Download as PDF, PPTX













![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
class MyTest < ::Test::Unit::TestCase
test 'client sends 2 data' do
list = []
thr = Thread.new do # Mock server
TCPServer.open("127.0.0.1", 2048) do |server|
while sock = server.accept
list << sock.read.chomp
end
end
end
2.times do |i|
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
end
assert_equal(["data 0", "data 1"], list)
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-15-320.jpg)
![Loaded suite example
Started
F
===========================================================================================
Failure: test: client sends 2 data(MyTest)
example.rb:22:in `block in <class:MyTest>'
19: end
20: end
21:
=> 22: assert_equal(["data 0", "data 1"], list)
23: end
24: end
<["data 0", "data 1"]> expected but was
<["data 0"]>
diff:
["data 0", "data 1"]
===========================================================================================
Finished in 0.007253 seconds.
-------------------------------------------------------------------------------------------
1 tests, 1 assertions, 1 failures, 0 errors, 0 pendings, 0 omissions, 0 notifications
0% passed
-------------------------------------------------------------------------------------------
137.87 tests/s, 137.87 assertions/s
Mac OS X (10.11.16)](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-16-320.jpg)
![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
class MyTest < ::Test::Unit::TestCase
test 'client sends 2 data' do
list = []
thr = Thread.new do # Mock server
TCPServer.open("127.0.0.1", 2048) do |server|
while sock = server.accept
list << sock.read.chomp
end
end
end
2.times do |i|
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
end
assert_equal(["data 0", "data 1"], list)
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-17-320.jpg)
![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
class MyTest < ::Test::Unit::TestCase
test 'client sends 2 data' do
list = []
thr = Thread.new do # Mock server
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accept
list << sock.read.chomp
end
end
end
2.times do |i|
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
end
sleep 1
assert_equal(["data 0", "data 1"], list)
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-18-320.jpg)

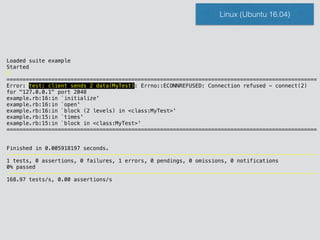
![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
class MyTest < ::Test::Unit::TestCase
test 'client sends 2 data' do
list = []
thr = Thread.new do # Mock server
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accept
list << sock.read.chomp
end
end
end
2.times do |i|
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
end
sleep 1
assert_equal(["data 0", "data 1"], list)
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-21-320.jpg)
![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
class MyTest < ::Test::Unit::TestCase
test 'client sends 2 data' do
list = []
thr = Thread.new do # Mock server
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accept
list << sock.read.chomp
end
end
end
2.times do |i|
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
end
sleep 1
assert_equal(["data 0", "data 1"], list)
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-22-320.jpg)
![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
class MyTest < ::Test::Unit::TestCase
test 'client sends 2 data' do
list = []
thr = Thread.new do # Mock server
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accept
list << sock.read.chomp
end
end
end
2.times do |i|
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
end
sleep 1
assert_equal(["data 0", "data 1"], list)
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-23-320.jpg)
![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
require 'socket'
class MyTest < ::Test::Unit::TestCase
test 'client sends 2 data' do
list = []
listening = false
thr = Thread.new do # Mock server
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accept
list << sock.read.chomp
end
end
end
sleep 0.1 until listening
2.times do |i|
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
end
require 'timeout'
Timeout.timeout(3){ sleep 0.1 until list.size >= 2 }
assert_equal(["data 0", "data 1"], list)
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-24-320.jpg)



![Memory Usage:
Object leak
• Temp values must leak in
long running process
• 1,000 objects / hour
=> 8,760,000 objects / year
• Some solutions:
• In-process GC
• Storage with TTL
• (External storages: Redis, ...)
module MyDaemon
class Process
def hour_key
Time.now.to_i / 3600
end
def hourly_store
@map[hour_key] ||= {}
end
def put(key, value)
hourly_store[key] = value
end
def get(key)
hourly_store[key]
end
# add # of data per hour
def read_data(table_name, data)
key = "records_of_#{table_name}"
put(key, get(key) + data.size)
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-28-320.jpg)



