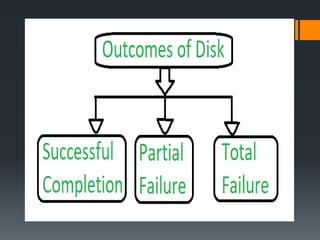
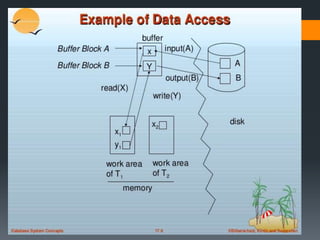
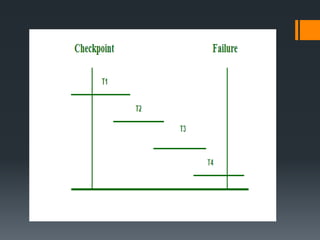
The document discusses recovery systems in relational database management systems (RDBMS). It covers various topics related to recovery including failure classification, storage structures, log-based recovery, shadow paging, recovery with concurrent transactions, and checkpoints. Recovery aims to ensure atomicity and recover the database to a consistent state after failures through techniques like undoing and redoing transactions by examining the transaction log.