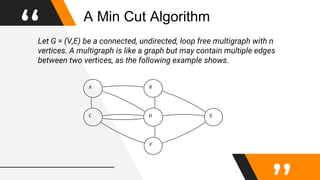
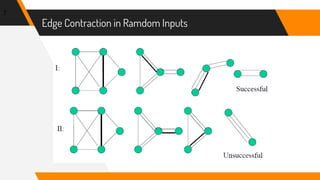
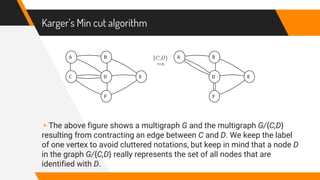
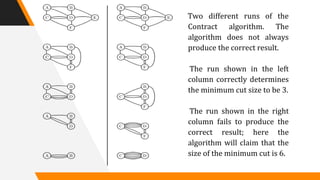
This document discusses a randomized algorithm to solve the min-cut problem using Karger's algorithm, which operates on connected, undirected multigraphs. The algorithm randomly contracts edges to estimate the minimum cut size, with a high probability of accuracy when executed multiple times. The analysis highlights the algorithm's efficiency, achieving results in O(n^2 log n) operations, compared to deterministic algorithms which are generally slower.








![Remarks
The running time of the best deterministic minimum cut
algorithm is O(nm + n2 logn), where m denotes the number of
edges, that is, in the labeled graph representation the running
time is at most O(n3), see for instance [2]. It turns out that size
of the minimum cut can be determined with high probability in
O(n2 log3 n) steps using a refined version of the contraction
algorithm, see [1].](https://image.slidesharecdn.com/randomizedalgorithm-mincutproblemanditssolutionusingkargersalgorithm-180626075203/85/Randomized-algorithm-min-cut-problem-and-its-solution-using-karger-s-algorithm-13-320.jpg)































































