Downloaded 13 times




















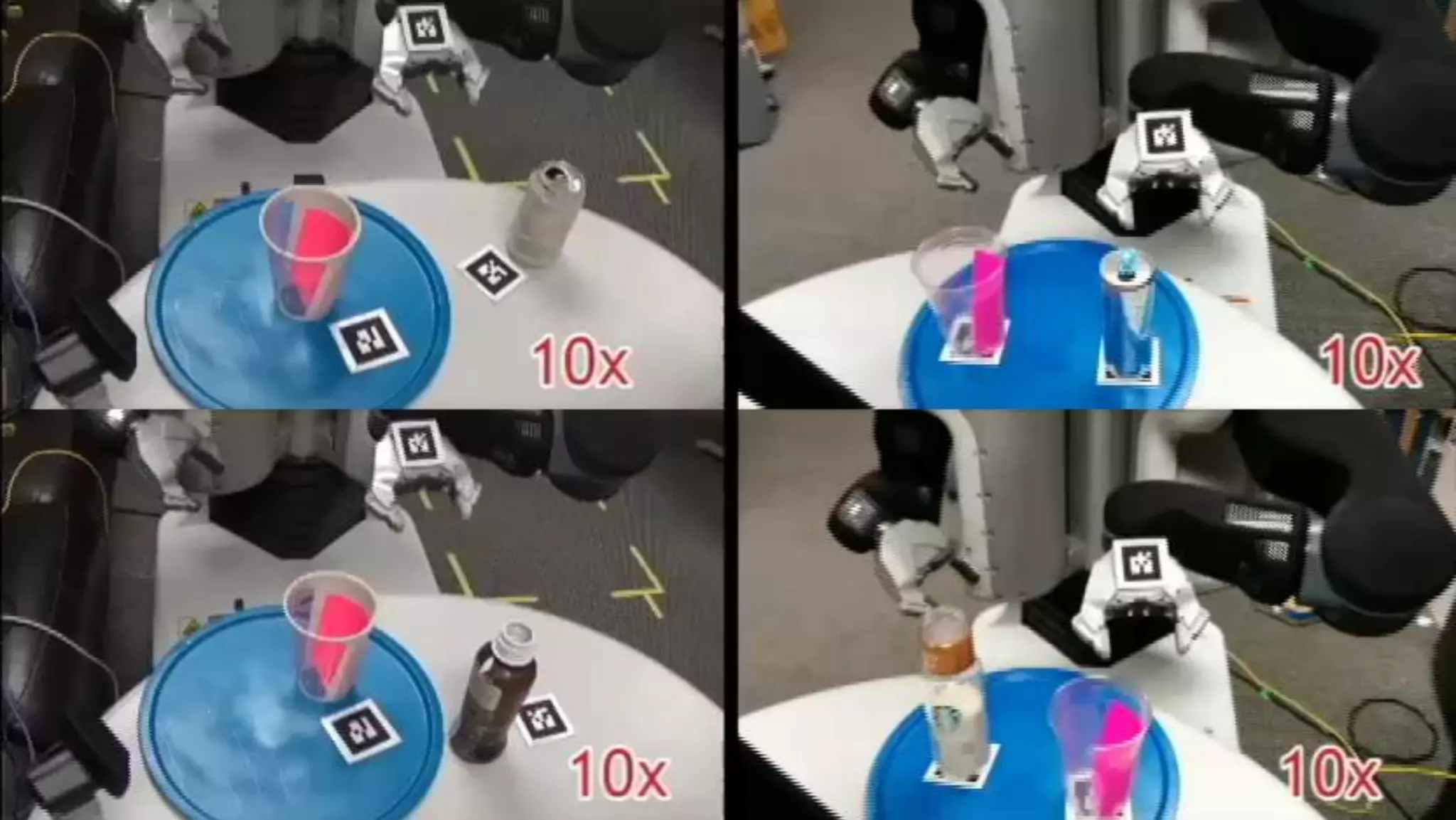





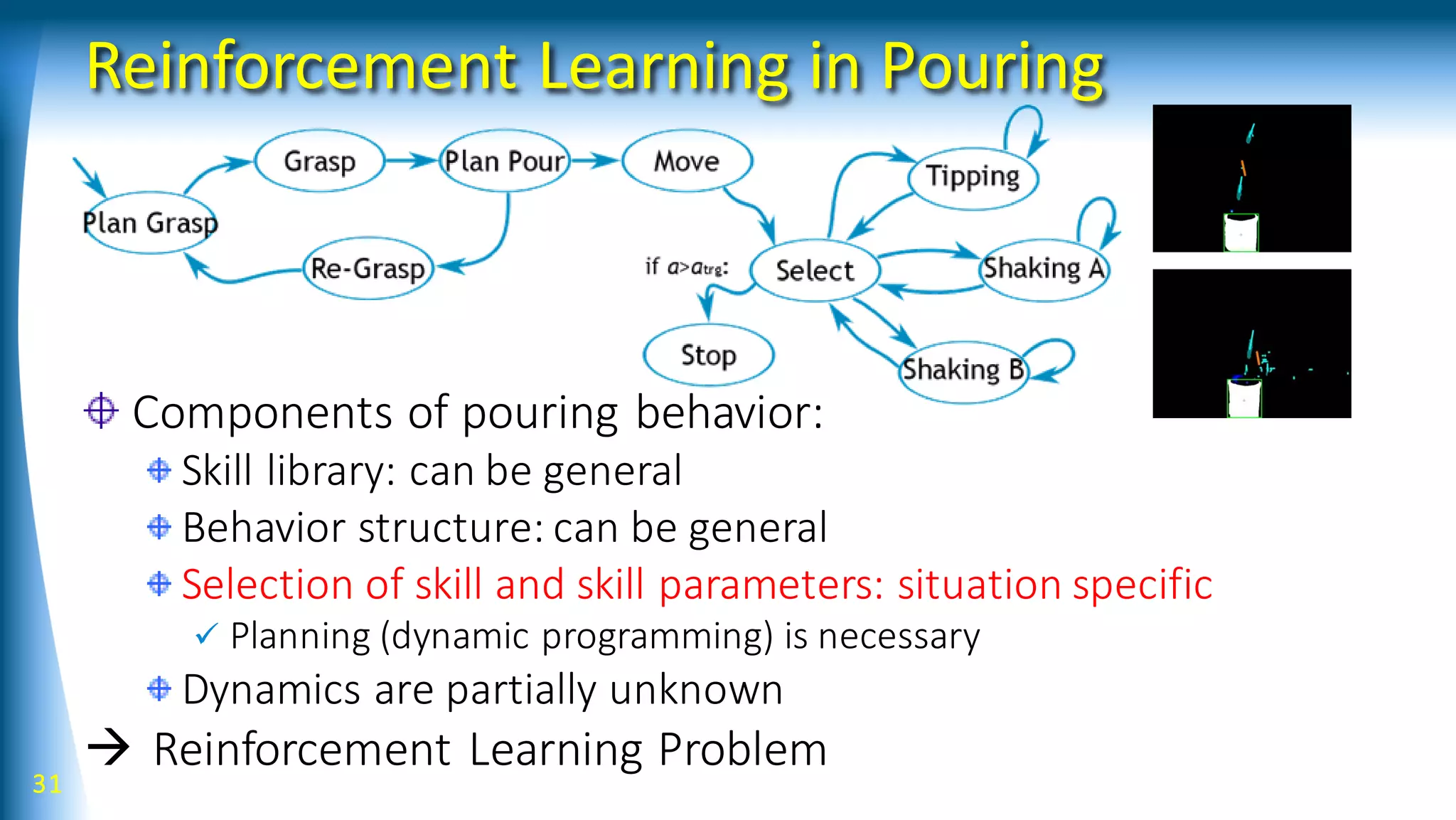
![Reinforcement Learning
32
[ReinforcementLearning]
[DirectPolicySearch] [ValueFunction-based]
[Model-based]
[Model-free]
RL RL SL
[DynamicProgramming][Optimization]
Planning
depth
Learning
complexity
[Policy] [ValueFunctions] [ForwardModels]What is
learned
0 1 N](https://image.slidesharecdn.com/talk201707s-170824135245/75/Robot-Learning-with-Structured-Knowledge-And-Richer-Sensing-32-2048.jpg)
![33
