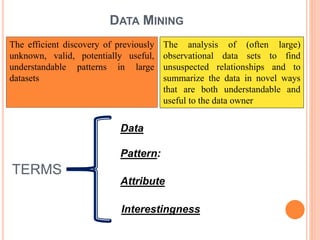
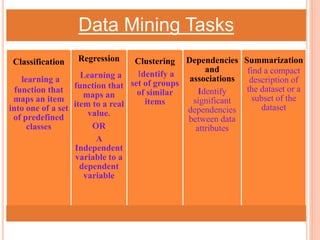
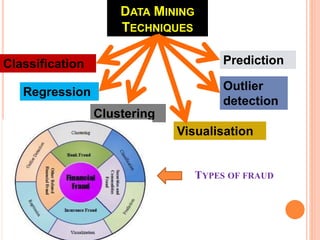
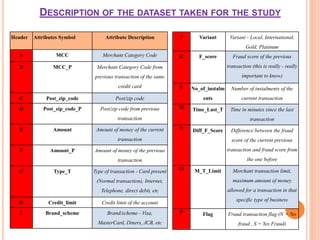
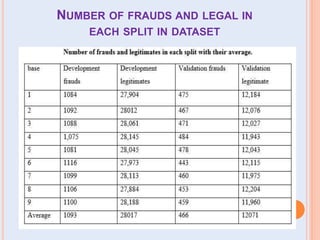
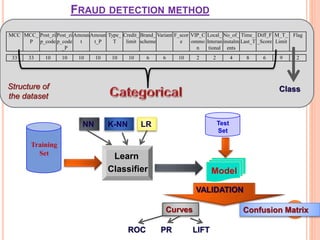
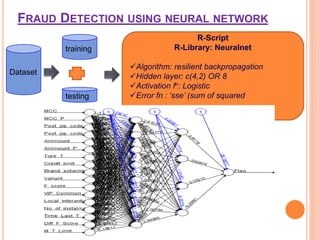
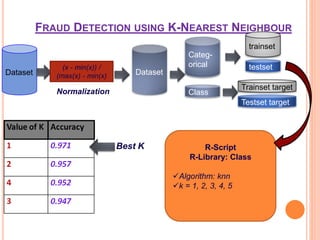
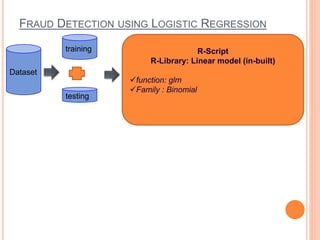
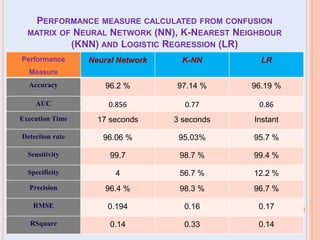
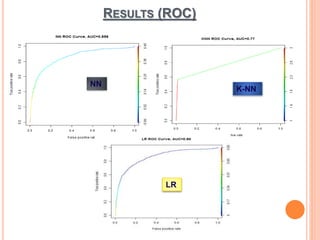
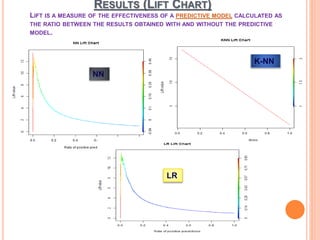
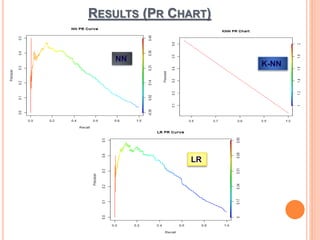
The document presents a comparative study of three predictive data mining techniques—neural network (NN), logistic regression (LR), and k-nearest neighbor (KNN)—for transaction fraud detection using a dataset from a Brazilian bank. The findings indicate that NN achieves the highest fraud detection rate, while KNN demonstrates superior execution time. The study emphasizes the potential advantages of a multi-algorithmic approach in managing complex and noisy datasets for fraud detection.




![LITERATURE SURVEY
As we can see in paper [5] S.Bhattacharyya has done
comparative study of various approaches on one
synthetic dataset and analysed results of logistic
regression, random forest and SVM. And the results
shows LR is best in his research.
I took this[5] paper as a base paper and done
comparative study on LR, NN and KNN on real dataset
which would be helpful for further research.](https://image.slidesharecdn.com/pratibhacomparativestudy-181204182946/85/Comparative-study-of-various-approaches-for-transaction-Fraud-Detection-using-Machine-Learning-Algorithms-5-320.jpg)








![REFERENCES
[1] S. Benson Edwin Raj, A. Annie Portia “Analysis on Credit Card Fraud Detection Methods”.
IEEE-International Conference on Computer, Communication and Electrical Technology; (2011).
(152-156).
[2] Haruna, C., abdul-kareem., S. abubakar. A: A Framework for selecting the optimal technique
suitable for application in data mining task., Future information technology,163-169, (2014).
[3] Manoel Fernando Alonso Gadi, Xidi Wang, and Alair Pereira do Lago. Credit card fraud detection
with artificial immune system, 7th international conference, icaris 2008, phuket, thailand, august
10-13, 2008, proceedings. In ICARIS, volume 5132 of Lecture Notes in Computer Science, pages
119 – 131. Springer, 2008
[4] E.W.T. Ngai, Yong Hu, Y.H. Wong, Yijun Chen, Xin Sun “The application of data mining techniques
in financial fraud detection: A classification framework and an academic review of literature”.
Elsevier-Decision Support Systems.50; (559–569), (2011).
[5] S.Bhattacharyya, S. Jha, K. Tharakunnel, J.C. Westland, “Data mining for credit card fraud: A
comparative study”, in Elsevier- Decision Support Systems, 2011.
[6] Usama, M. Fayyad, et al., Advances in Knowledge Discovery and Data Mining. Cambridge,
Mass.: MIT Press (1996).
[7] Han, Jun; Morag, Claudio, “The influence of the sigmoid function parameters on the speed of
Backpropagation learning", In Mira, José, Sandoval, Francisco, From Natural to Artificial Neural
Computation. pp. 195–201, 1995.
[8] Neda .S Halvaiee, M. Kazem Akbari “A novel model for credit card fraud detection using Artificial
Immune Systems”, Elsevier-Applied soft computing, Vol- 24, pp 40-49, 2014.
[9] F. Campos, S. Cavalcante, An extended approach for Dempster–Shafer theory, in:
Proceedings of the IEEE International Conference on Information Reuse and Integration, 2003,
pp. 338–344.](https://image.slidesharecdn.com/pratibhacomparativestudy-181204182946/85/Comparative-study-of-various-approaches-for-transaction-Fraud-Detection-using-Machine-Learning-Algorithms-31-320.jpg)



























































![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Predrag Maletic - Scaling AI in Banking – Our Strategic Journ...](https://cdn.slidesharecdn.com/ss_thumbnails/qu2onv0aruwlvqtygmxx-predrag-maletic-scaling-ai-in-banking-260123083019-6cf1da1d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)







