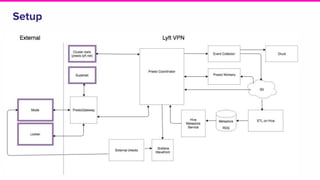
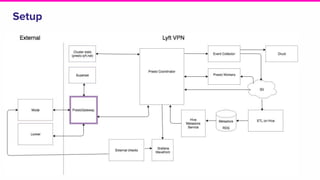
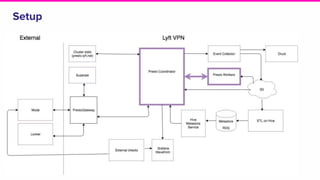
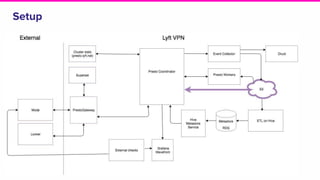
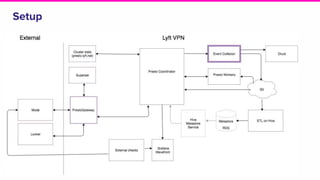
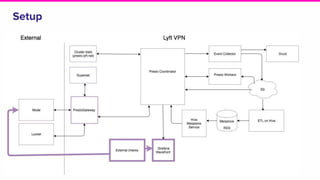
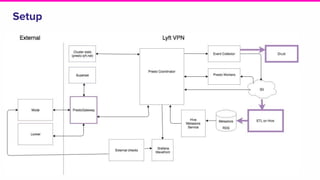
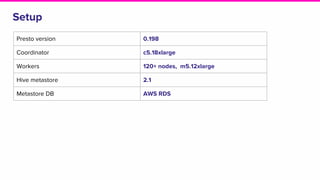
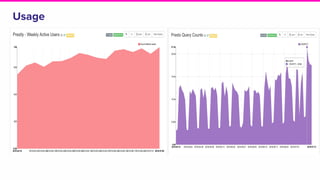
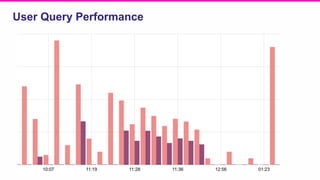
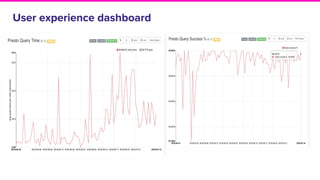
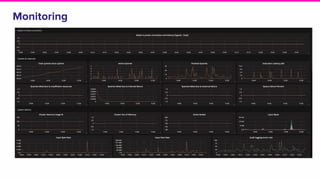
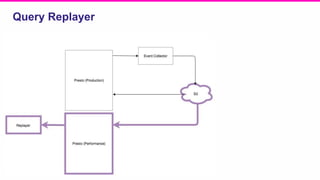
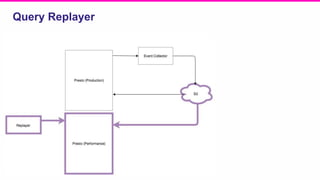
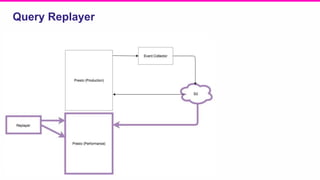
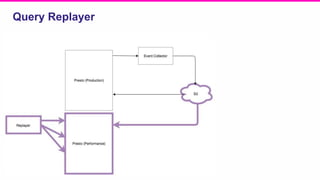
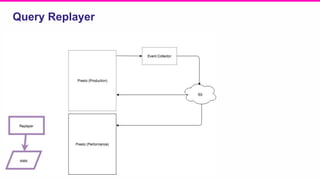
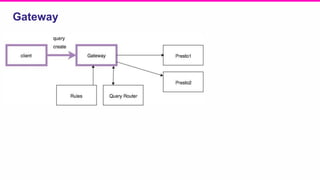
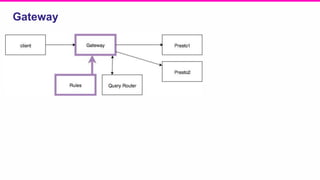
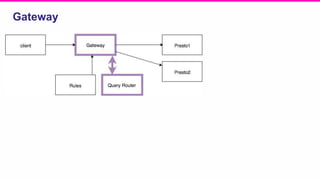
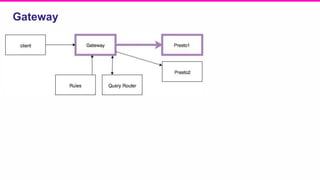
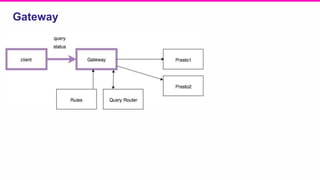
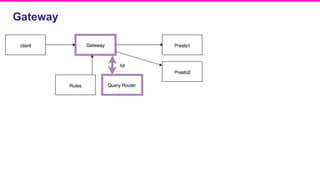
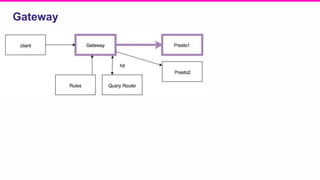
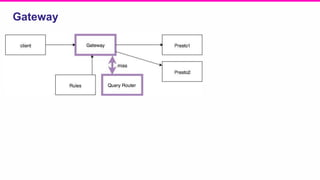
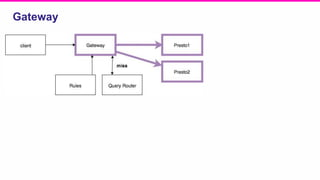
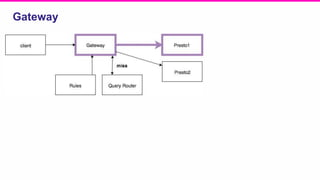
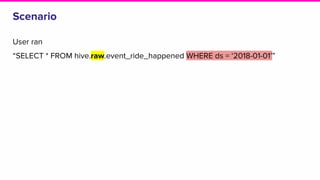
The document outlines a meeting agenda for the analytics infrastructure team at Lyft, focused on the usage and setup of Presto, eventing, monitoring, and query protection strategies. It details historical data handling, performance issues, and the implementation of a query replayer for diagnostics, along with suggestions for future work on improving the system and enhancing query routing. Ultimately, it serves as a comprehensive guide to address Presto query performance and monitoring challenges.























































![[Virtual Meetup] Using Elasticsearch as a Time-Series Database in the Endpoin...](https://cdn.slidesharecdn.com/ss_thumbnails/2020-200909133305-thumbnail.jpg?width=640&height=640&fit=bounds)














































![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)







