Downloaded 80 times






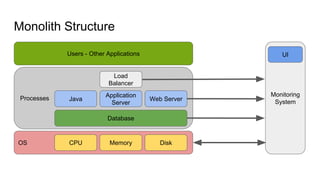
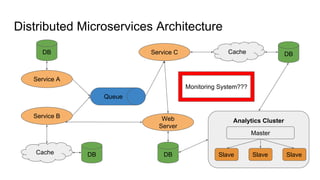




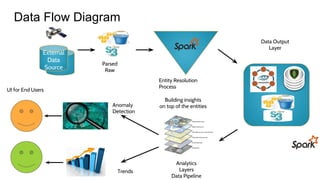
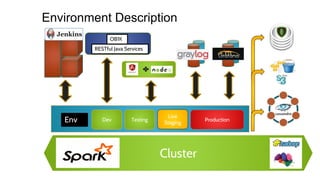

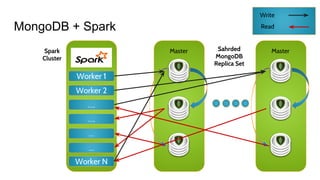
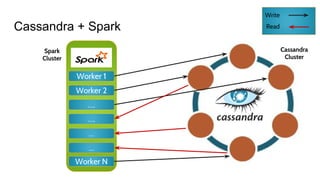
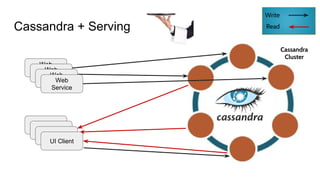



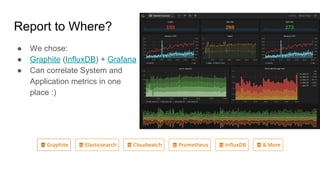





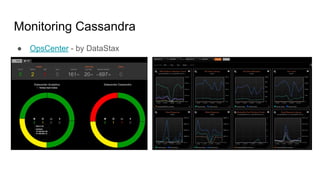

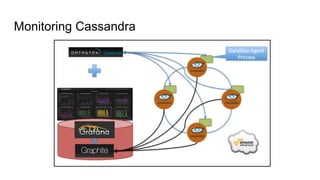
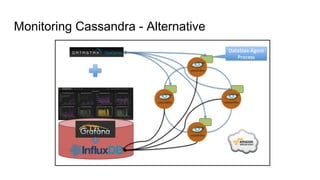

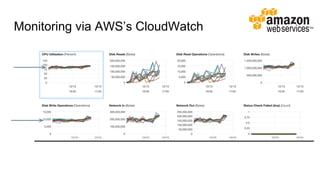
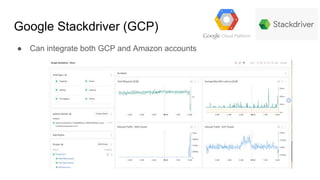


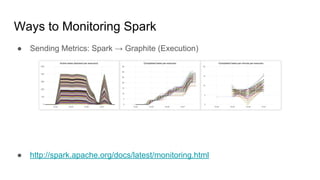
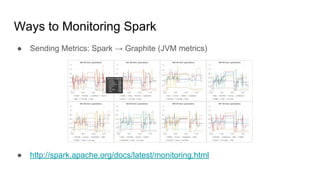






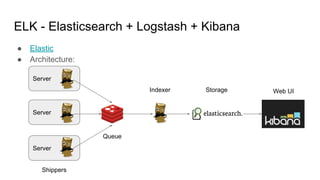
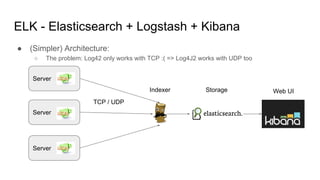
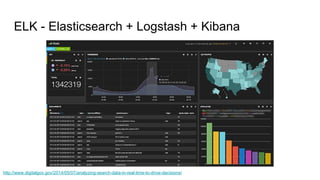
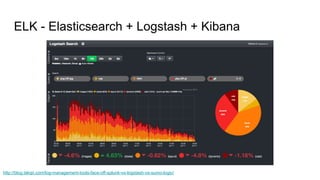






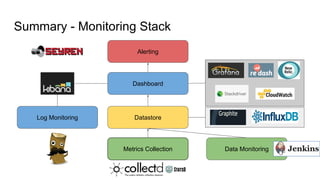





The document discusses the monitoring of big data systems, emphasizing the importance of metrics, alerting, and dashboards in understanding system performance. It outlines key concepts like white-box and black-box monitoring, various monitoring tools, and techniques specific to technologies such as Cassandra and Spark. The conclusion highlights the need for correlating application and system metrics, asking the right questions, and the overall necessity of monitoring to improve performance and ensure reliability.










































![[오픈소스컨설팅]Zabbix Installation and Configuration Guide](https://cdn.slidesharecdn.com/ss_thumbnails/zabbixinstallationconfigurationguide-130702191713-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)