Downloaded 112 times












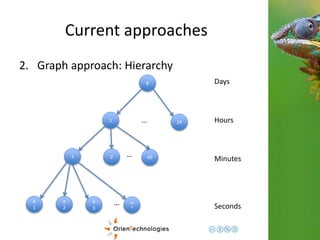
![Current approaches
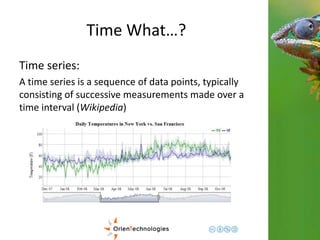
1. Document approach: Minute Based
{
timestamp: “2014-11-21 12.05“
load: [10, 15, 3, … 30] //array of 60, one per second
}](https://image.slidesharecdn.com/201411-codemotionmilano-dellaquila-141201042026-conversion-gate01/85/OrientDB-Time-Series-and-Event-Sequences-Codemotion-Milan-2014-15-320.jpg)
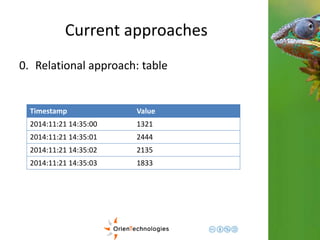
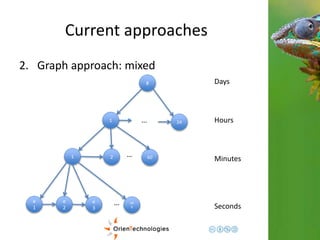
![Current approaches
1. Document approach: Hour Based
{
timestamp: “2014-11-21 12.00“
load: {
0: [10, 15, 3, … 30], //array of 60, one per second
1: [0, 12, 31, … 24],
…
59: [10, 10, 1, … 16]
}
}](https://image.slidesharecdn.com/201411-codemotionmilano-dellaquila-141201042026-conversion-gate01/85/OrientDB-Time-Series-and-Event-Sequences-Codemotion-Milan-2014-16-320.jpg)



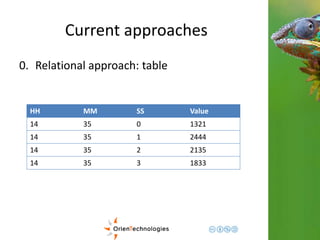
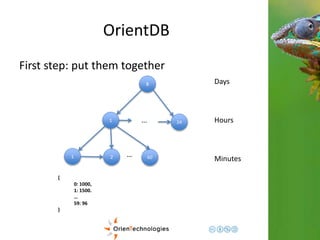
![Current approaches
2. Graph approach: linked sequence (tag
based)
e
1
e
2
nextTag1
e
3
nextTag2
e
4
nextTag1
e
5
nextTag1
nextTag2
[Tag1, Tag2] [Tag1]
[Tag1, Tag2]
[Tag1]
[Tag2]](https://image.slidesharecdn.com/201411-codemotionmilano-dellaquila-141201042026-conversion-gate01/85/OrientDB-Time-Series-and-Event-Sequences-Codemotion-Milan-2014-21-320.jpg)






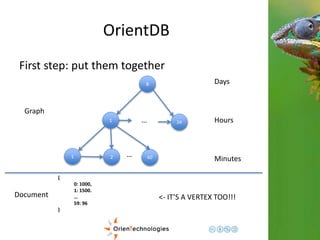
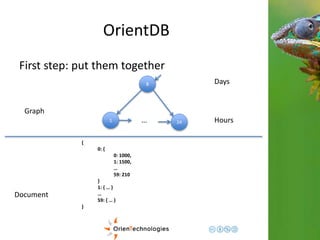


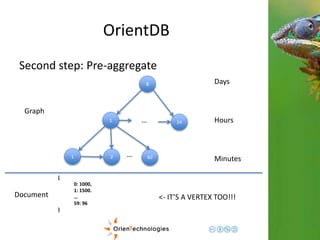
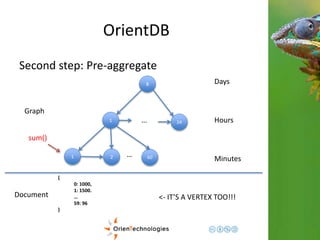
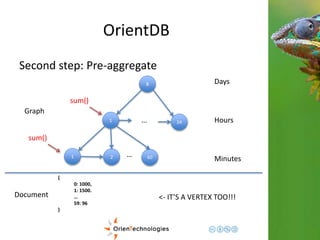