![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
require 'json'; require 'yajl'; require 'oj'
Oj.default_options = {bigdecimal_load: :float, mode: :compat, use_to_json: true}
module MyDaemon
class Json
def initialize(mode)
klass = case mode
when :json then JSON
when :yajl then Yajl
when :oj then Oj
end
@proc = klass.method(:dump)
end
def dump(data); @proc.call(data); end
end
end
require 'benchmark'
N = 500_000
obj = {"message" => "a"*100, "100" => 100, "pi" => 3.14159, "true" => true}
Benchmark.bm{|x|
x.report("json") {
formatter = MyDaemon::Json.new(:json)
N.times{ formatter.dump(obj) }
}
x.report("yajl") {
formatter = MyDaemon::Json.new(:yajl)
N.times{ formatter.dump(obj) }
}
x.report("oj") {
formatter = MyDaemon::Json.new(:oj)
N.times{ formatter.dump(obj) }
}
}](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-32-320.jpg)


![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
require 'oj'
Oj.load('{"message":"this is ') # Oj::ParseError
Oj.load('{"message":"this is a pen."}') # => Hash
Oj.load('{"message":"this is a pen."}{"messa"') # Oj::ParseError](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-35-320.jpg)

![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
require 'yajl'
parsed_objs = []
parser = Yajl::Parser.new
parser.on_parse_complete = ->(obj){ parsed_objs << obj }
parse << '{"message":"aaaaaaaaaaaaaaa'
parse << 'aaaaaaaaa"}{"message"' # on_parse_complete is called
parse << ':"bbbbbbbbb"'
parse << '}' # on_parse_complete is called again](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-37-320.jpg)
![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
require 'socket'
require 'oj'
TCPServer.open(port) do |server|
while sock = server.accept
begin
buf = ""
while input = sock.readpartial(1024)
buf << input
# can we feed this value to Oj.load ?
begin
obj = Oj.load(buf) # never succeeds if buf has 2 objects
call_method(obj)
buf = ""
rescue Oj::ParseError
# try with next input ...
end
end
rescue EOFError
sock.close rescue nil
end
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-38-320.jpg)
![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
require 'socket'
require 'yajl'
TCPServer.open(port) do |server|
while sock = server.accept
begin
parser = Yajl::Parser.new
parser.on_parse_complete = ->(obj){ call_method(obj) }
while input = sock.readpartial(1024)
parser << input
end
rescue EOFError
sock.close rescue nil
end
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-39-320.jpg)



![class MyTest < ::Test::Unit::TestCase
test 'yay 1' do
data = []
thr = Thread.new do
data << "line 1"
end
data << "line 2"
assert_equal ["line 1", "line 2"], data
end
end
class MyTestCase < ::Test::Unit::TestCase
test 'sent data should be received' do
received = []
sent = []
listening = false
th1 = Thread.new do
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accepto
received << sock.read
end
end
end
sleep 0.1 until listening
["foo", "bar"].each do |str|
begin
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
sent << str
rescue => e
# ignore
end
end
assert_equal sent, received
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-43-320.jpg)
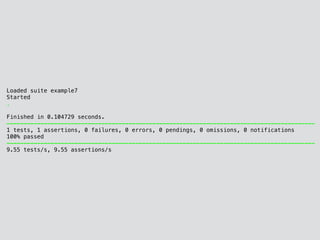
![class MyTestCase < ::Test::Unit::TestCase
test 'sent data should be received' do
received = []
sent = []
listening = false
th1 = Thread.new do
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accepto
received << sock.read
end
end
end
sleep 0.1 until listening
["foo", "bar"].each do |str|
begin
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
sent << str
rescue => e
# ignore
end
end
assert_equal sent, received
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-45-320.jpg)
![class MyTestCase < ::Test::Unit::TestCase
test 'sent data should be received' do
received = []
sent = []
listening = false
th1 = Thread.new do
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accepto
received << sock.read
end
end
end
sleep 0.1 until listening
["foo", "bar"].each do |str|
begin
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
sent << str
rescue => e
# ignore
end
end
assert_equal sent, received
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-46-320.jpg)
![class MyTestCase < ::Test::Unit::TestCase
test 'sent data should be received' do
received = []
sent = []
listening = false
th1 = Thread.new do
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accepto
received << sock.read
end
end
end
sleep 0.1 until listening
["foo", "bar"].each do |str|
begin
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
sent << str
rescue => e
# ignore
end
end
assert_equal sent, received
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-47-320.jpg)
![class MyTestCase < ::Test::Unit::TestCase
test 'sent data should be received' do
received = []
sent = []
listening = false
th1 = Thread.new do
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accepto
received << sock.read
end
end
end
sleep 0.1 until listening
["foo", "bar"].each do |str|
begin
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
sent << str
rescue => e
# ignore
end
end
assert_equal sent, received
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-48-320.jpg)
![class MyTestCase < ::Test::Unit::TestCase
test 'sent data should be received' do
received = []
sent = []
listening = false
th1 = Thread.new do
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accepto
received << sock.read
end
end
end
sleep 0.1 until listening
["foo", "bar"].each do |str|
begin
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
sent << str
rescue => e
# ignore
end
end
assert_equal sent, received
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-49-320.jpg)
![class MyTestCase < ::Test::Unit::TestCase
test 'sent data should be received' do
received = []
sent = []
listening = false
th1 = Thread.new do
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accepto
received << sock.read
end
end
end
sleep 0.1 until listening
["foo", "bar"].each do |str|
begin
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
sent << str
rescue => e
# ignore
end
end
assert_equal sent, received # [] == []
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-50-320.jpg)

