Download to read offline









![15Confidential
(“dardasaba”, “hello”),
(“dardasaba”,
“goodbye”),
(“hathatul”, “w00t”),
(“hathatul”, “nope”),
(“gargamel”, “muhaha”)
Executor 1
Executor 2
Executor 3
Key Value
“dardasaba” [“hello”,
“goodbye”]
Key Value
“hathatul” [“w00t”,
“nope”]
Key Value
“gargamel” [“muhaha”]
OpenHashMap[String, List[String]]
DStream[(String, String)]
Key Value](https://image.slidesharecdn.com/meetupsparkstreamingv21-170919123558/85/Spark-Streaming-Scale-Clicktale-15-320.jpg)


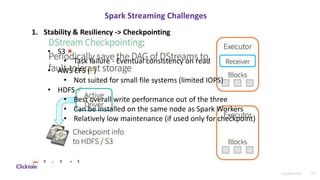






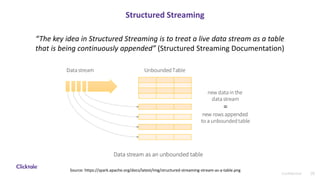








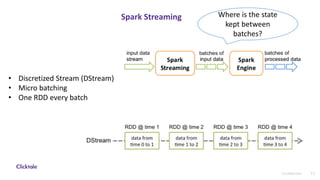
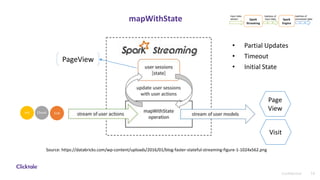
The document discusses sessionization at scale using Spark Streaming for processing large volumes of real-time user data while addressing challenges related to stability, resiliency, and scalability. It highlights the differences between Spark Streaming and Structured Streaming, emphasizing the latter's improvements in state management and efficiency for high-throughput requirements. The authors recommend using Structured Streaming for scalable applications and mention potential alternatives like Apache Flink for state management.



































































