Downloaded 253 times


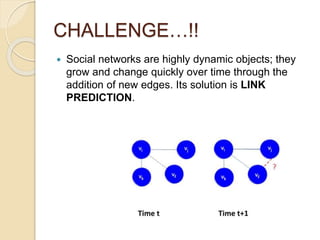



























The document discusses link prediction in social networks, emphasizing its importance and the challenges due to the dynamic nature of social networks. It outlines various applications of link prediction, such as identifying criminal networks and enhancing recommendation systems, and introduces specific algorithms like common neighbors and Jaccard coefficient. The proposed social networking application includes features like user registration, friend suggestions, and methods for calculating user strengths based on centrality measures.

































![[20150829, PyCon2015] NetworkX를 이용한 네트워크 링크 예측](https://cdn.slidesharecdn.com/ss_thumbnails/20150829pyconnetworkx-150829023538-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)













