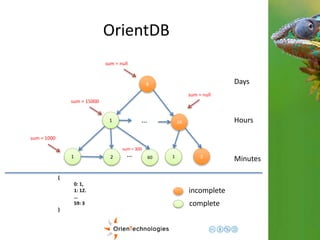


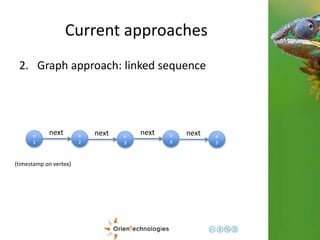
![OrientDB
Third step: Complex domains
1
1 2 60 …
Hours
Minutes
{
0: {val: 1000},
1: {val: 1500}.
…
59: {
val: 96,
eventTags: [tag1, tag2]
…
}
}
Graph
Document <- Enrich the domain](https://image.slidesharecdn.com/201411-codemotionmilano-dellaquila-141201042026-conversion-gate01/85/OrientDB-Time-Series-and-Event-Sequences-Codemotion-Milan-2014-43-320.jpg)
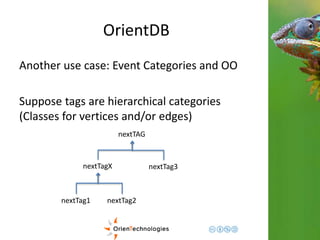
![OrientDB
Another use case: Event Categories and OO
e
1
e
2
nextTag1
e
3
nextTag2
e
4
nextTag1
e
5
nextTag1
nextTag2
[Tag1, Tag2, Tag3] [Tag1]
[Tag1, Tag2]
[Tag1]
[Tag2]
nextTag3
e
3
[Tag3]](https://image.slidesharecdn.com/201411-codemotionmilano-dellaquila-141201042026-conversion-gate01/85/OrientDB-Time-Series-and-Event-Sequences-Codemotion-Milan-2014-44-320.jpg)
![OrientDB
Subset of events
TRAVERSE out(‘nextTag1’) FROM <e1>
e
1
e
2
nextTag1
e
4
nextTag1
e
5
nextTag1
[Tag1, Tag2, Tag3] [Tag1]
[Tag1, Tag2]
[Tag1]](https://image.slidesharecdn.com/201411-codemotionmilano-dellaquila-141201042026-conversion-gate01/85/OrientDB-Time-Series-and-Event-Sequences-Codemotion-Milan-2014-46-320.jpg)
![OrientDB
Subset of events
TRAVERSE out(‘nextTag2’) FROM <e1>
e
1
nextTag1
nextTag2 e
e
3
5
nextTag2
[Tag1, Tag2, Tag3]
[Tag1, Tag2]
[Tag2]](https://image.slidesharecdn.com/201411-codemotionmilano-dellaquila-141201042026-conversion-gate01/85/OrientDB-Time-Series-and-Event-Sequences-Codemotion-Milan-2014-47-320.jpg)
![OrientDB
Subset of events (Polymorphic!!!)
TRAVERSE out(‘nextTagX’) FROM <e1>
e
1
e
2
nextTag1
e
3
nextTag2
e
4
nextTag1
e
5
nextTag1
nextTag2
[Tag1, Tag2, Tag3] [Tag1]
[Tag1, Tag2]
[Tag1]
[Tag2]](https://image.slidesharecdn.com/201411-codemotionmilano-dellaquila-141201042026-conversion-gate01/85/OrientDB-Time-Series-and-Event-Sequences-Codemotion-Milan-2014-48-320.jpg)



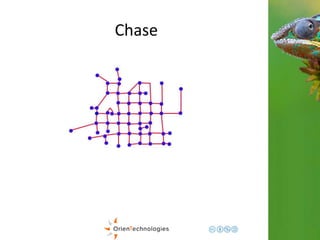
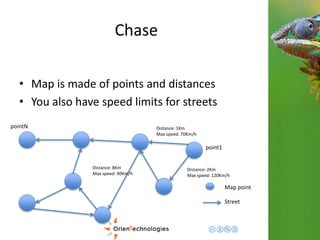


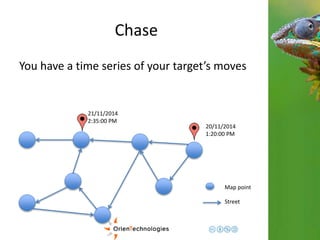
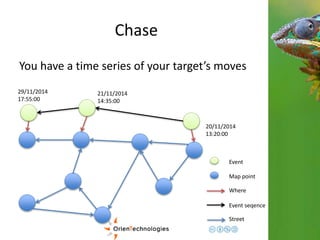












This document discusses using a multi-model database approach to manage time series and event sequence data. It describes some common approaches like using a relational database with timestamp fields or storing events in a document database. It then outlines how OrientDB combines graph and document models to provide flexibility while maintaining fast write and read speeds. Events can be connected in the graph and stored as documents to allow for relationships and complex properties. The document summarizes how OrientDB allows aggregating data during writes using hooks and querying pre-aggregated data to enable fast analysis of time-based data.




































































