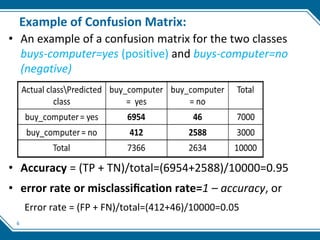
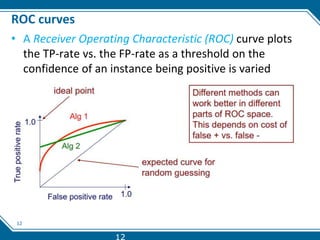
This document discusses evaluating machine learning model performance. It covers classification evaluation metrics like accuracy, precision, recall, F1 score, and confusion matrices. It also discusses regression metrics like MAE, MSE, and RMSE. The document discusses techniques for dealing with class imbalance like oversampling and undersampling. It provides examples of evaluating models and interpreting results based on these various performance metrics.