Downloaded 76 times












![References
[1] Molchanov, Pavlo, et al. "Pruning Convolutional Neural Networks for Resource Efficient Transfer
Learning." arXiv preprint arXiv:1611.06440 (2016).
[2] Hengyuan Hu, Rui Peng, Yu-Wing Tai, and Chi-Keung Tang. Network trimming: A data-driven neuron
pruning approach towards efficient deep architectures. arXiv preprint arXiv:1607.03250, 2016
[3] S. Han, H. Mao, and W. J. Dally, “Deep Compression - Compressing Deep Neural Networks with
Pruning, Trained Quantization and Huffman Coding,” Int. Conf. Learn. Represent., pp. 1–13, 2016.
[4] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image
recognition. In ICLR, 2015
[5] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep
convolutional neural networks." Advances in neural information processing systems. 2012.
20](https://image.slidesharecdn.com/fvjdgcx1roseyhbxcrql-signature-d774a83ad96ff5ab419f7a2a324ae6152f960a41110707f9c2f12ad17953c6c2-poli-170128022739/85/Pruning-convolutional-neural-networks-for-resource-efficient-inference-20-320.jpg)

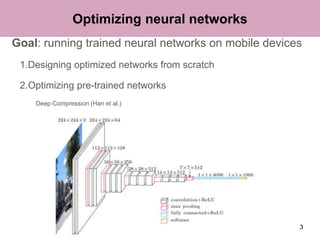
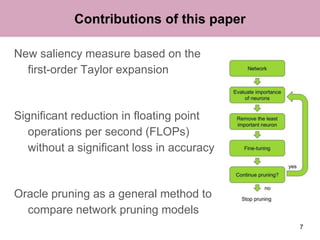
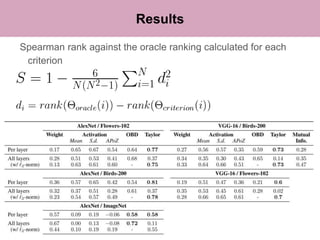
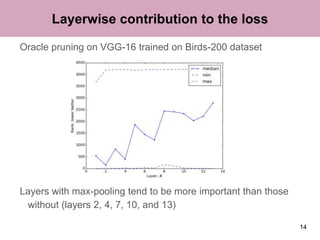
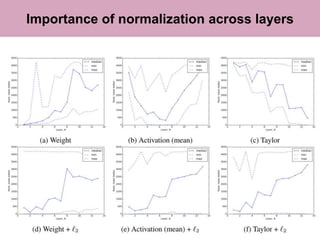
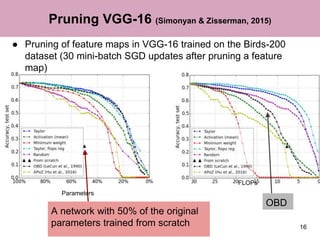
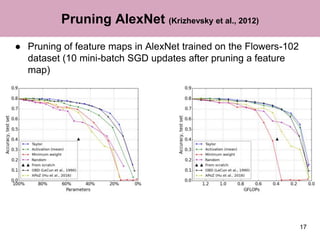
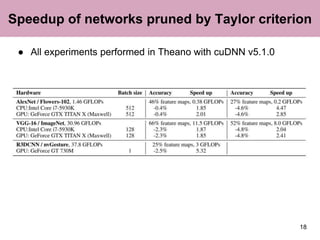
The document discusses a method for pruning convolutional neural networks to make them more efficient for resource-constrained inference. The method uses a Taylor expansion to calculate the saliency of parameters, allowing it to prune those with the least effect on the network's loss. Experiments on networks like VGG-16 and AlexNet show the method can significantly reduce operations with little loss in accuracy. Layer-wise analysis provides insight into each layer's importance to the overall network.






































![[DL輪読会] Hybrid computing using a neural network with dynamic external memory](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawadnc-161220014044-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Exploiting Cyclic Symmetry in Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/20170217-170228044623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Unsupervised Cross-Domain Image Generation](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20170310-170310051823-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generat...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks170303-170308031242-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170217-170217024917-thumbnail.jpg?width=640&height=640&fit=bounds)





![Neural network pruning with residual connections and limited-data review [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/neuralnetworkpruningwithresidual-connectionsandlimited-datareviewcdm-200605100855-thumbnail.jpg?width=640&height=640&fit=bounds)









































