Downloaded 15 times




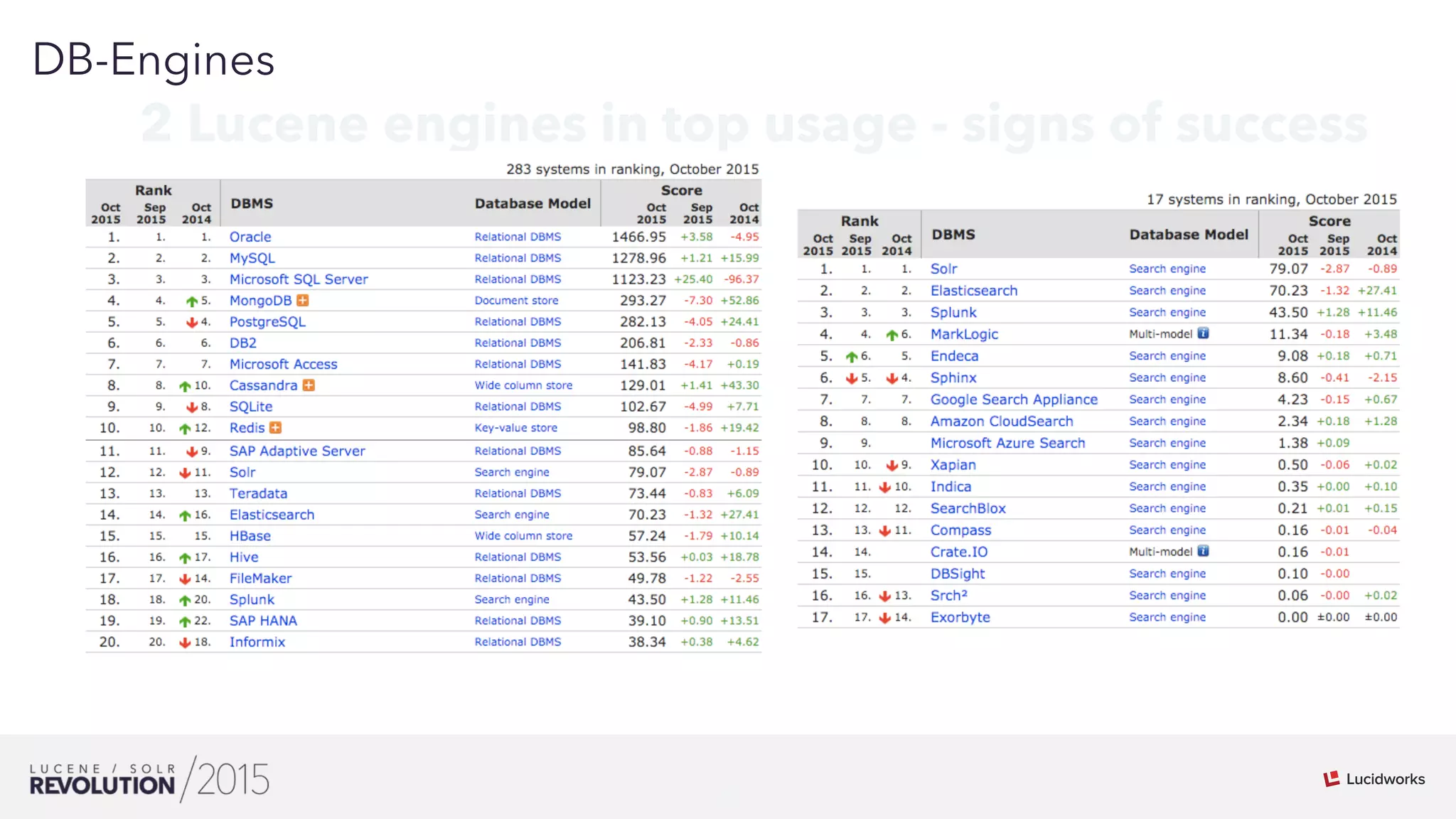






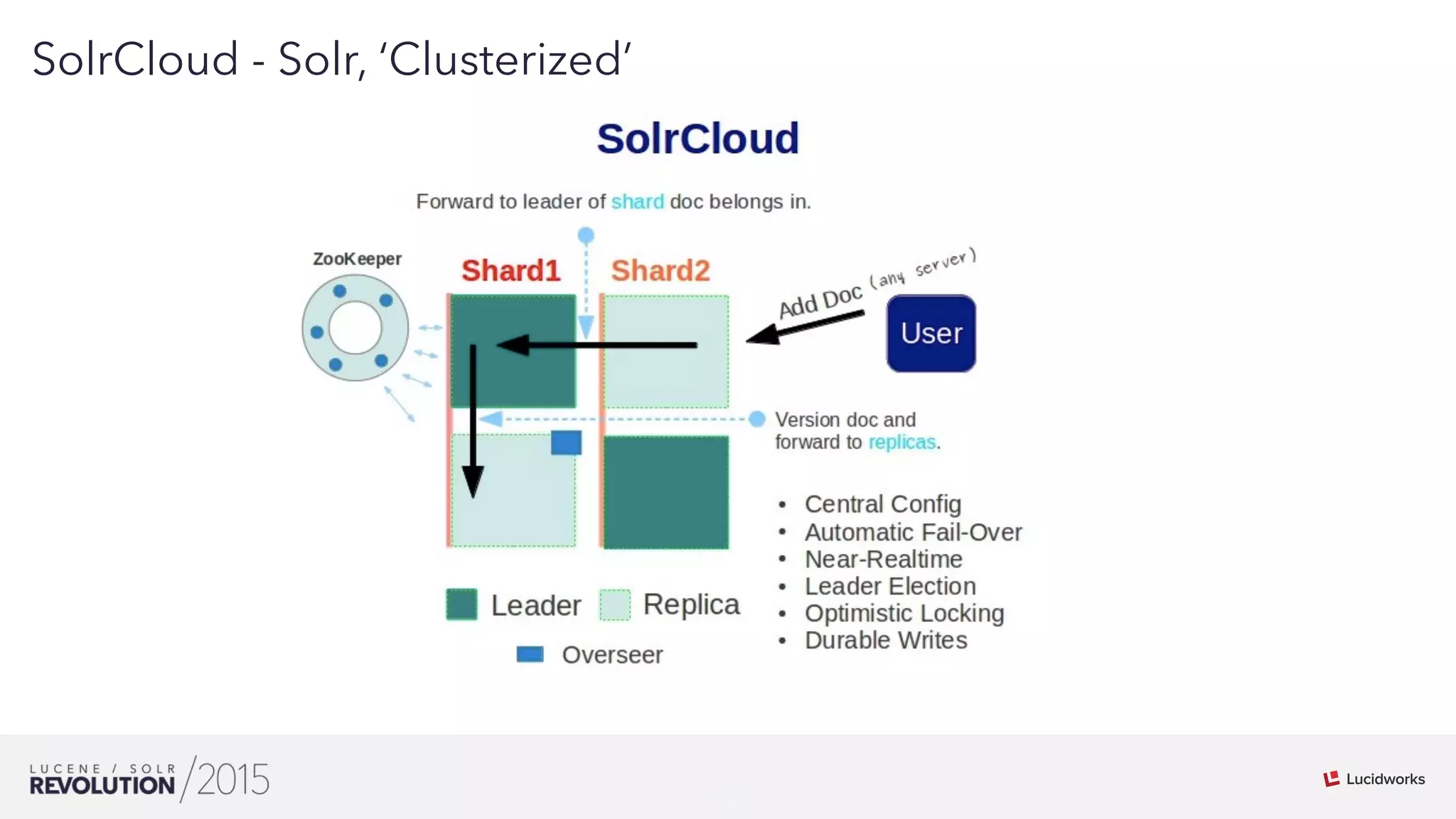



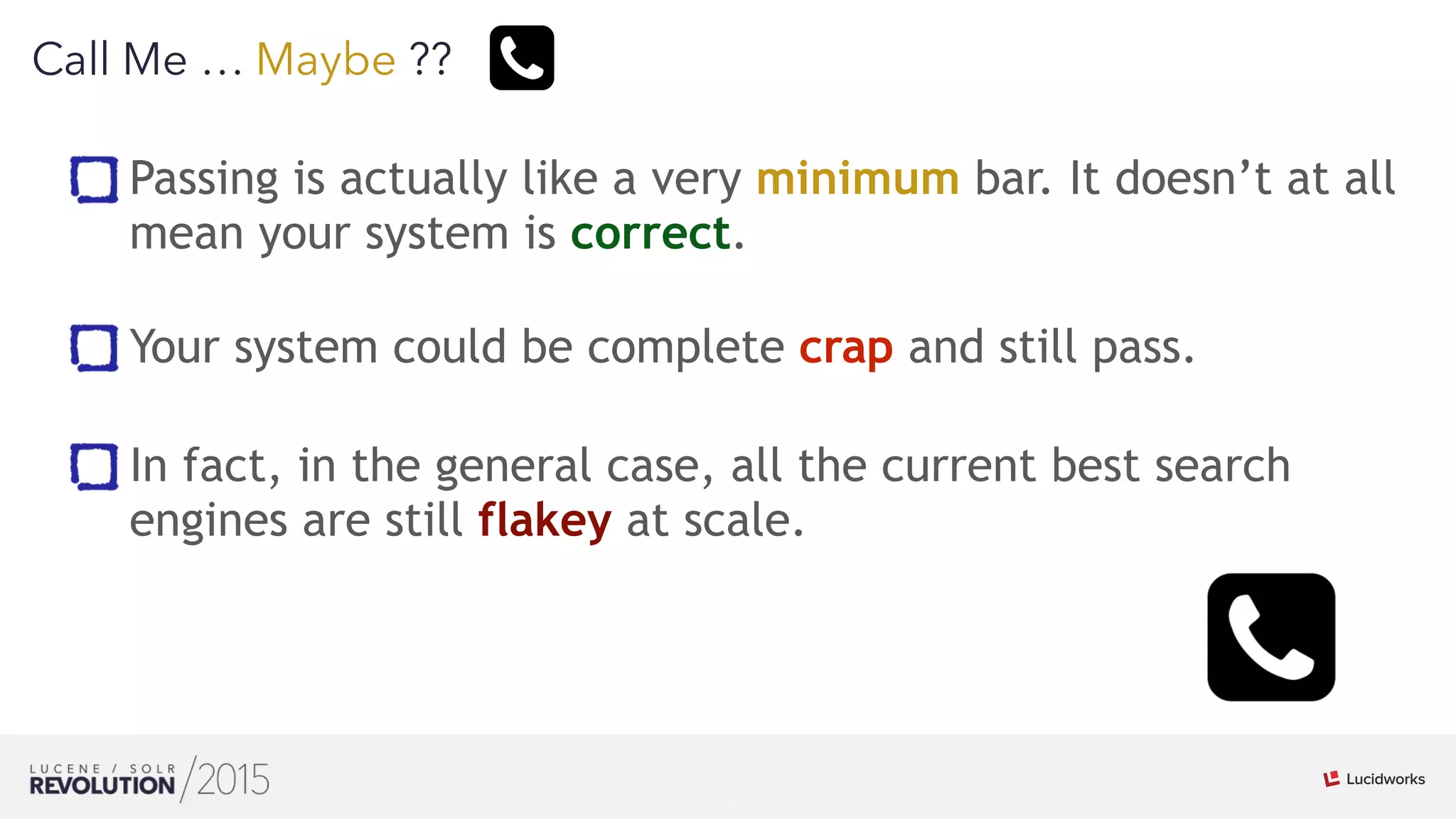







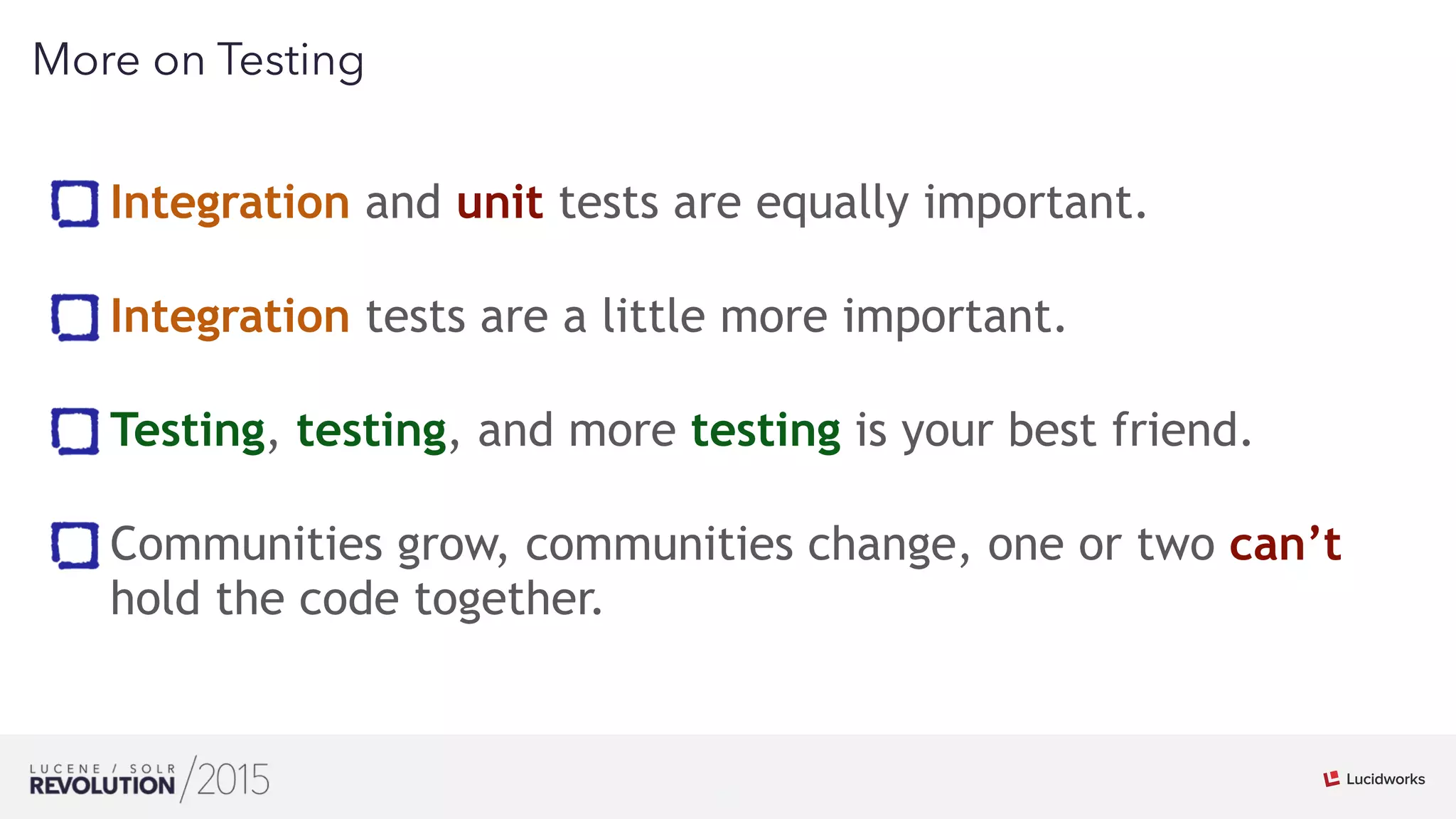
