Download to read offline




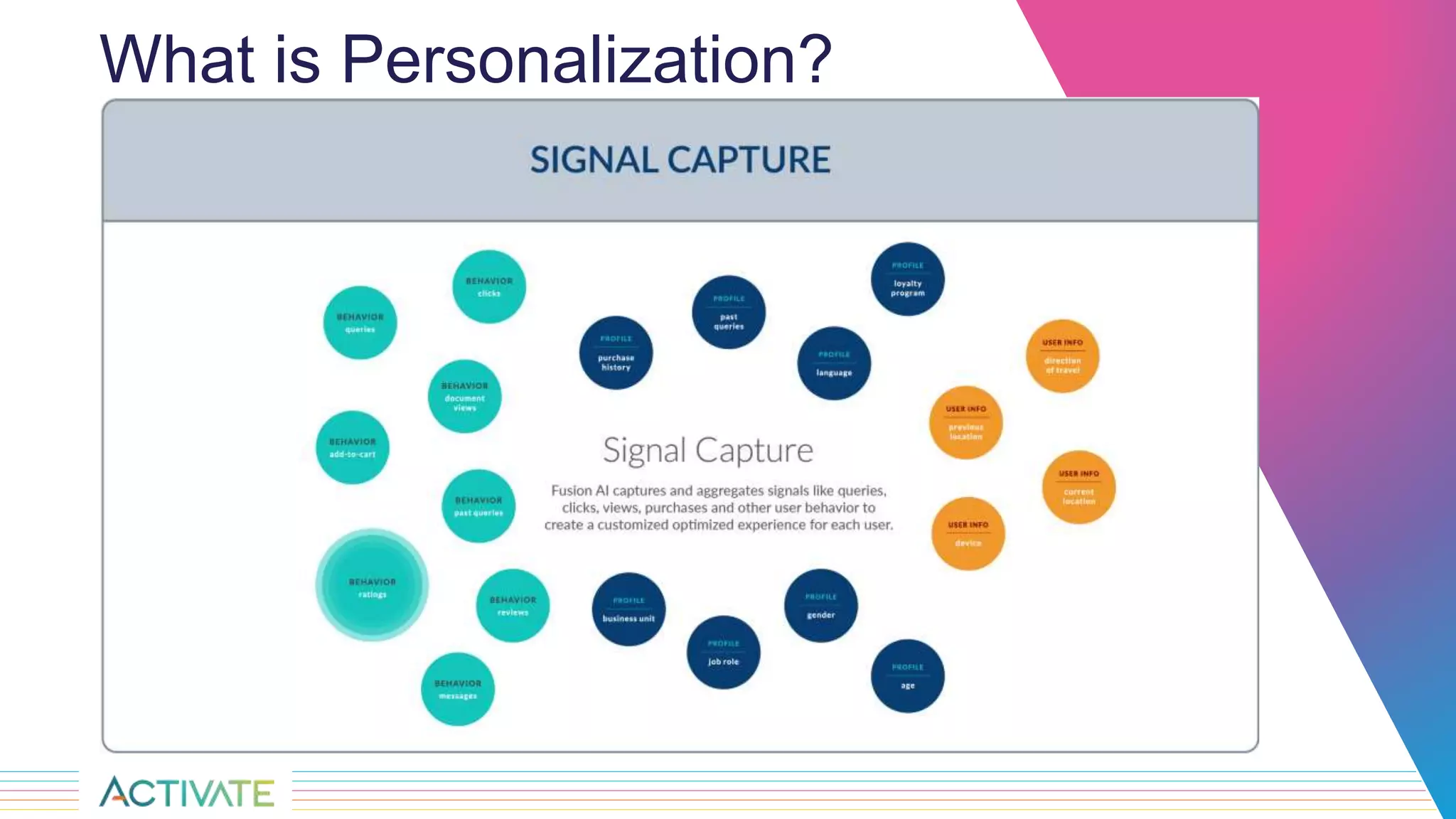




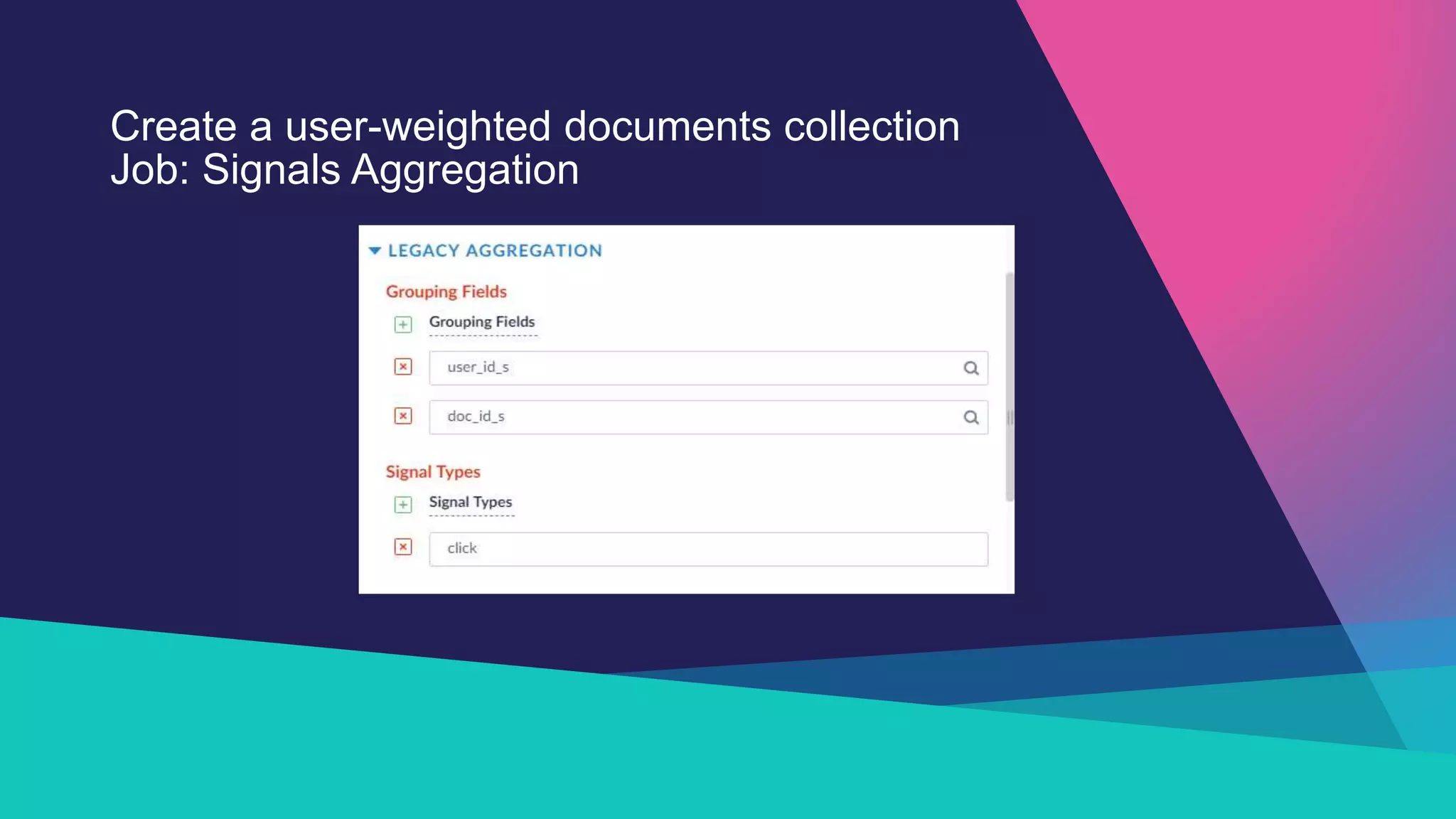
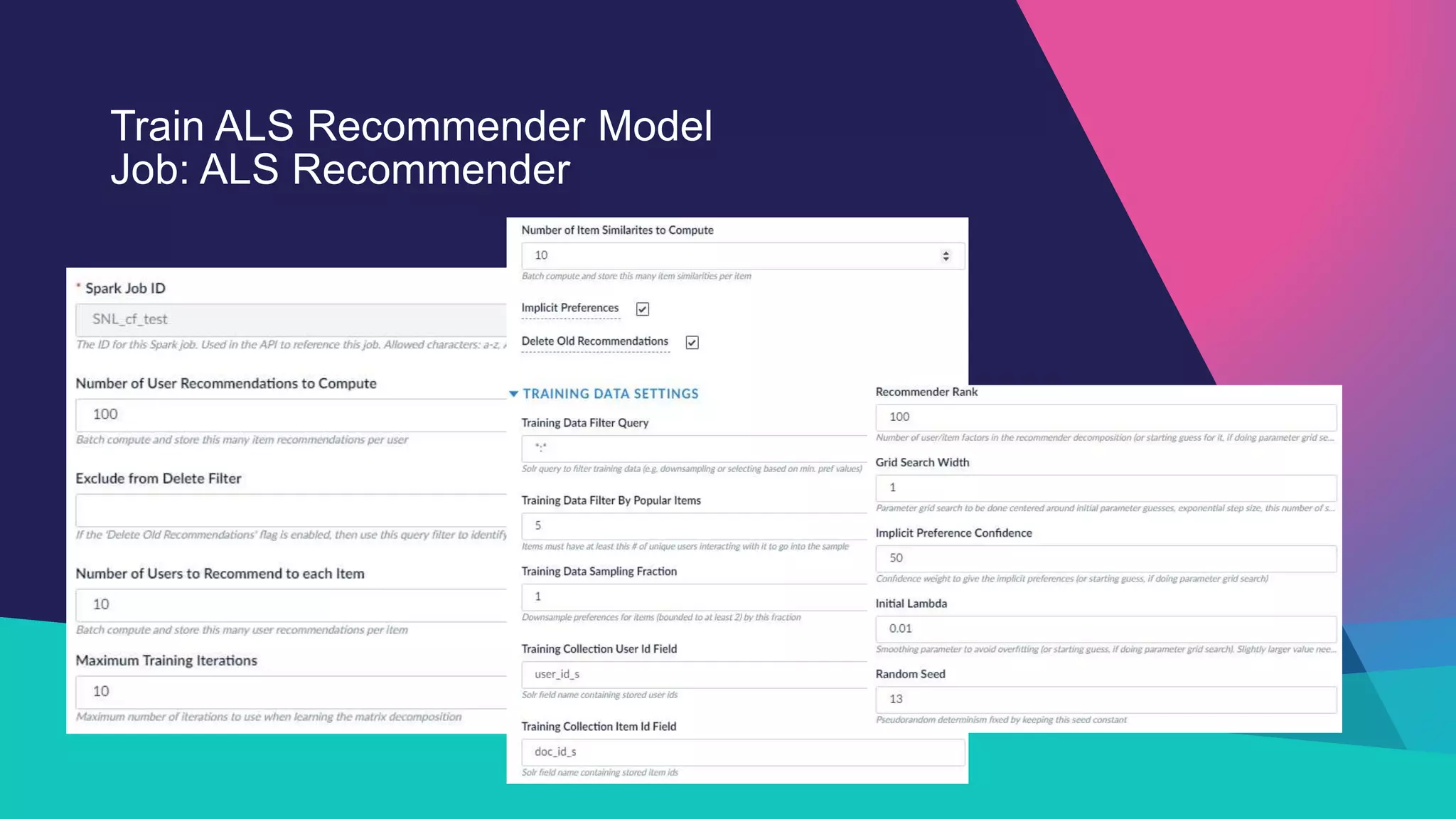
