








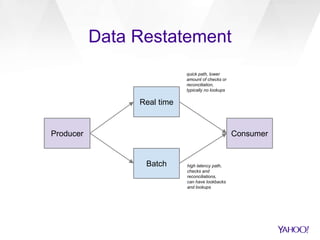



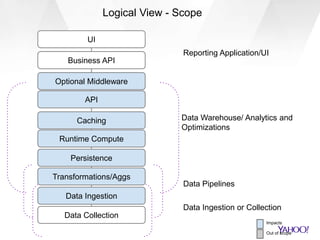

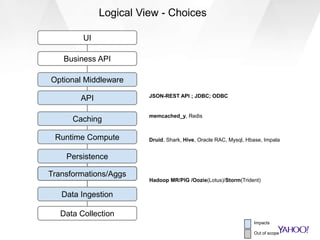
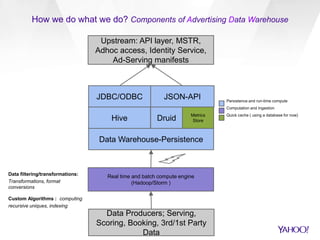













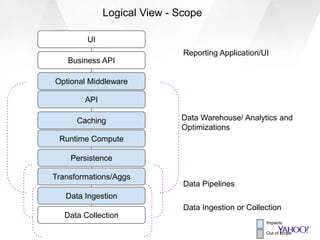




This document discusses Yahoo's approach to interactive analytics on human timescales for their large-scale advertising data warehouse. It describes how they ingest billions of daily events and terabytes of data, transform and store it using technologies like Druid and Storm, and perform real-time analytics like computing overlaps between user groups in under a minute. It also compares their "instant overlap" technique using feature sequences and bitmaps to existing approaches like exact computation and sketches.































































































