Download as PDF, PPTX




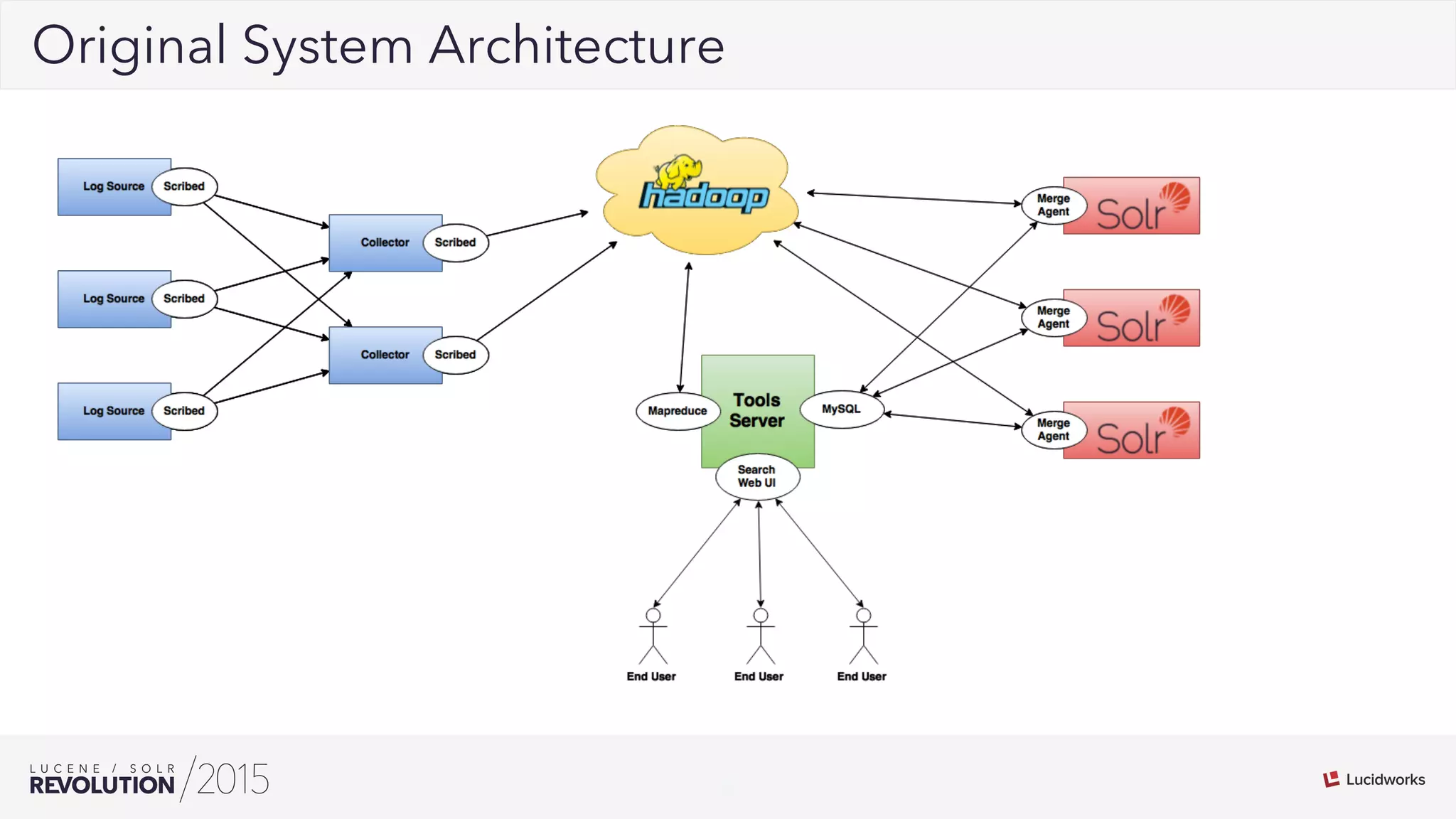
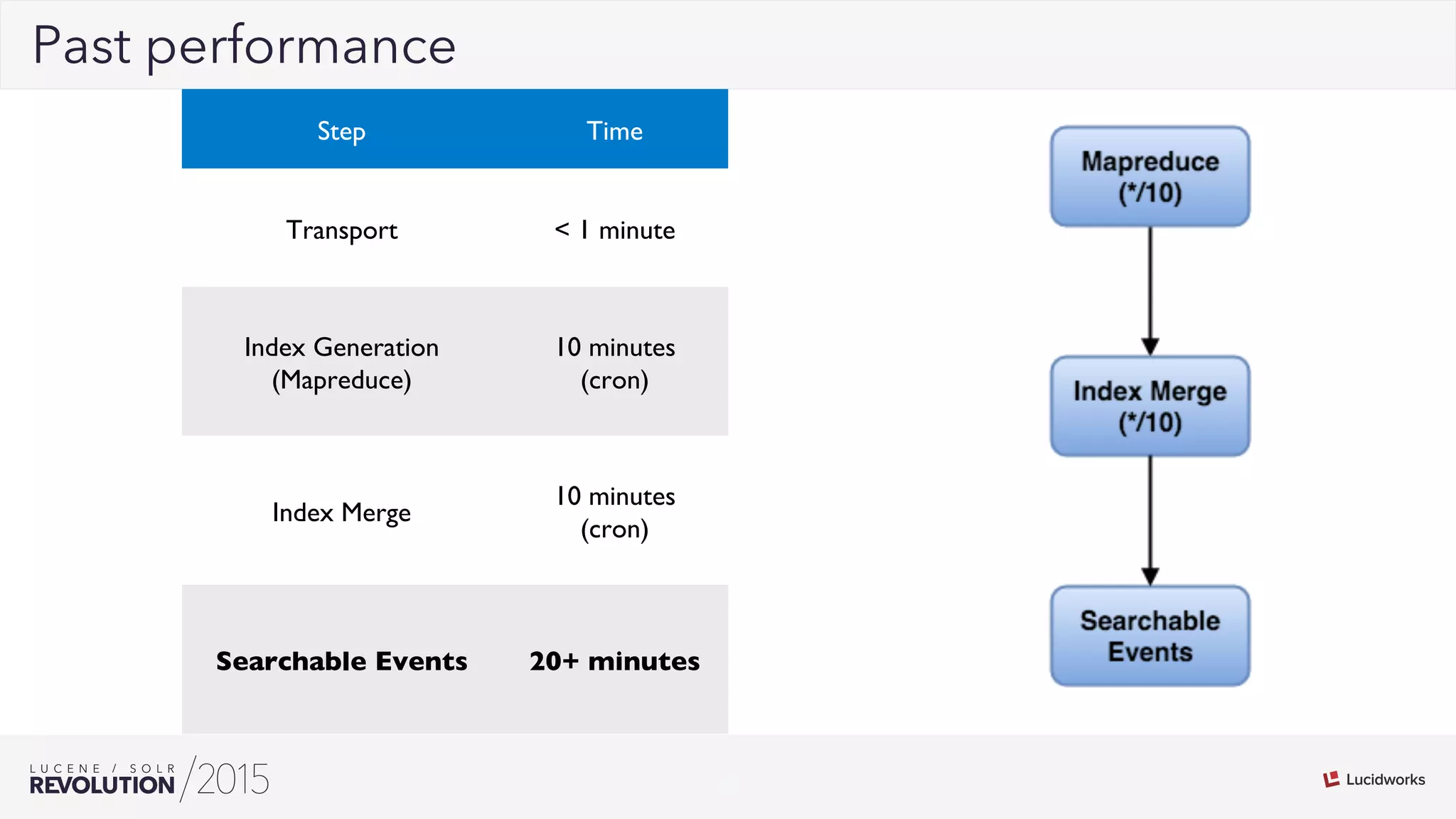


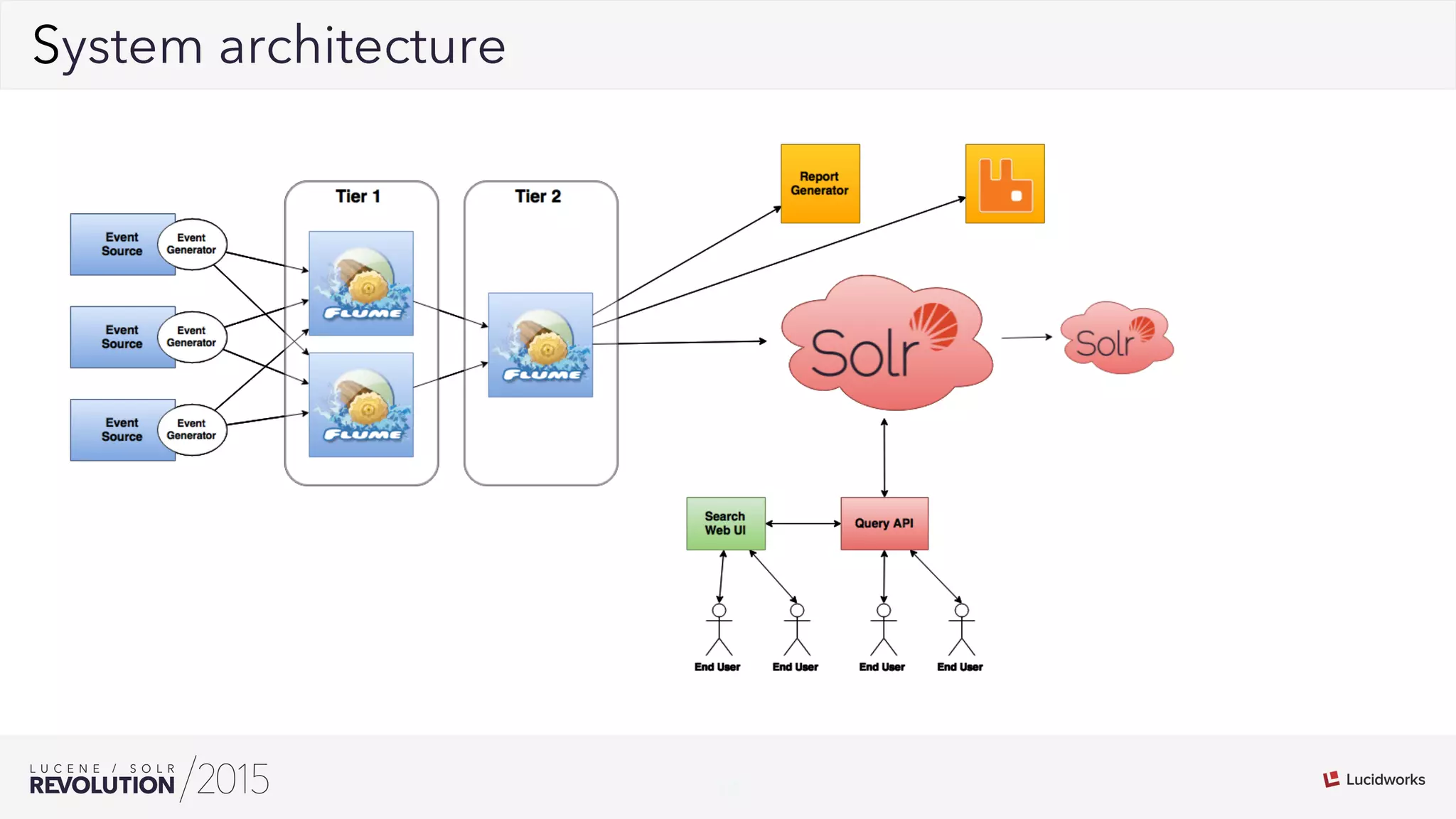

