Download as PDF, PPTX
























![Convert
to
Cypher
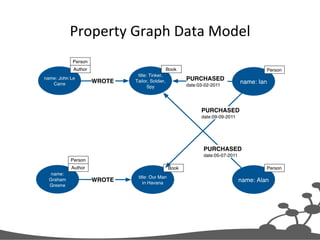
Paths
RelaEonship
Person
WORKS_FOR
Company
Person
HAS_SKILL
Skill
Label
(:Person)-[:WORKS_FOR]->(:Company),
(:Person)-[:HAS_SKILL]->(:Skill)](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-26-320.jpg)
![Consolidate
Paths
(:Person)-[:WORKS_FOR]->(:Company),
(:Person)-[:HAS_SKILL]->(:Skill)
(:Company)<-[:WORKS_FOR]-(:Person)-[:HAS_SKILL]->(:Skill)](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-27-320.jpg)
![Create
Person
Subgraph
MERGE (c:Company{name:'Acme'})
MERGE (p:Person{name:'Ian'})
MERGE (s1:Skill{name:'Java'})
MERGE (s2:Skill{name:'C#'})
MERGE (s3:Skill{name:'Neo4j'})
CREATE UNIQUE (c)<-[:WORKS_FOR]-(p),
(p)-[:HAS_SKILL]->(s1),
(p)-[:HAS_SKILL]->(s2),
(p)-[:HAS_SKILL]->(s3)
RETURN c, p, s1, s2, s3](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-28-320.jpg)
![Candidate
Data
Model
(:Company)<-[:WORKS_FOR]-(:Person)-[:HAS_SKILL]->(:Skill)](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-29-320.jpg)

![Cypher
Query
Which
people,
who
work
for
the
same
company
as
me,
have
similar
skills
to
me?
MATCH (company)<-[:WORKS_FOR]-(me:Person)-[:HAS_SKILL]->(skill),
(company)<-[:WORKS_FOR]-(colleague)-[:HAS_SKILL]->(skill)
WHERE me.name = {name}
RETURN colleague.name AS name,
count(skill) AS score,
collect(skill.name) AS skills
ORDER BY score DESC](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-31-320.jpg)
![Graph
PaWern
Which
people,
who
work
for
the
same
company
as
me,
have
similar
skills
to
me?
MATCH (company)<-[:WORKS_FOR]-(me:Person)-[:HAS_SKILL]->(skill),
(company)<-[:WORKS_FOR]-(colleague)-[:HAS_SKILL]->(skill)
WHERE me.name = {name}
RETURN colleague.name AS name,
count(skill) AS score,
collect(skill.name) AS skills
ORDER BY score DESC](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-32-320.jpg)
![Anchor
PaWern
in
Graph
Which
people,
who
work
for
the
same
company
as
me,
have
similar
skills
to
me?
MATCH (company)<-[:WORKS_FOR]-(me:Person)-[:HAS_SKILL]->(skill),
(company)<-[:WORKS_FOR]-(colleague)-[:HAS_SKILL]->(skill)
WHERE me.name = {name}
RETURN colleague.name AS name,
count(skill) AS score,
collect(skill.name) AS skills
ORDER BY score DESC
If
an
index
for
Person.name
exists,
Cypher
will
use
it](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-33-320.jpg)
![Create
ProjecEon
of
Results
Which
people,
who
work
for
the
same
company
as
me,
have
similar
skills
to
me?
MATCH (company)<-[:WORKS_FOR]-(me:Person)-[:HAS_SKILL]->(skill),
(company)<-[:WORKS_FOR]-(colleague)-[:HAS_SKILL]->(skill)
WHERE me.name = {name}
RETURN colleague.name AS name,
count(skill) AS score,
collect(skill.name) AS skills
ORDER BY score DESC](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-34-320.jpg)



![Running
the
Query
+-----------------------------------+
| name | score | skills |
+-----------------------------------+
| "Lucy" | 2 | ["Java","Neo4j"] |
| "Bill" | 1 | ["Neo4j"] |
+-----------------------------------+
2 rows](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-38-320.jpg)
![From
User
Story
to
Model
and
Query
MATCH (company)<-[:WORKS_FOR]-(me:Person)-[:HAS_SKILL]->(skill),
(company)<-[:WORKS_FOR]-(colleague)-[:HAS_SKILL]->(skill)
WHERE me.name = {name}
RETURN colleague.name AS name,
count(skill) AS score,
collect(skill.name) AS skills
ORDER BY score DESC
As
an
employee
I
want
to
know
who
in
the
company
has
similar
skills
to
me
So
that
we
can
exchange
knowledge
Person
WORKS_FOR
Company
Person
HAS_SKILL
Skill
(:Company)<-[:WORKS_FOR]-(:Person)-[:HAS_SKILL]->(:Skill)
? Which
people,
who
work
for
the
same
company
as
me,
have
similar
skills
to
me?](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-39-320.jpg)




























![Labels
and
RelaEonship
Types
(:Person)-[:FRIEND]->(:Person)](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-68-320.jpg)
![ProperEes
(:Person{name:'Peter'})-[:FRIEND]->(:Person{name:'Lucy'})](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-69-320.jpg)
![IdenEfiers
(p1:Person{name:'Peter'})-[r:FRIEND]->(p2:Person{name:'Lucy'})](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-70-320.jpg)
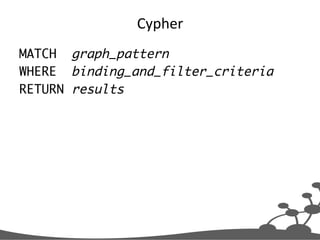
![Cypher
MATCH (p:Person)-[:FRIEND]->(friends)
WHERE p.name = 'Peter'
RETURN friends](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-72-320.jpg)
![Lookup
Using
IdenEfier
+
Label
MATCH (p:Person)-[:FRIEND]->(friends)
WHERE p.name = 'Peter'
RETURN friends](https://image.slidesharecdn.com/20141216graphdatabaseprototypingamsmeetup-141217041328-conversion-gate01/85/20141216-graph-database-prototyping-ams-meetup-73-320.jpg)

The document outlines an agenda for a graph database prototyping meetup, covering topics such as graph modeling concepts, prototyping tools, and querying with Cypher using Neo4j. It discusses the fundamental components of a property graph, including nodes, relationships, properties, and labels, along with guidance on designing a graph model for specific application goals. Additionally, it provides examples of Cypher queries and tips for effective graph modeling and querying strategies.




















































































