The document discusses a project on financial loan prediction using machine learning to identify borrowers at risk of default. The analysis reveals key factors influencing default rates, including age, income, credit score, and employment status. Various machine learning models were tested, with Random Forest emerging as the most accurate for deployment.







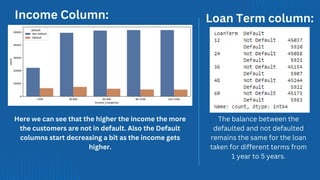


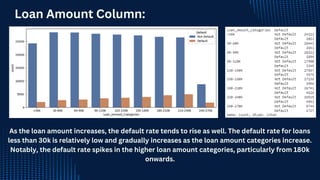






















































































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)