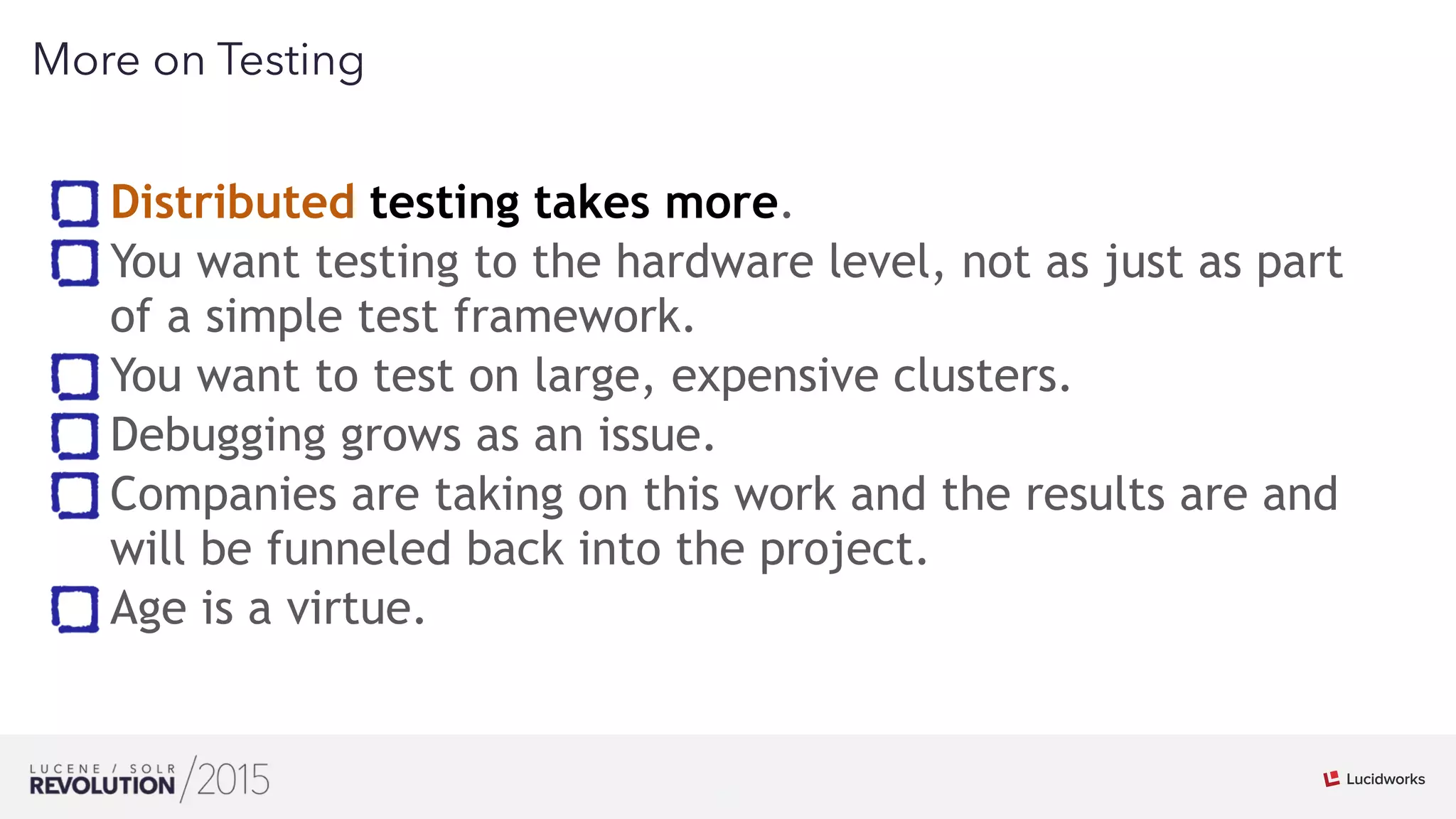







Mark Miller discussed the history and future of search engines like Lucene and Solr. He explained that Lucene search engines currently lead the field and are widely used. While search has scaled up, it remains imperfect and can be flaky at large scales. Extensive testing, including of integration and distributions, is needed to improve reliability. Leveraging Hadoop's distributed capabilities can help push search engines to be more scalable and correct at large sizes.






















































![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)




























![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


