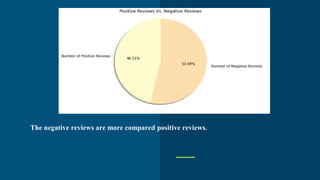
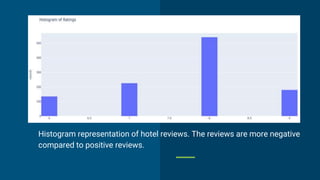
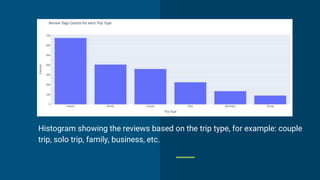
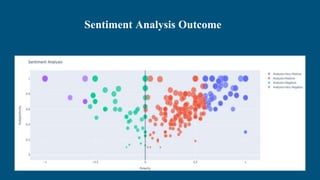
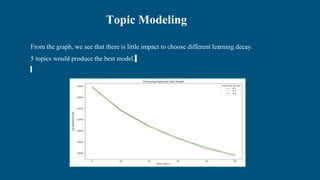
Sentiment analysis techniques are used to analyze customer reviews and understand sentiment. Lexical analysis uses dictionaries to analyze sentiment while machine learning uses labeled training data. The document describes using these techniques to analyze hotel reviews from Booking.com. Word clouds and scatter plots of reviews are generated, showing mostly negative sentiment around breakfast, staff, rooms and facilities. Topic modeling reveals specific issues to address like soundproofing, air conditioning and parking. The analysis helps the hotel manager understand customer sentiment and priorities for improvement.



























































![Demo_APSSDC_AIML_Project2222222222222222222221].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/demoapssdcaimlproject1-241216143243-bdeb62f7-thumbnail.jpg?width=640&height=640&fit=bounds)


