[Direct PolicySearch]
[Value Function-based]
[Model-based]](https://image.slidesharecdn.com/talk201707s-170824135245/75/Robot-Learning-with-Structured-Knowledge-And-Richer-Sensing-33-2048.jpg)
![Model-free is tend to obtain better performance
34
[Kober,Peters,2011] [Kormushev,2010]](https://image.slidesharecdn.com/talk201707s-170824135245/75/Robot-Learning-with-Structured-Knowledge-And-Richer-Sensing-34-2048.jpg)

![Model-based is suffered from simulation biases
36
Simulation bias: When forward models are inaccurate (usual when
learning models), integrating the forward models causes a rapid
increase of future state estimation errors
cf. [Atkeson,Schaal,1997b][Kober,Peters,2013]](https://image.slidesharecdn.com/talk201707s-170824135245/75/Robot-Learning-with-Structured-Knowledge-And-Richer-Sensing-36-2048.jpg)
![Model-based is good at generalization
37
input
output
hidden
- u
update
FK ANN
Learning inverse kinematics of android face
[Magtanong, Yamaguchi, et al. 2012]](https://image.slidesharecdn.com/talk201707s-170824135245/75/Robot-Learning-with-Structured-Knowledge-And-Richer-Sensing-37-2048.jpg)
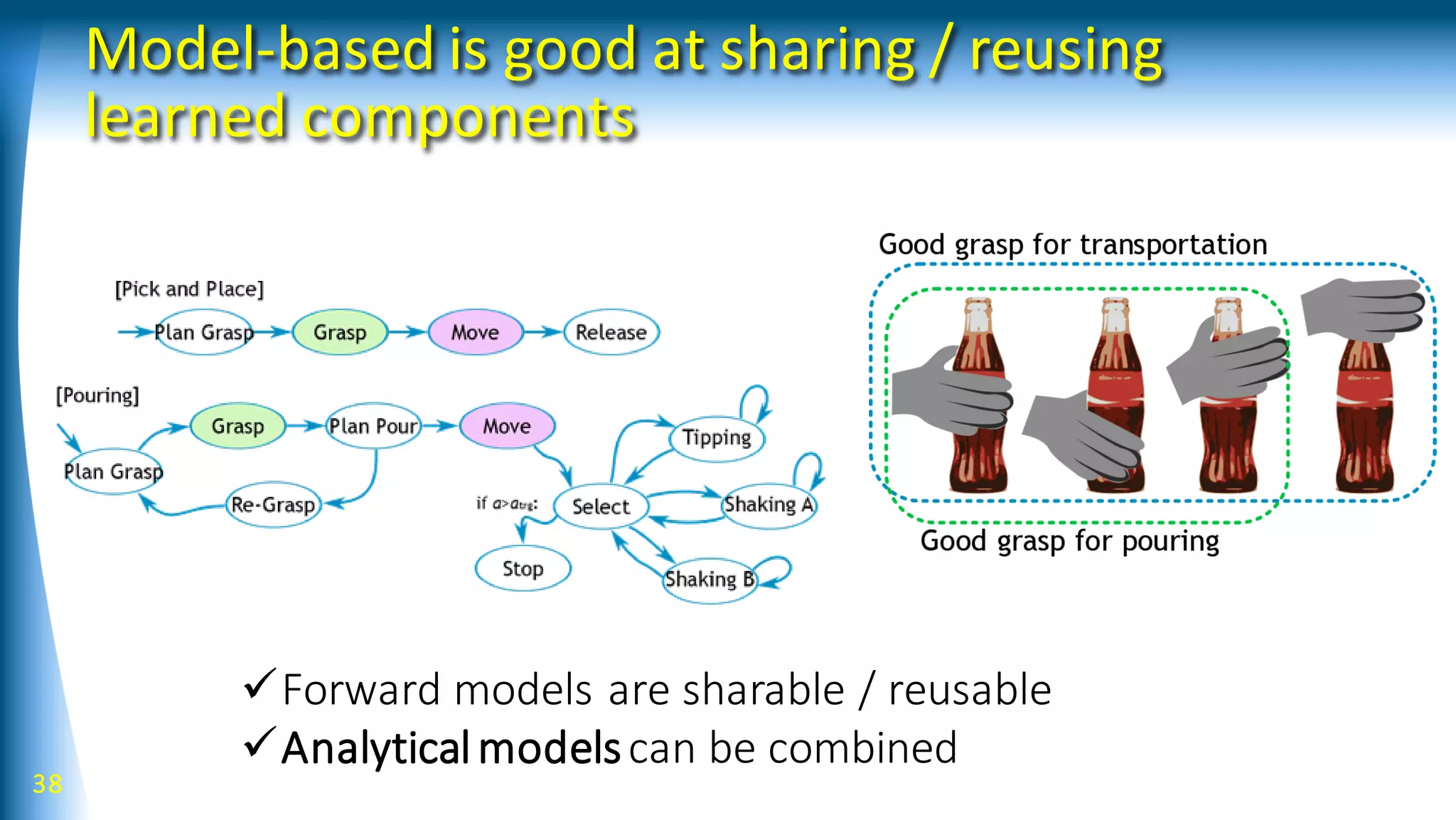
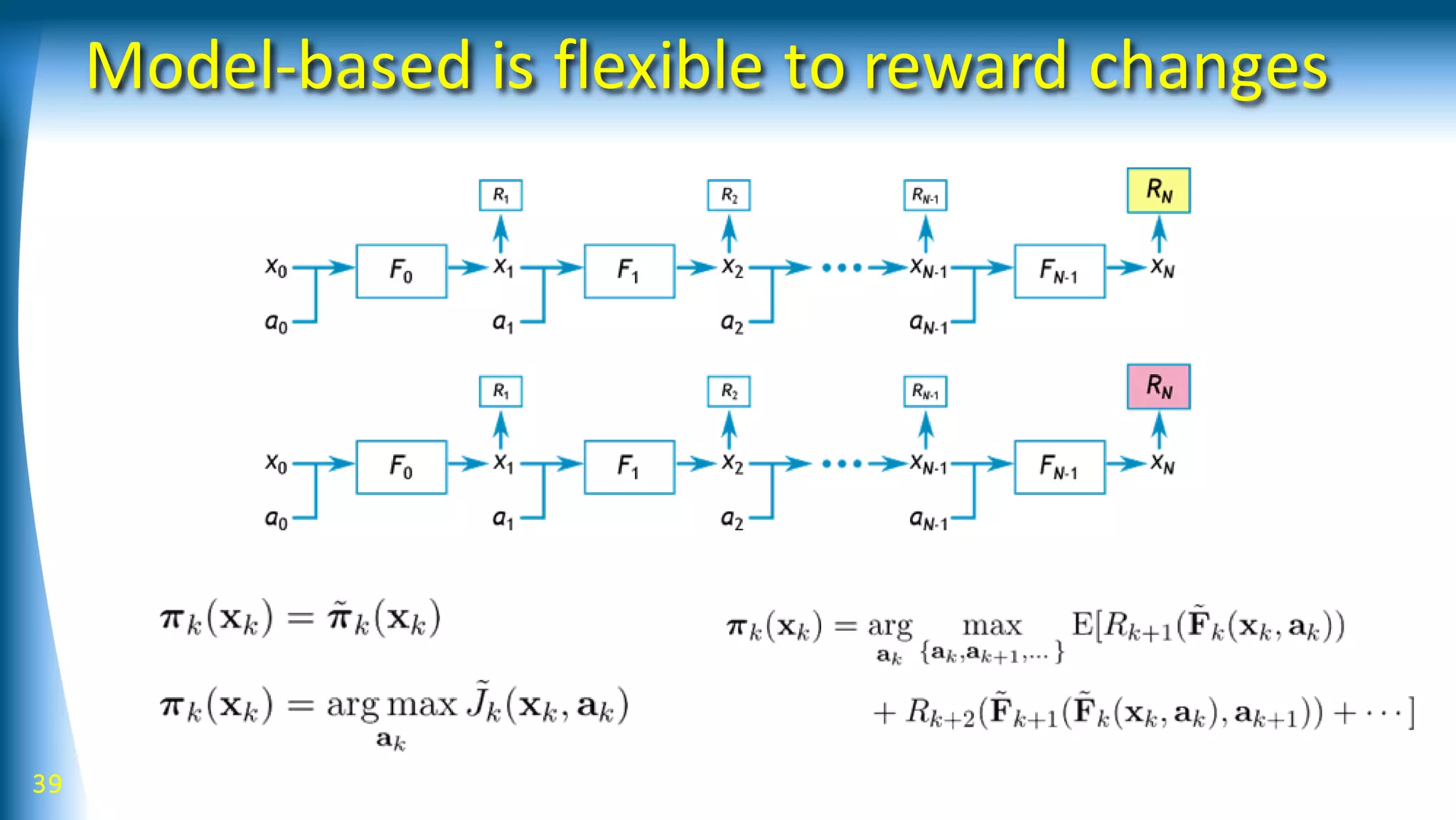
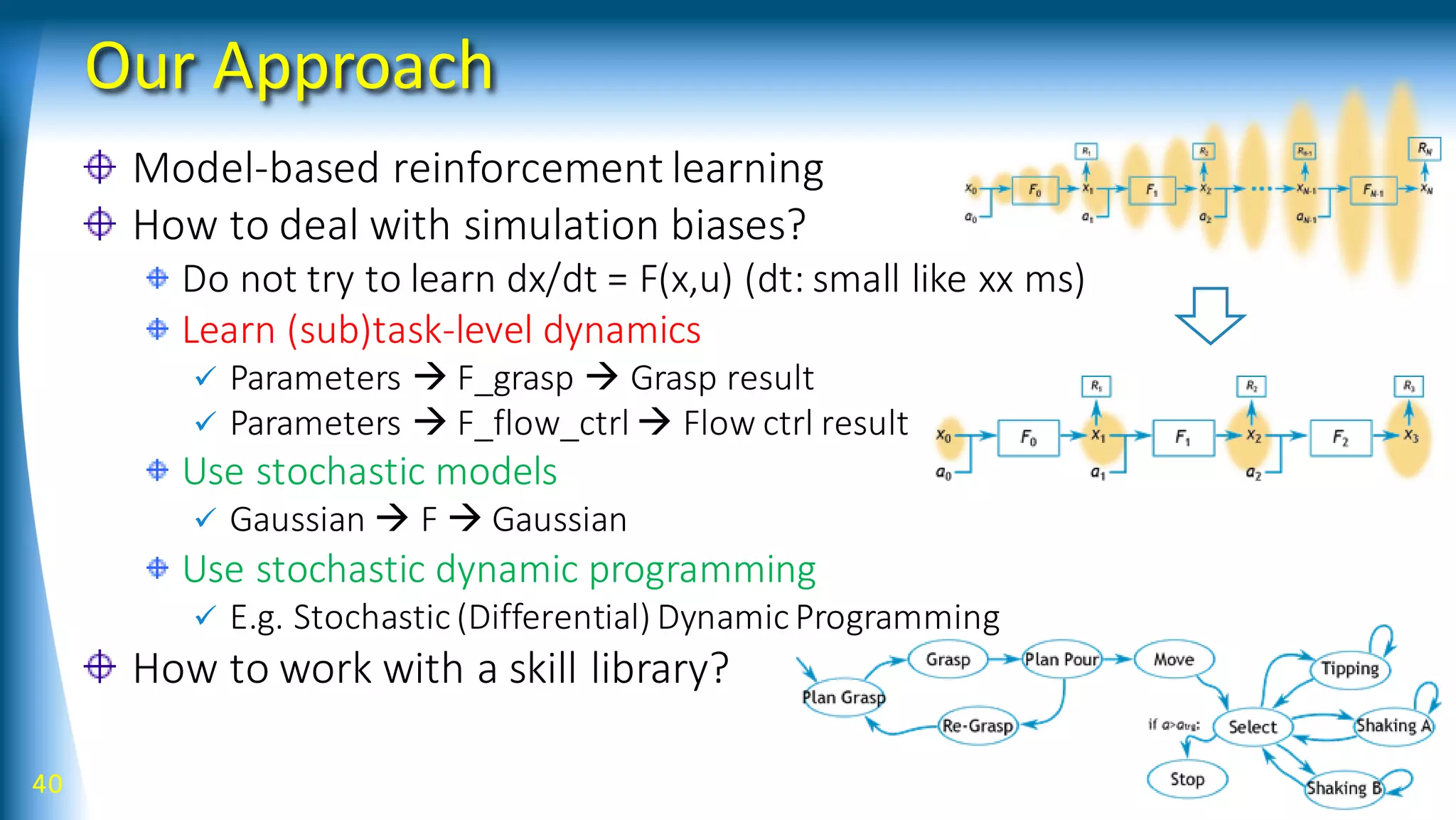
![42
Forward model can be:
• Dynamical system with/wo action
parameters
• Kinematics
• Featuredetection, Policy
parameterization
• Reward
• …
Bifurcation model can be:
• Possible different results of an action
• Skill selection
• Spatial decomposition of dynamics
• Spatial conversion, including
kinematics, feature detection, policy
parameterization, and rewards
• …
GraphDDP
Bifurcation primitive
