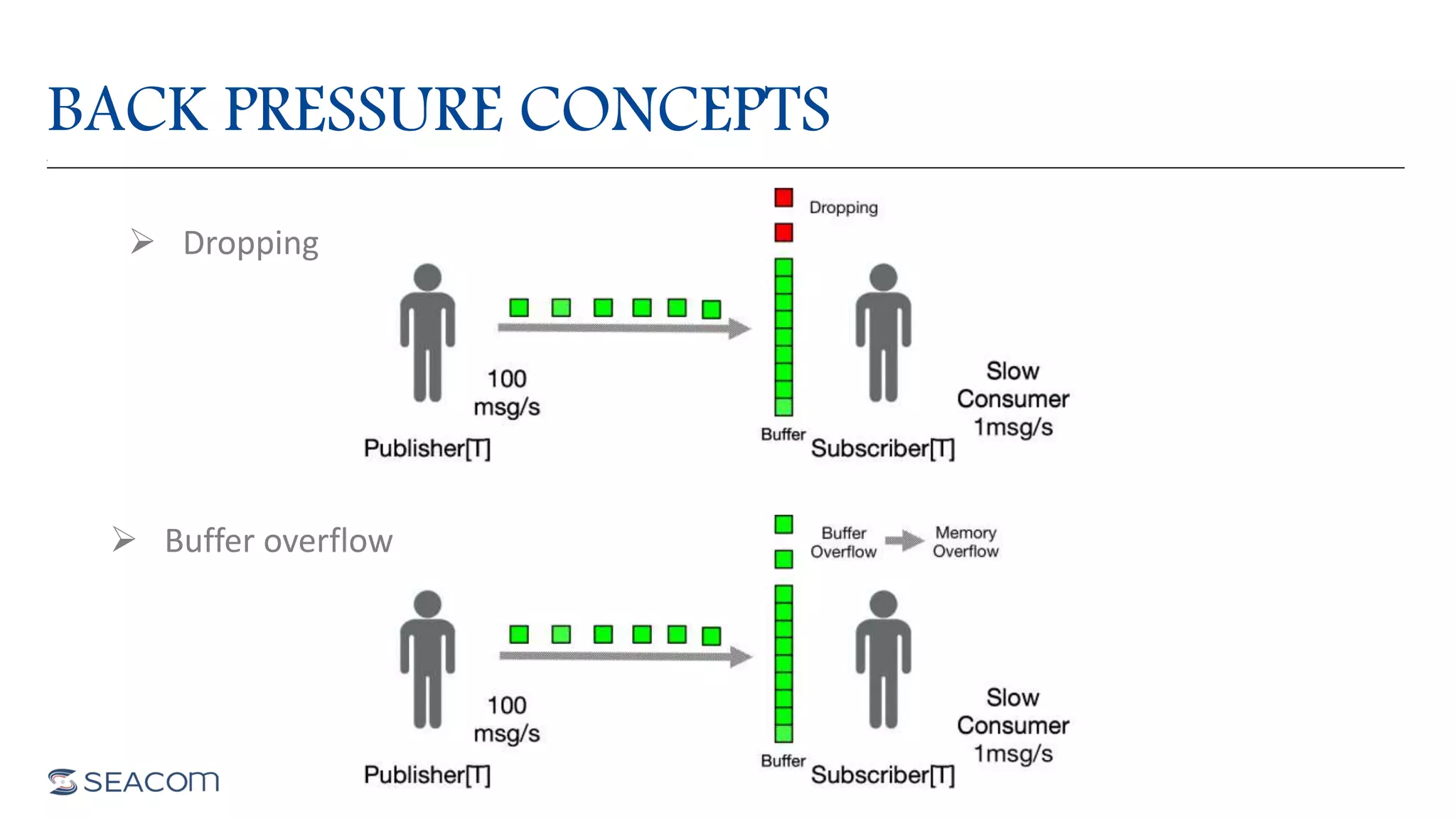
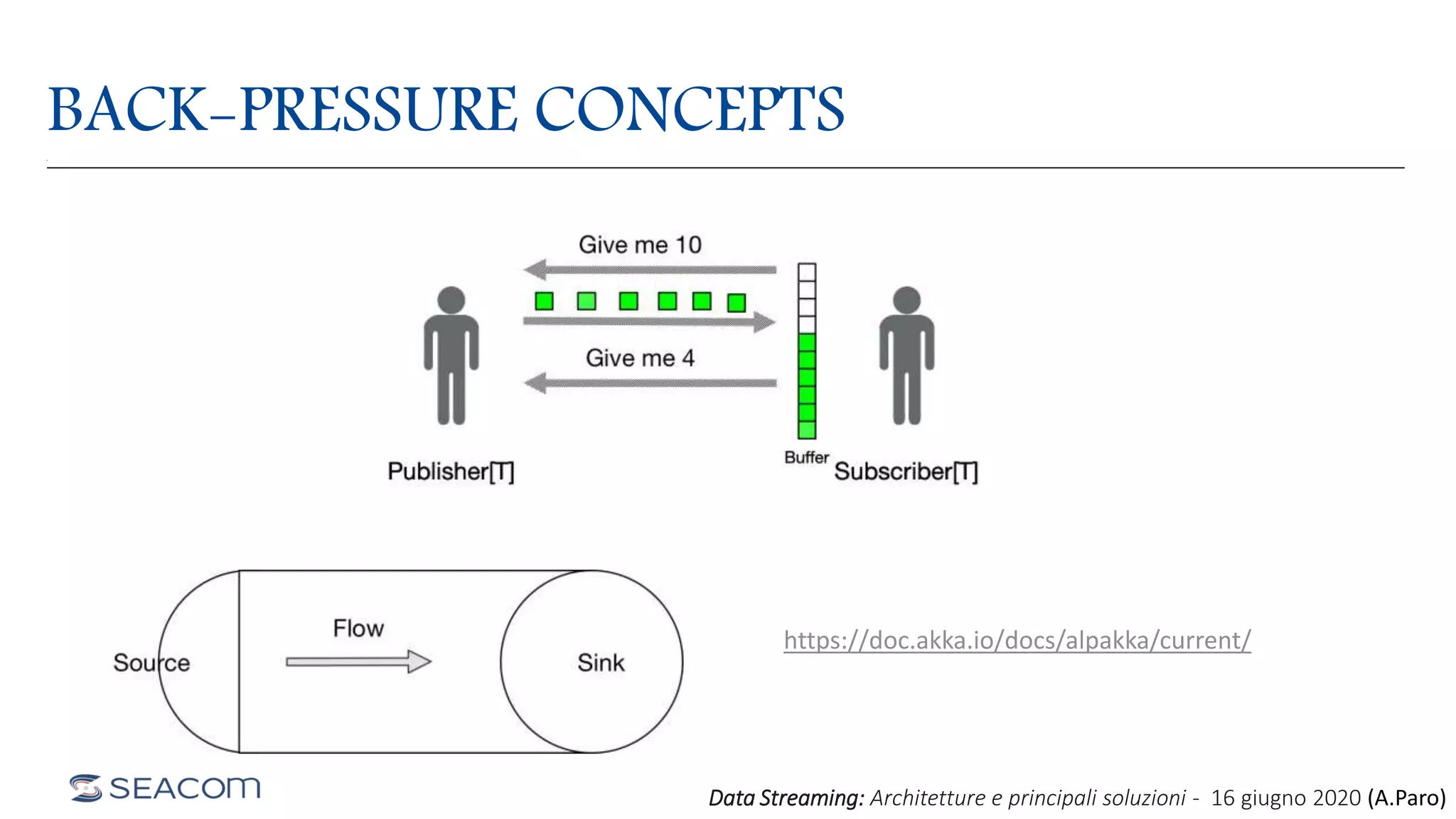




- The document profiles Alberto Paro and his experience including a Master's Degree in Computer Science Engineering from Politecnico di Milano, experience as a Big Data Practise Leader at NTTDATA Italia, authoring 4 books on ElasticSearch, and expertise in technologies like Apache Spark, Playframework, Apache Kafka, and MongoDB. He is also an evangelist for the Scala and Scala.JS languages. The document then provides an overview of data streaming architectures, popular message brokers like Apache Kafka, RabbitMQ, and Apache Pulsar, streaming frameworks including Apache Spark, Apache Flink, and Apache NiFi, and streaming libraries such as Reactive Streams.









































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

