Download as PDF, PPTX





![© Hortonworks Inc. 2011
Apache Hadoop in Review
• Apache Hadoop Distributed Filesystem (HDFS)
– Distributed, fault-tolerant, throughput-optimized data storage
– Uses a filesystem analogy, not structured tables
– The Google File System, 2003, Ghemawat et al.
– http://research.google.com/archive/gfs.html
• Apache Hadoop MapReduce (MR)
– Distributed, fault-tolerant, batch-oriented data processing
– Line- or record-oriented processing of the entire dataset *
– “[Application] schema on read”
– MapReduce: Simplified Data Processing on Large Clusters, 2004, Dean and
Ghemawat
– http://research.google.com/archive/mapreduce.html
Page 5
Architecting the Future of Big Data
* For more on writing MapReduce applications, see “MapReduce
Patterns, Algorithms, and Use Cases”
http://highlyscalable.wordpress.com/2012/02/01/mapreduce-patterns/](https://image.slidesharecdn.com/cartographytothecloud-130528133748-phpapp02/85/Bring-Cartography-to-the-Cloud-5-320.jpg)
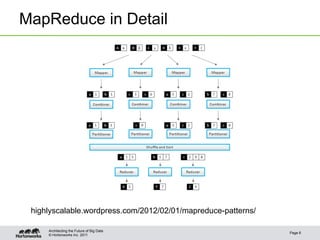
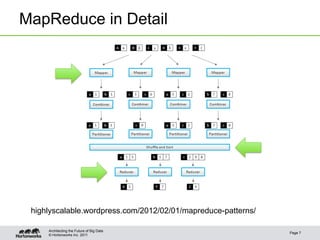






![© Hortonworks Inc. 2011
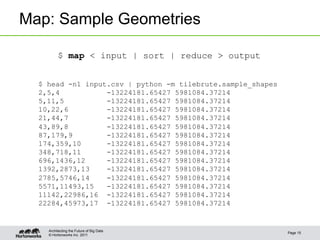
Map: Sample Geometries
Page 14
Architecting the Future of Big Data
[,[WKT, population]] => mapper => ['tx,ty,z', 'px,py']
def main():
for geom, population in read_feature(stdin):
for lng, lat in sample_geometry(geom, population):
for key, val in make_kv(lat, lng):
emit(key, val)
$ map < input | sort | reduce > output](https://image.slidesharecdn.com/cartographytothecloud-130528133748-phpapp02/85/Bring-Cartography-to-the-Cloud-14-320.jpg)
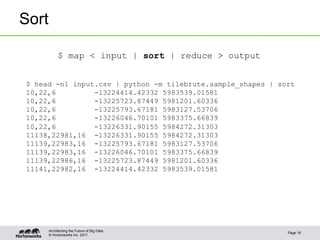
![© Hortonworks Inc. 2011
Reduce: Draw Tiles
Page 17
Architecting the Future of Big Data
def main():
for tile,points in groupby(read_points(stdin), lambda x: x[0]):
zoom = get_zoom(tile)
map = init_map(zoom, points)
map.zoom_all()
im = mapnik.Image(256,256)
mapnik.render(map,im)
emit(tile, encode_image(im))
$ map < input | sort | reduce > output
$ head -n1 input.csv | python -m tilebrute.sample_shapes | sort | head -n5 |
python -m tilebrute.draw_tiles
10,22,6 iVBORw0KGgoAAAANSUhEUgAAAQAAAAEACAYAAABccqhmAAADJ...+aBAAAAAElFTkSuQmCC](https://image.slidesharecdn.com/cartographytothecloud-130528133748-phpapp02/85/Bring-Cartography-to-the-Cloud-17-320.jpg)
![© Hortonworks Inc. 2011
Write Output
Page 18
Architecting the Future of Big Data
public void write(Text tileId, Text tile) throws IOException {
String[] tileIdSplits = tileId.toString().split(",");
assert tileIdSplits.length == 3;
String tx = tileIdSplits[0];
String ty = tileIdSplits[1];
String zoom = tileIdSplits[2];
Path tilePath = new Path(outputPath, zoom + "/" + tx + "/" + ty + ".png");
fs.mkdirs(tilePath.getParent());
byte[] buf = Base64.decodeBase64(tile.toString());
final FSDataOutputStream fout = fs.create(tilePath, progress);
fout.write(buf);
fout.close();
}](https://image.slidesharecdn.com/cartographytothecloud-130528133748-phpapp02/85/Bring-Cartography-to-the-Cloud-18-320.jpg)










The document discusses the integration of cartography with cloud-based technologies, particularly using Apache Hadoop for handling large geographic datasets. It details the processes involved in data preparation, processing, and tile generation while utilizing tools like Python and GIS libraries. Additionally, it highlights the performance metrics of various configurations and proposes further optimization strategies.



























