[Yamaguchi andAtkeson, Humanoids2015, 2016]](https://image.slidesharecdn.com/talk201707s-170824135245/75/Robot-Learning-with-Structured-Knowledge-And-Richer-Sensing-42-2048.jpg)
![43
GraphDDP
Bifurcation primitive
[Yamaguchi andAtkeson, Humanoids2015, 2016]
Skill selection
Possibledifferent results of an action
Reward
Spatial decomposition of dynamics](https://image.slidesharecdn.com/talk201707s-170824135245/75/Robot-Learning-with-Structured-Knowledge-And-Richer-Sensing-43-2048.jpg)
![44
GraphDDP
Bifurcation primitive
[Yamaguchi andAtkeson, Humanoids2015, 2016]](https://image.slidesharecdn.com/talk201707s-170824135245/75/Robot-Learning-with-Structured-Knowledge-And-Richer-Sensing-44-2048.jpg)
![45
Tree DDP with multi-point search
GraphDDP
Graphstructure analysis
[Yamaguchi andAtkeson, Humanoids2015, 2016]](https://image.slidesharecdn.com/talk201707s-170824135245/75/Robot-Learning-with-Structured-Knowledge-And-Richer-Sensing-45-2048.jpg)
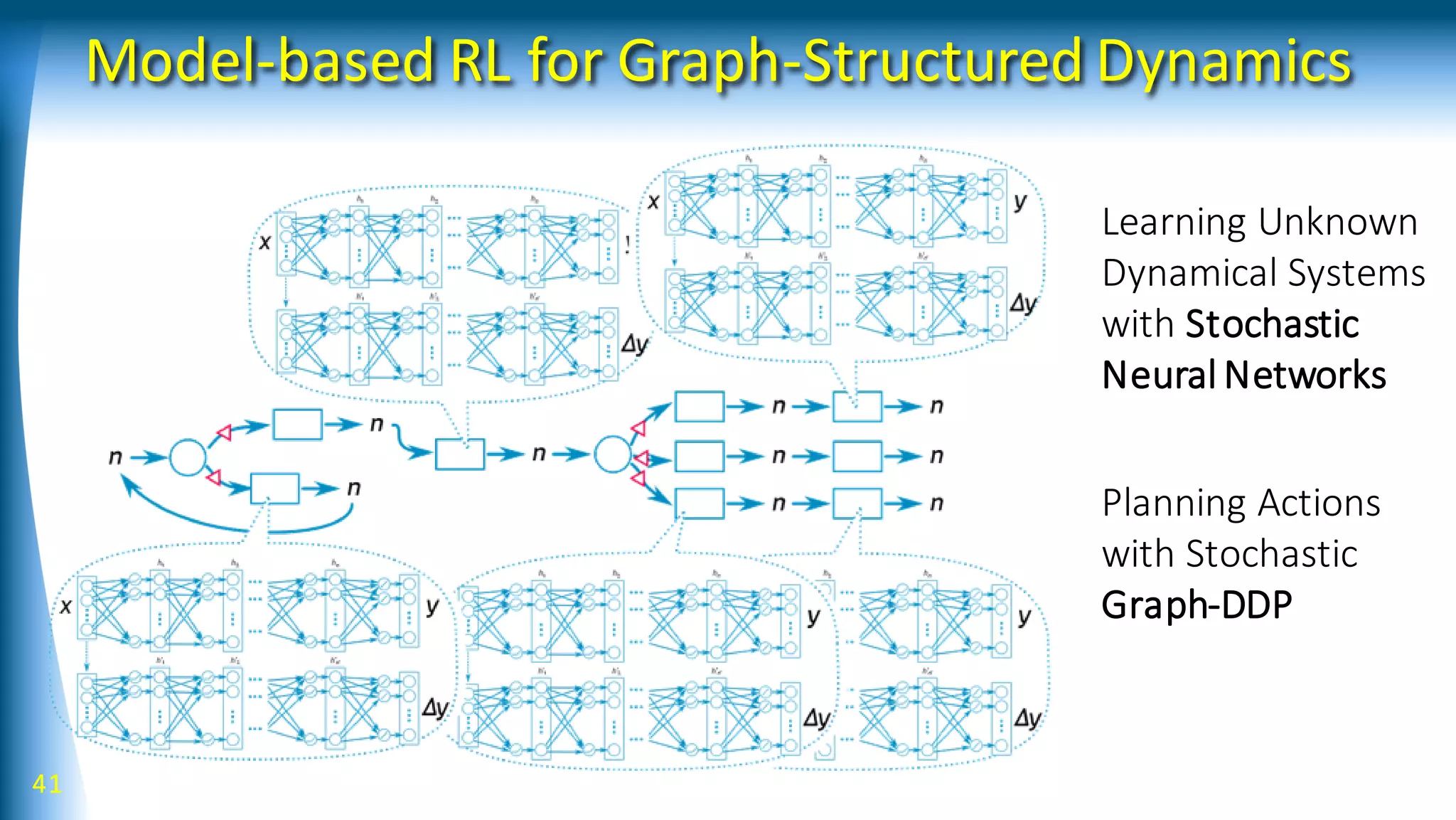
![46 [Yamaguchi andAtkeson, ICRA 2016]
