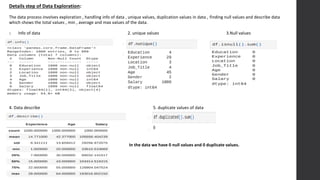
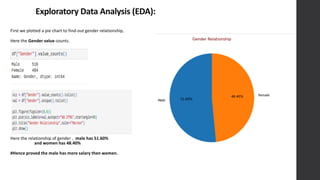
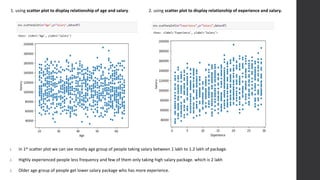
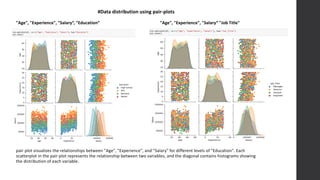
The document discusses the development of a salary prediction system using machine learning techniques to forecast salaries based on factors such as education, experience, and geographic location. It outlines the challenges faced in accurately predicting salaries, including data variability and the complexity of salary determinants. The project aims to provide valuable insights for businesses, recruiters, and job seekers, ultimately facilitating more equitable salary negotiations and informed decision-making.