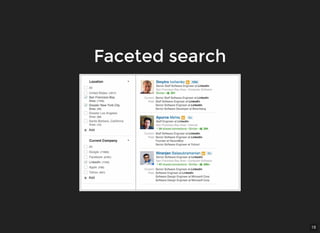
The document provides an overview of Solr, an open-source enterprise search platform built on Apache Lucene, highlighting its key features such as reliability, scalability, and fault tolerance. It explains how Solr works, including concepts like inverted indexing, relevancy calculation, and document-oriented data handling. Additionally, it outlines various use cases, capabilities such as geospatial and multilingual support, and cautions against using it for deep analytic tasks.