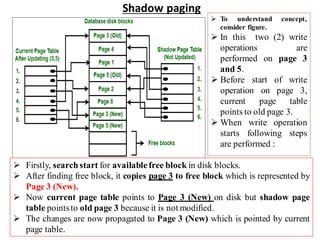
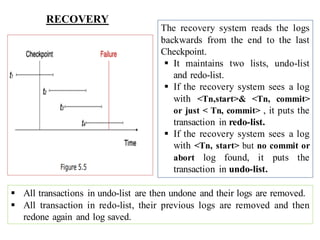
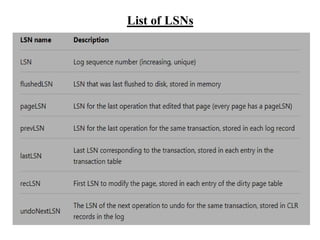
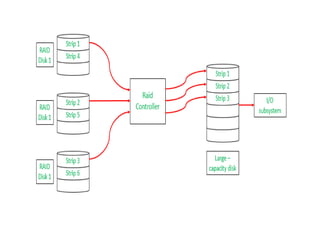
The document discusses different techniques for database recovery including rollback/undo recovery, commit/redo recovery, and checkpoint recovery. Rollback/undo recovery undoes the changes of an uncommitted transaction using log records, while commit/redo recovery reapplies the changes of a committed transaction using log records to restore the most recent consistent state. Checkpoint recovery periodically saves the database state to a checkpoint file to speed up recovery. The document also discusses transaction failure, system crash, log-based recovery using write-ahead logging, and shadow paging recovery using two page tables.