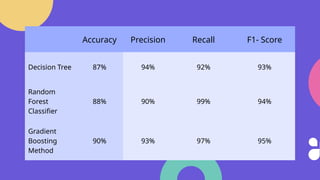
This project focuses on enhancing digital marketing campaign effectiveness by predicting customer conversions using machine learning. The study involves data preprocessing, model selection, and evaluation of decision tree, random forest, and gradient boosting methods, with gradient boosting showing the best overall performance. The final conclusion recommends using gradient boosting for improved classification performance.