Download to read offline
















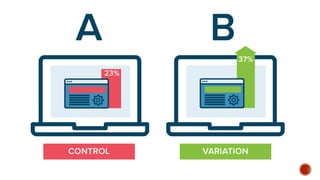










The document discusses the importance and methodologies of program evaluation in assessing the effectiveness of educational programs and services. It highlights various scientific methods used in evaluations, such as experimental designs and A/B testing, to gather data for informed decision-making and program improvement. Ultimately, program evaluations help stakeholders understand resource allocation, measure outcomes, and enhance the overall quality of educational offerings.























































































