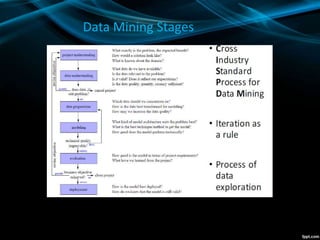
This document summarizes a machine learning project for an insurance company to predict customer purchasing behavior. It discusses:
- The objective is to predict the policy number and price a customer will purchase using historical customer data.
- The datasets include customer session and purchase histories. There is class imbalance with some policies having much more data than others.
- Data preprocessing included removing duplicates, outliers, and normalization. Feature selection used Pearson correlation to identify the most important features.
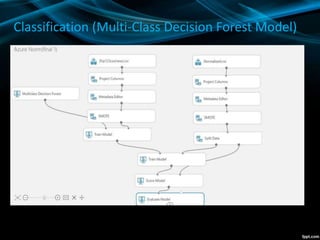
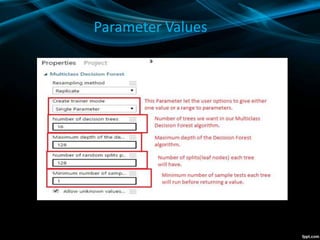
- SMOTE oversampling was used to address class imbalance for the policy number classification problem. Two models - decision forest and neural network - were evaluated for classification and regression.
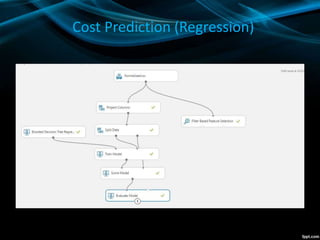
- The decision forest model performed best for classification, while boosted decision











































![[Isentek] eCompass API Quick Start](https://cdn.slidesharecdn.com/ss_thumbnails/isentekecompassapiquickstartv2-161115133752-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Isentek] eCompass API FAQ](https://cdn.slidesharecdn.com/ss_thumbnails/isentekecompassapifaqv2-161115133752-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Advantech] ADAM-3600 open vpn setting Tutorial step by step](https://cdn.slidesharecdn.com/ss_thumbnails/adam-3600openvpnsetting-161115132220-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Advantech] Modbus protocol training (ModbusTCP, ModbusRTU)](https://cdn.slidesharecdn.com/ss_thumbnails/modbustraining-161115125830-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Advantech] ADAM-3600 training kit and Taglink](https://cdn.slidesharecdn.com/ss_thumbnails/adam-3600trainingkit-161115133514-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Advantech] PAC SW Multiprog Tutorial step by step](https://cdn.slidesharecdn.com/ss_thumbnails/1-161115131531-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Advantech] WebOP designer Tutorial step by step](https://cdn.slidesharecdn.com/ss_thumbnails/1-161115131640-thumbnail.jpg?width=640&height=640&fit=bounds)



