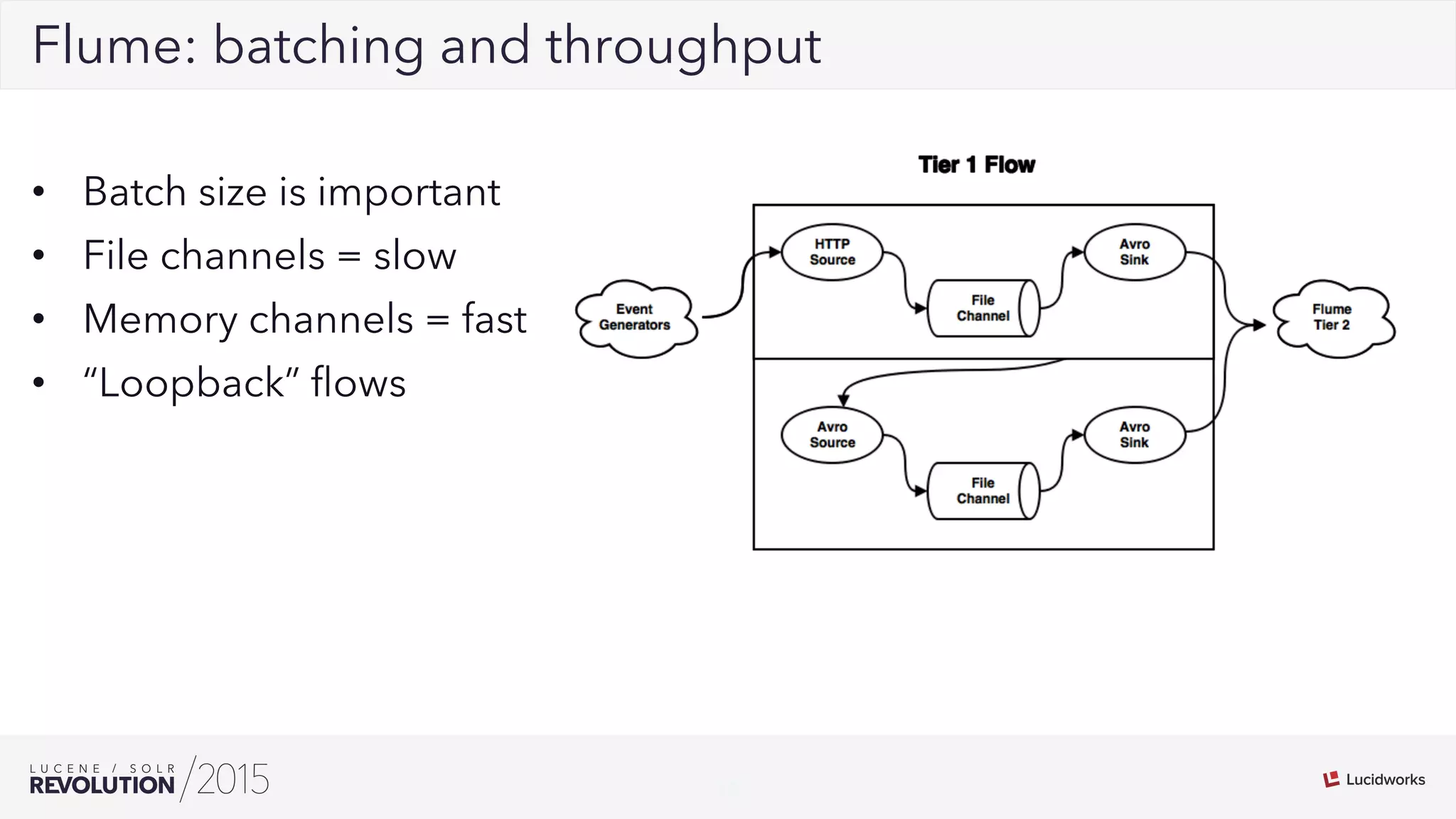
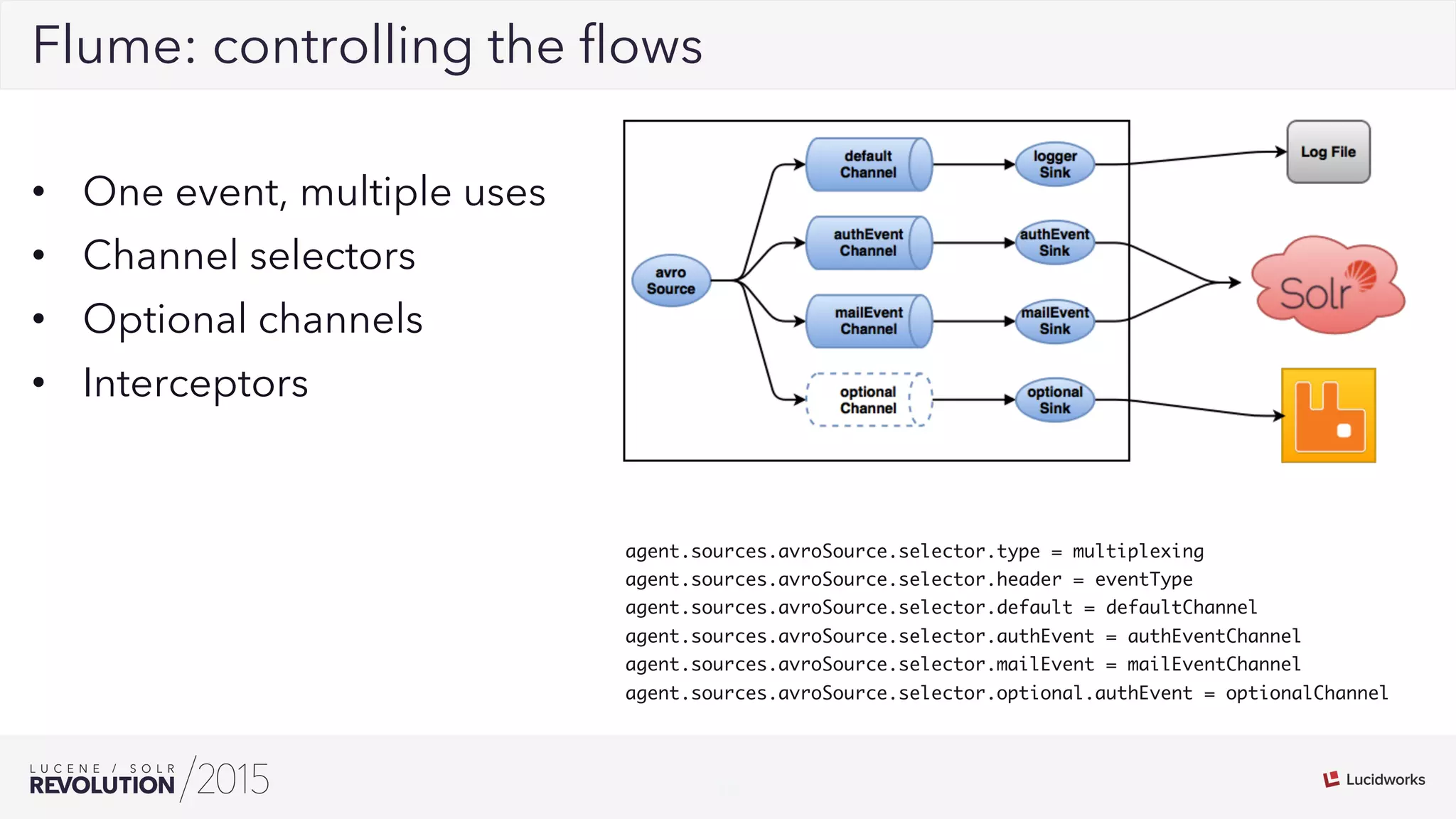






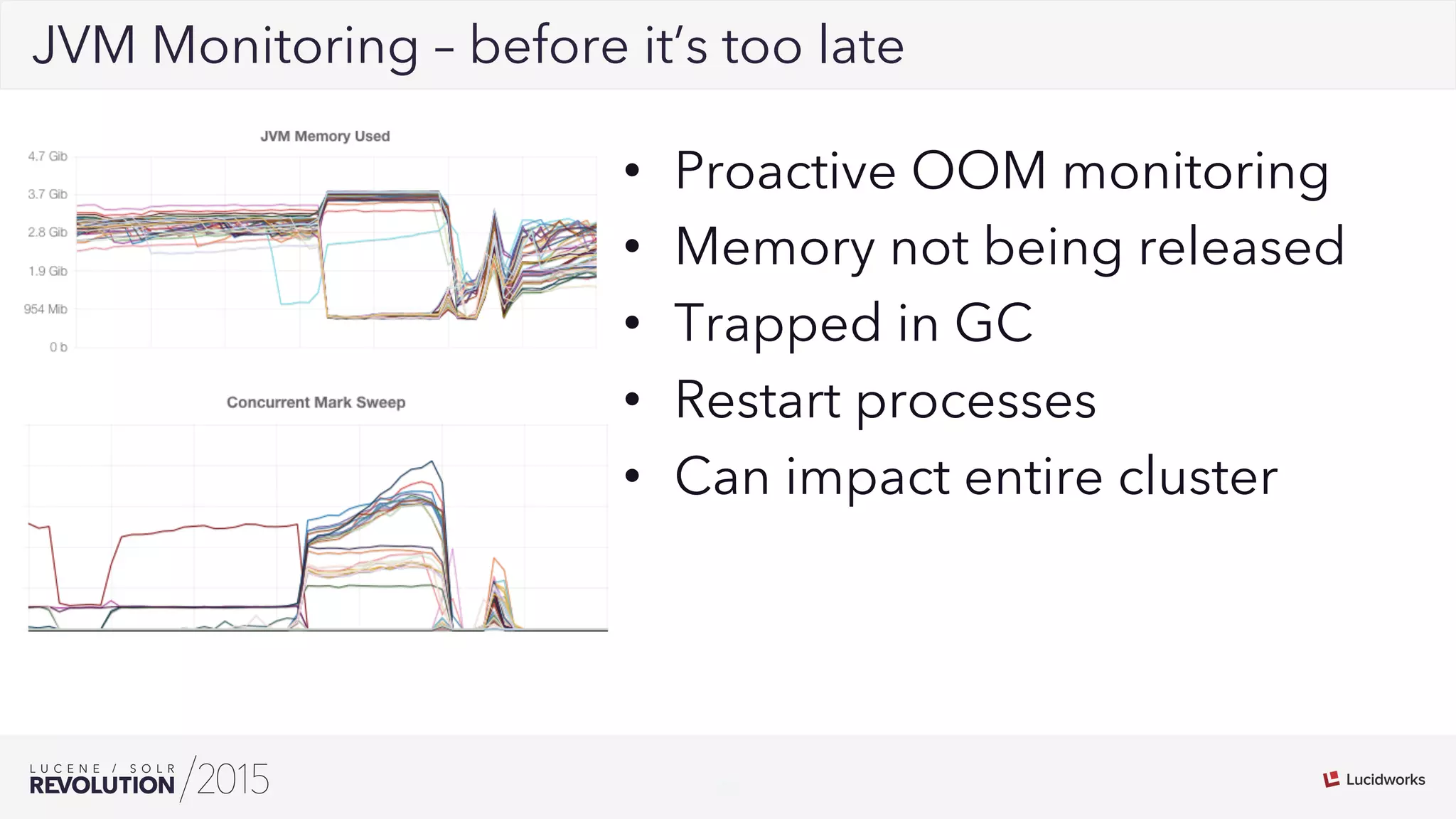










George Bailey and Cameron Baker of Rackspace presented their solution for indexing over 50,000 documents per second for Rackspace Email. They modernized their system using Apache Flume for event processing and aggregation and SolrCloud for real-time search. This reduced indexing time from over 20 minutes to under 5 seconds, reduced the number of physical servers needed from over 100 to 14, and increased indexing throughput from 1,000 to over 50,000 documents per second while supporting over 13 billion searchable documents.































































![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