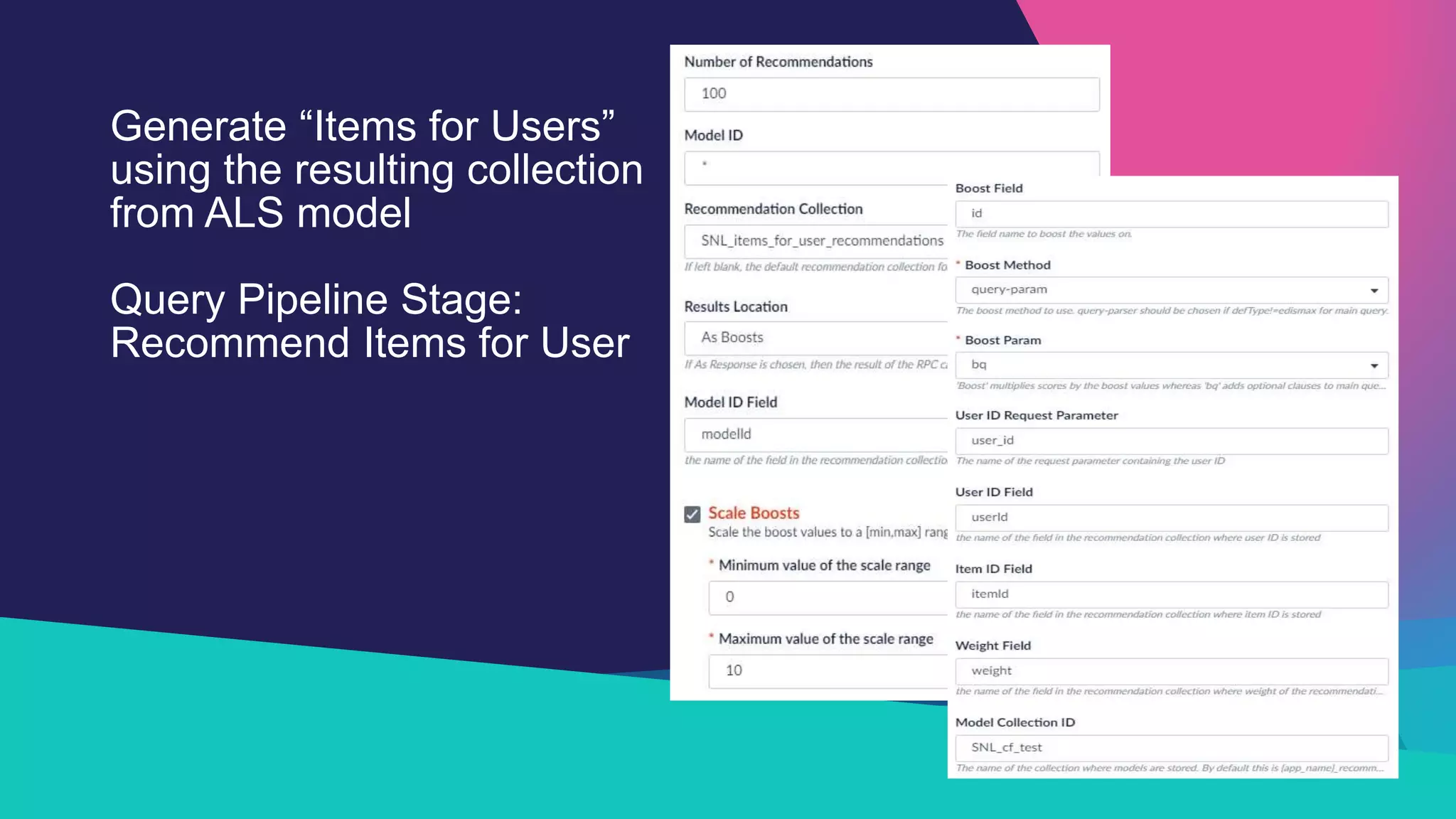

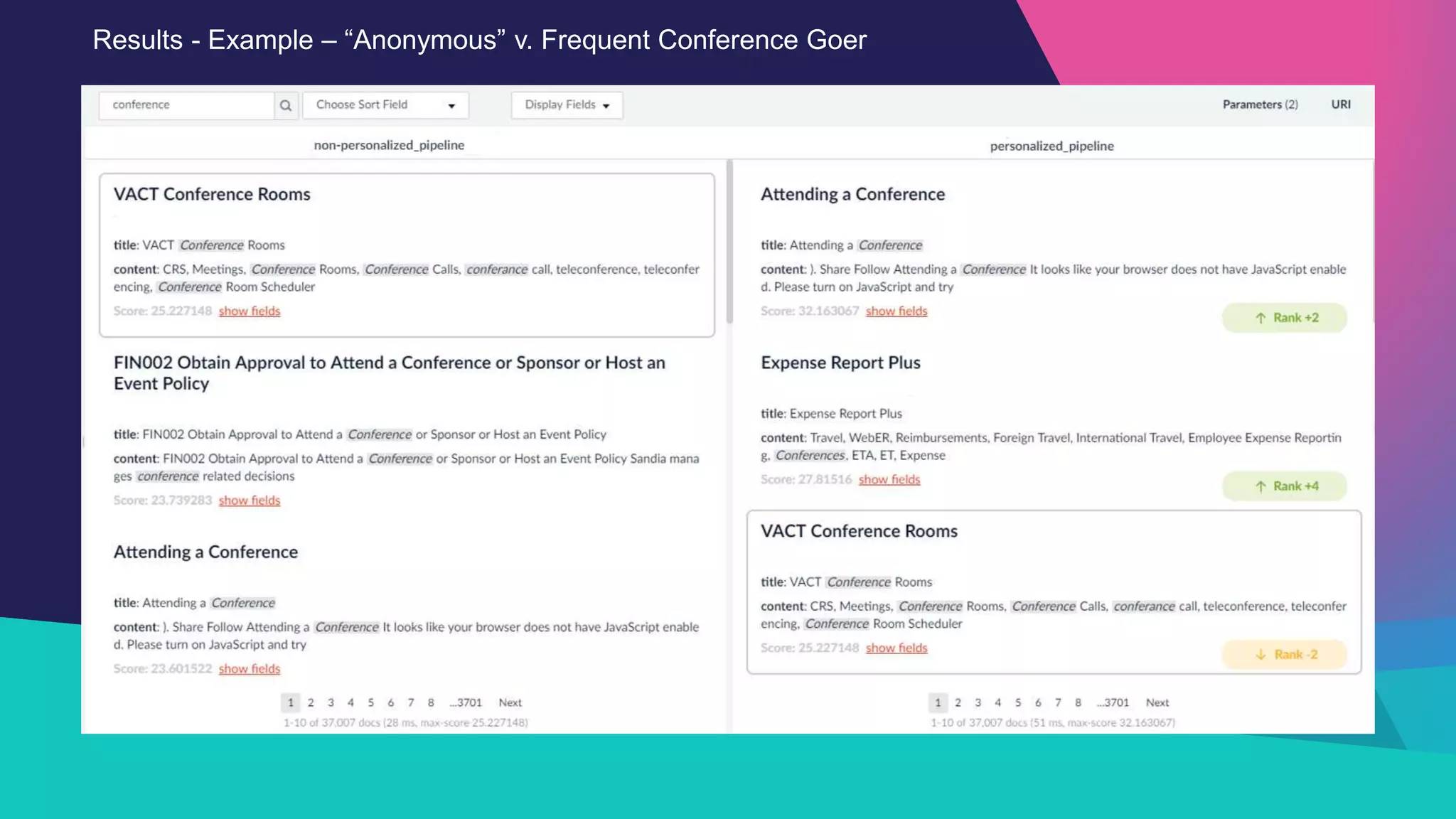
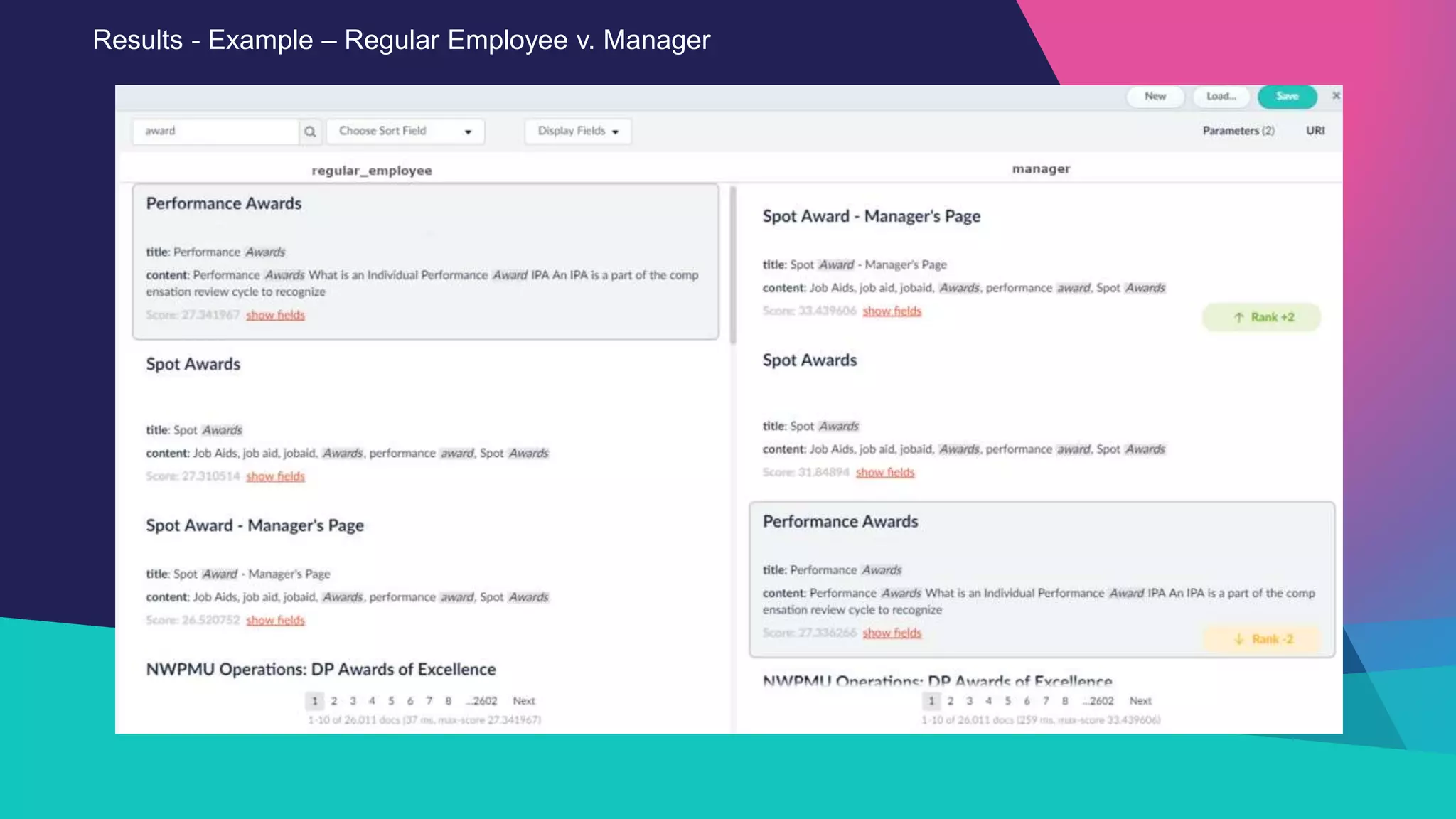