![class MyTestCase < ::Test::Unit::TestCase
test 'sent data should be received' do
received = []
sent = []
listening = false
th1 = Thread.new do
Thread.current.abort_on_exception = true
TCPServer.open("127.0.0.1", 2048) do |server|
listening = true
while sock = server.accepto
received << sock.read
end
end
end
sleep 0.1 until listening
["foo", "bar"].each do |str|
begin
TCPSocket.open("127.0.0.1", 2048) do |client|
client.write "data #{i}"
end
sent << str
rescue => e
# ignore
end
end
assert_equal sent, received # [] == []
end
end](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-52-320.jpg)
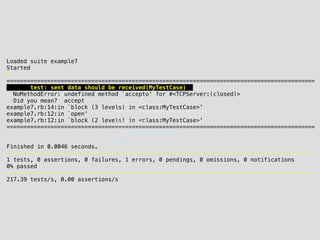






![Loaded suite example
Started
F
===========================================================================================
Failure: test: client sends 2 data(MyTest)
example.rb:22:in `block in <class:MyTest>'
19: end
20: end
21:
=> 22: assert_equal(["data 0", "data 1"], list)
23: end
24: end
<["data 0", "data 1"]> expected but was
<["data 0", "data 1"]>
diff:
["data 0", "data 1"]
===========================================================================================
Finished in 0.009425 seconds.
-------------------------------------------------------------------------------------------
1 tests, 1 assertions, 1 failures, 0 errors, 0 pendings, 0 omissions, 0 notifications
0% passed
-------------------------------------------------------------------------------------------
106.10 tests/s, 106.10 assertions/s
Mac OS X (10.11.16)](https://image.slidesharecdn.com/rubyconftaiwan2016-161202082411/85/How-To-Write-Middleware-In-Ruby-60-320.jpg)


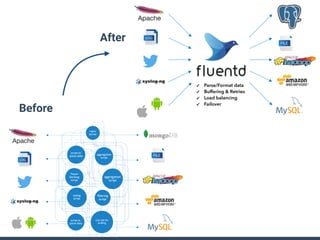
This document discusses middleware in Ruby and provides examples of considerations when writing middleware: - Middleware should be a long-running daemon process that is compatible across platforms and environments and handles various data formats and traffic volumes. - Tests must be run on all supported platforms to ensure compatibility as thread and process scheduling differs between operating systems. - Memory usage and object leaks must be carefully managed in long-running processes to avoid consuming resources over time. - Performance of JSON parsing/generation should be benchmarked and the most optimized library used to avoid unnecessary CPU usage.



































![The Ruby Guide to *nix Plumbing: on the quest for efficiency with Ruby [M|K]RI](https://cdn.slidesharecdn.com/ss_thumbnails/presentation-091107031803-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

























