Stochastic Neural Networks](https://image.slidesharecdn.com/talk201707s-170824135245/75/Robot-Learning-with-Structured-Knowledge-And-Richer-Sensing-46-2048.jpg)
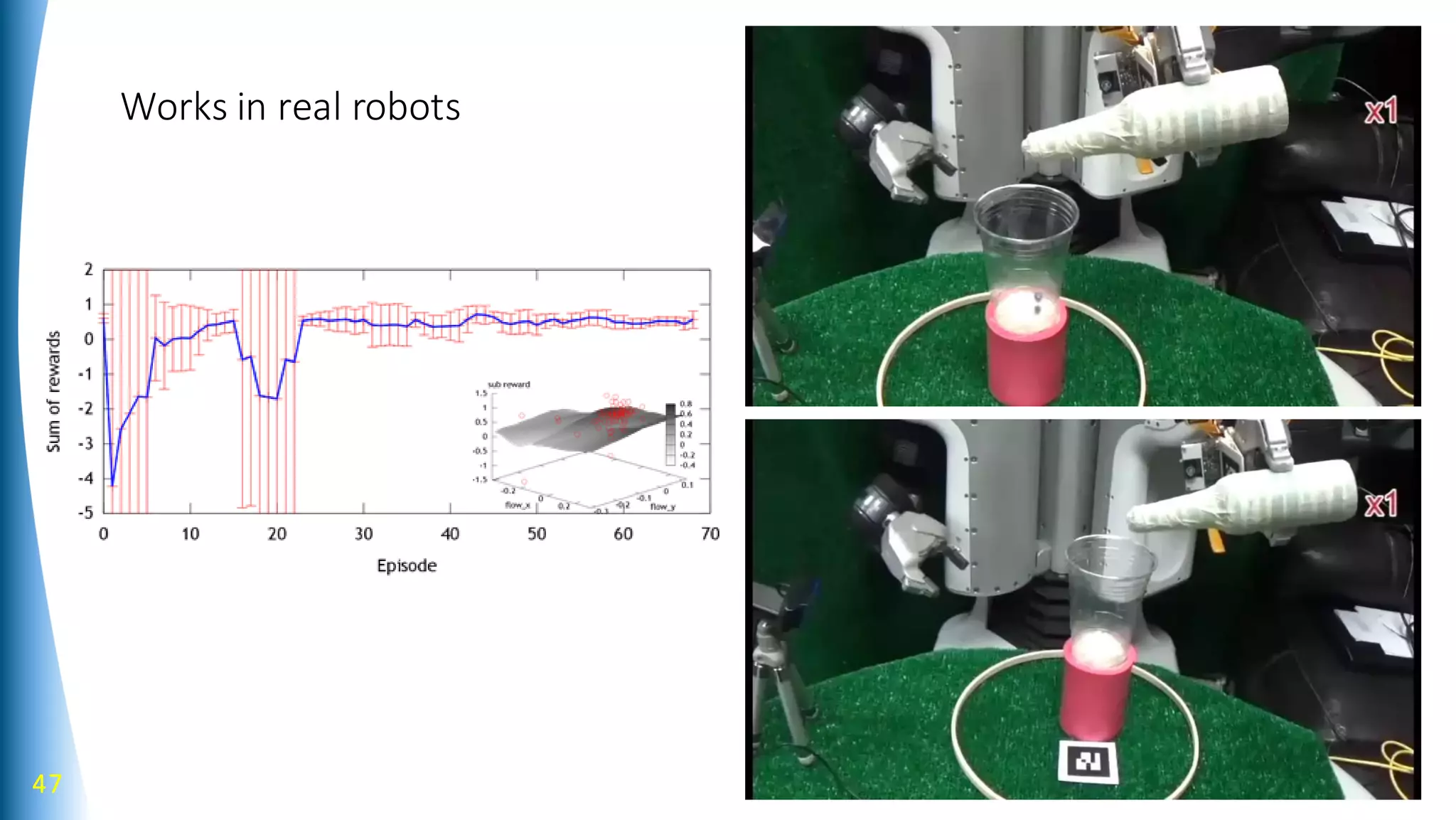
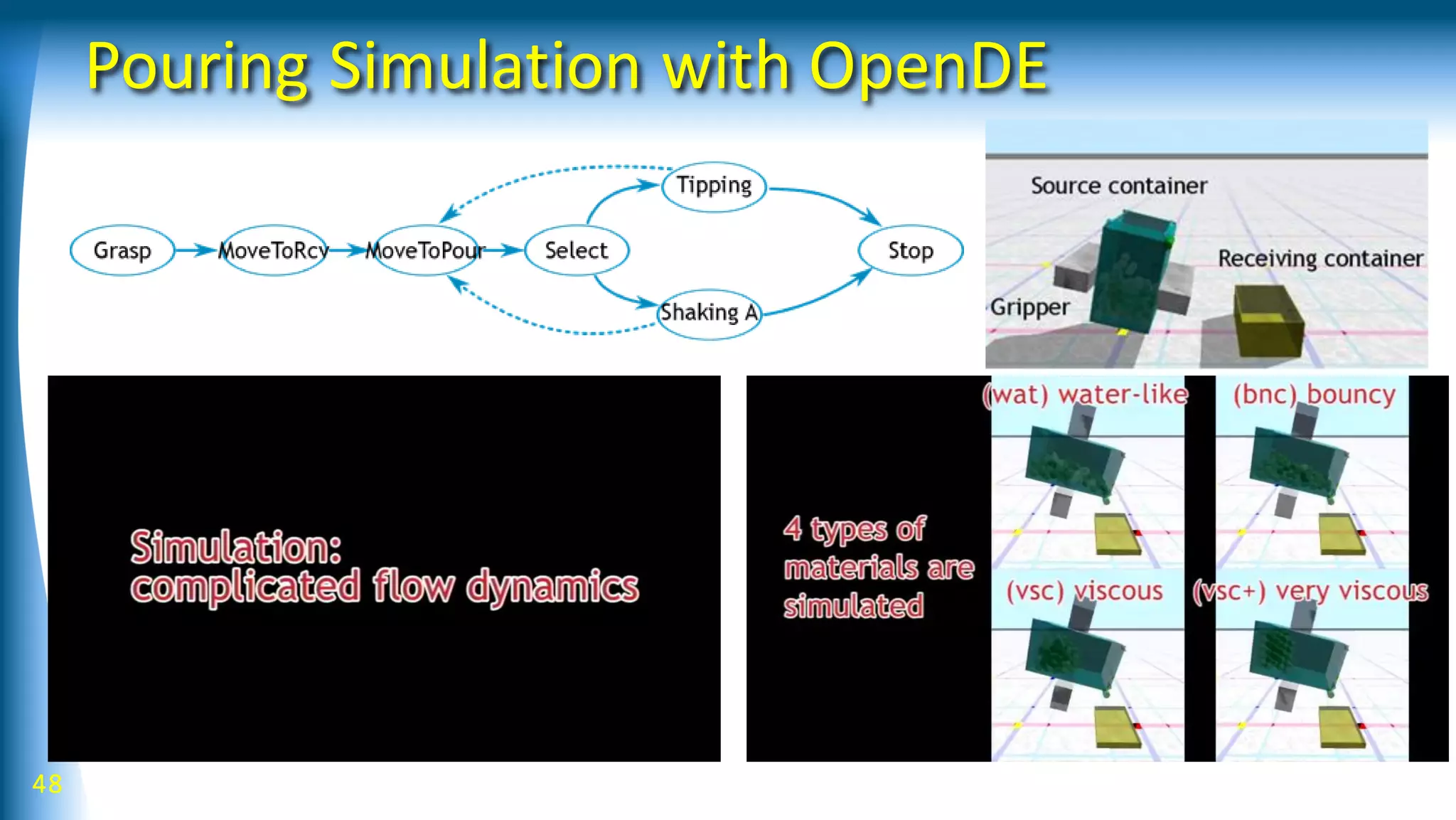
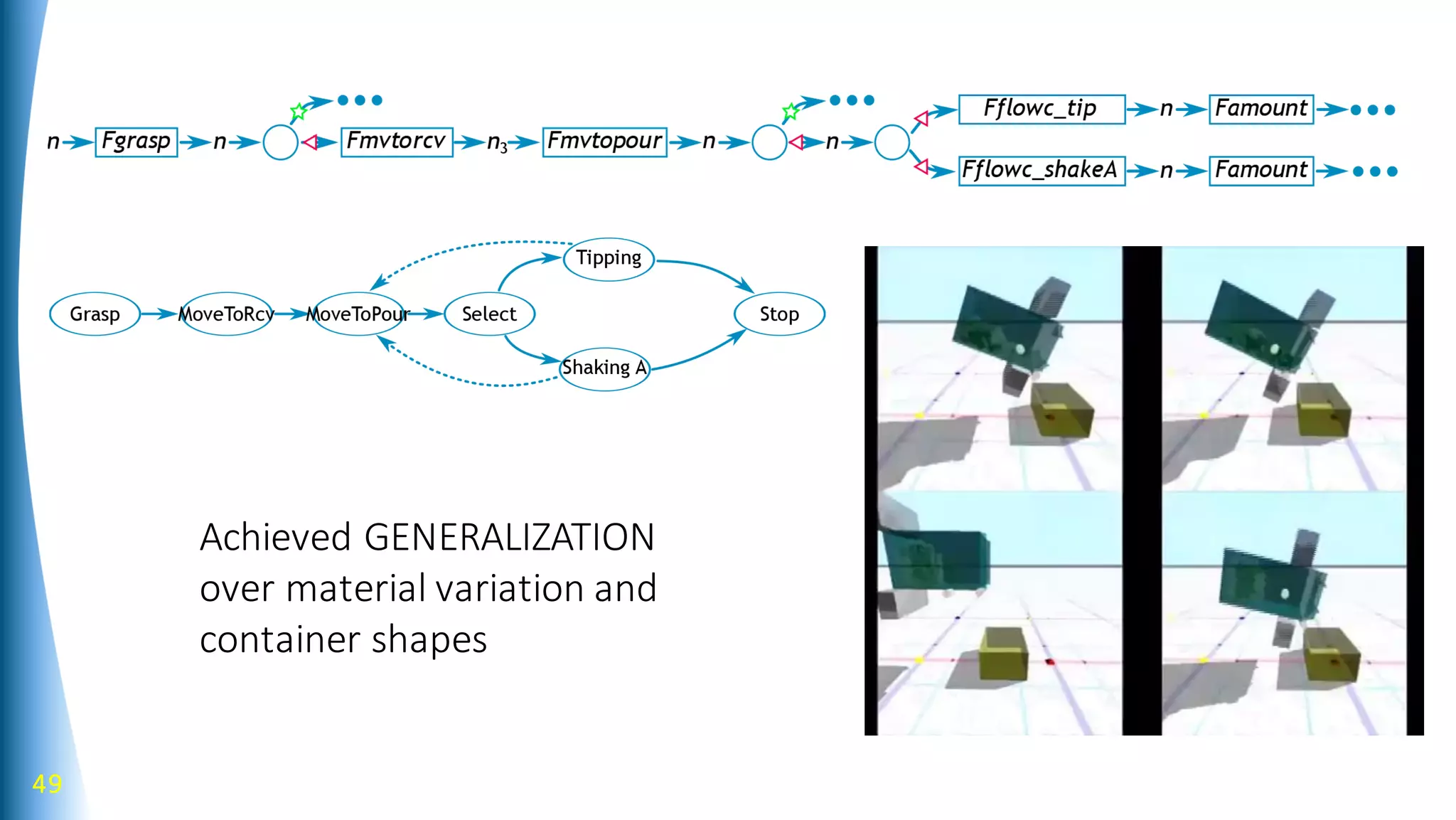


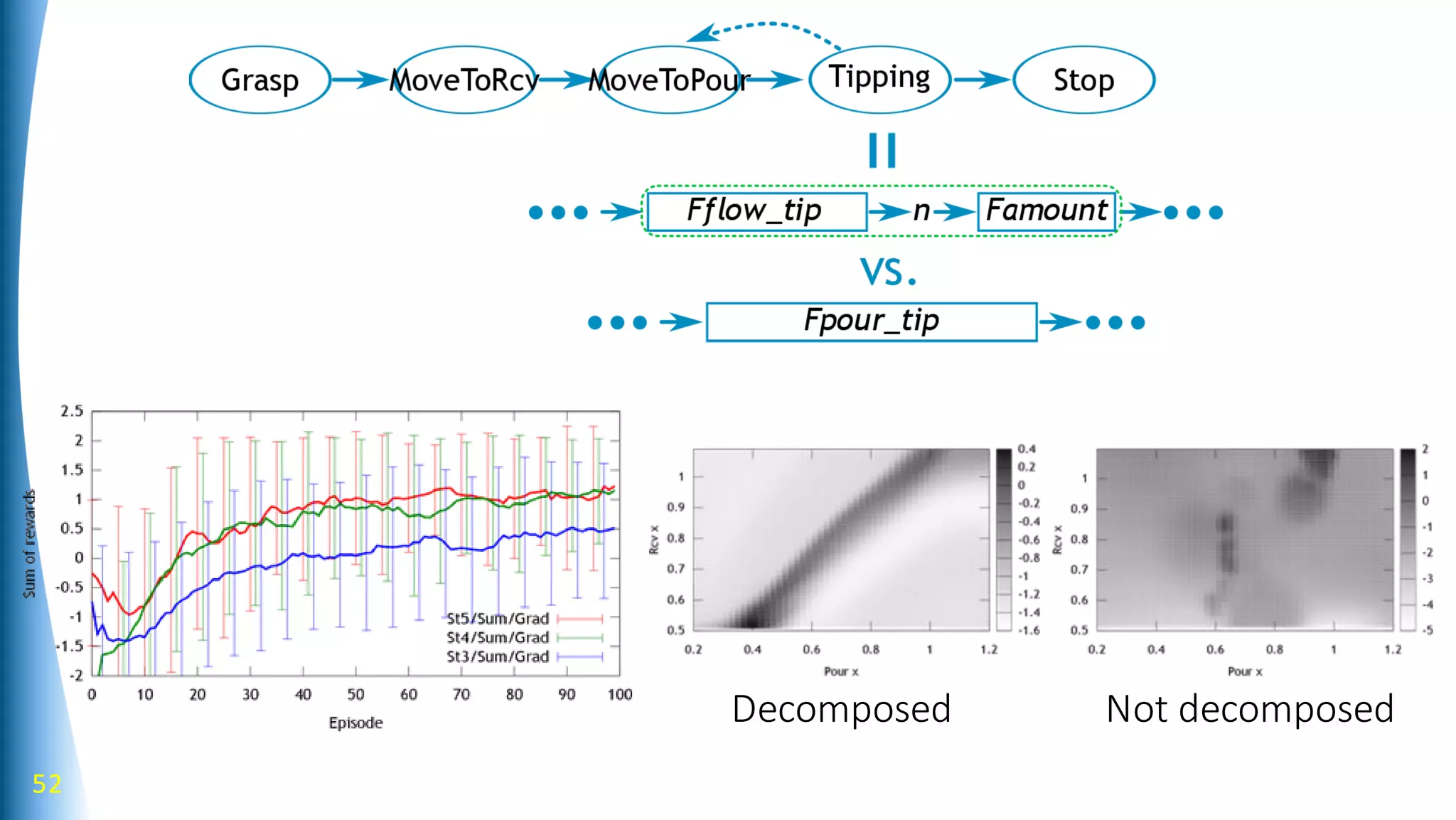




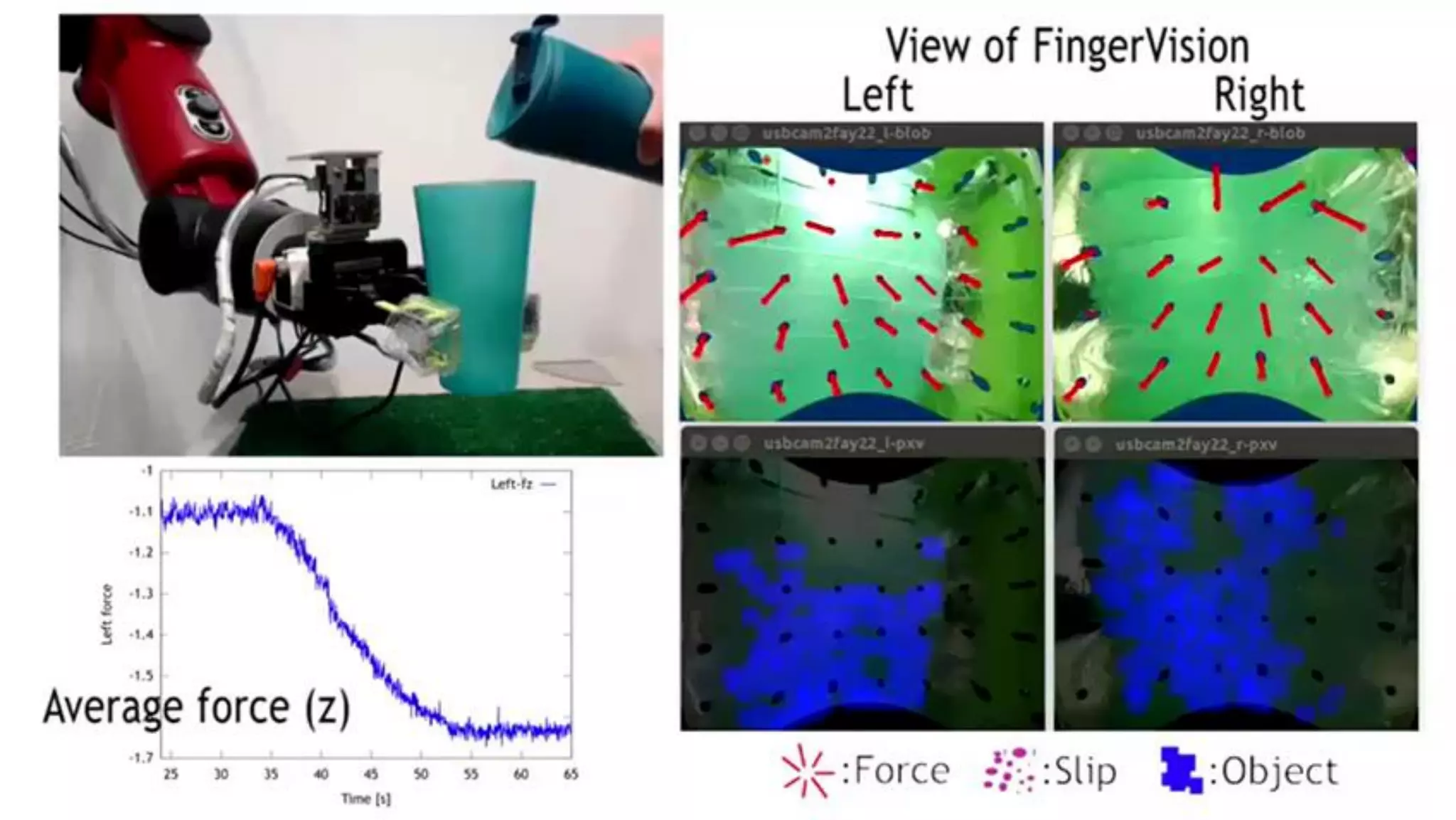




Robot learning can be improved by using a structured library of skills, modeling behaviors as graphs with bifurcating dynamics, and incorporating richer sensing. The presented work develops a model-based reinforcement learning approach using stochastic neural networks to learn forward models and stochastic Graph-DDP for planning. This achieves generalization of pouring skills over different materials through decomposition of dynamics into flow and amount, and demonstrates how tactile sensing can support manipulation. Overall, the use of structured representations, model-based learning, and multimodal sensing were shown to enhance robot skill acquisition and generalization.












![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

