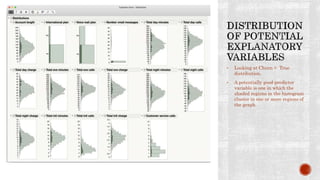
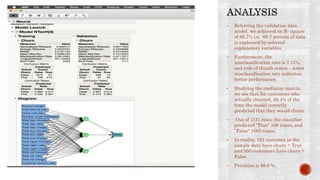
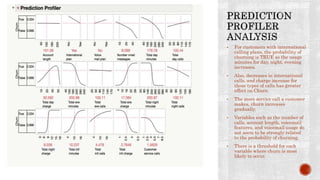
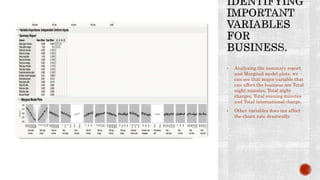
The document discusses a study conducted by a mobile phone company to analyze factors related to customer churn. The company provided a dataset of 3,332 customer records to build a neural network model that can predict which customers are likely to switch providers. Examining the data showed that increased usage of night, evening, and day minutes, as well as more customer service calls, correlated with higher churn. International calling plans also had a major impact on churn rates. The model achieved a misclassification rate of 7.11% and identified key variables for the company to address to reduce churn, such as international call pricing and infrastructure issues.