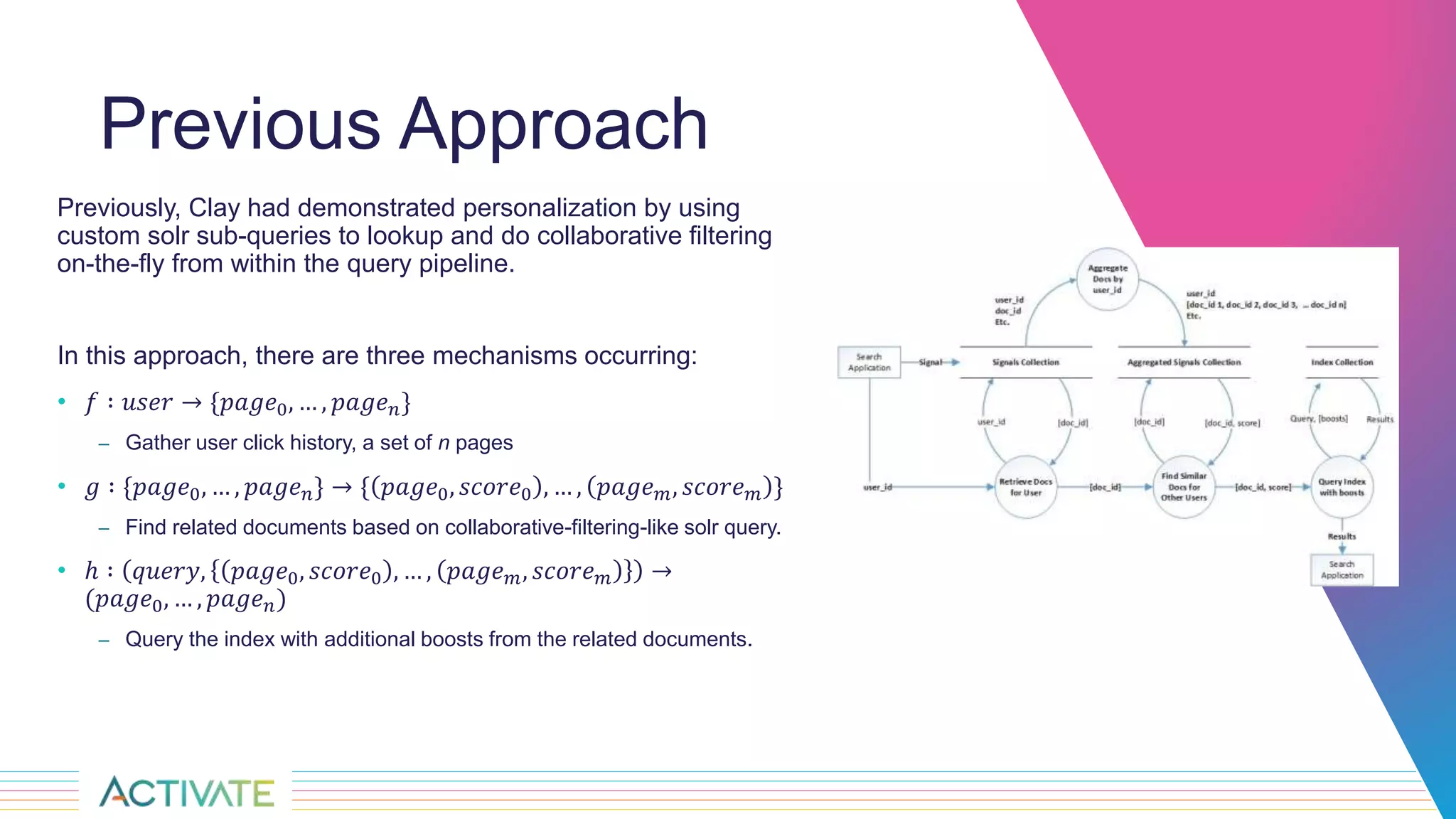


The Sandia National Laboratories presentation discusses the development of personalized search capabilities, which optimize results based on individual user click history and preferences. By implementing a data-driven approach within the Fusion platform, the team effectively configured personalized search algorithms, improving the relevance of results for users in an enterprise context. The results demonstrated significant improvements in personalization over standard search methods, thereby enhancing user experience.




















































![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)


































