Download to read offline




![8
void f(int in_1, float* in_2, …, float* out_n){
for( int i = 0, i < N; i++ ) {
for(int j … ) {
… statements …
for( int k … ) { … }
}
… statements …
int a[N][M] = { … };
float s = 0;
for( int j = 0; j < M; j++ ) {
… statements …
s += a[i][j] * … ;
}
}
}
OXiGen code example](https://image.slidesharecdn.com/oxigen5-190519154820/75/OXiGen-Automated-FPGA-design-flow-from-C-applications-to-dataflow-kernels-pitch-version-8-2048.jpg)



![14
Results
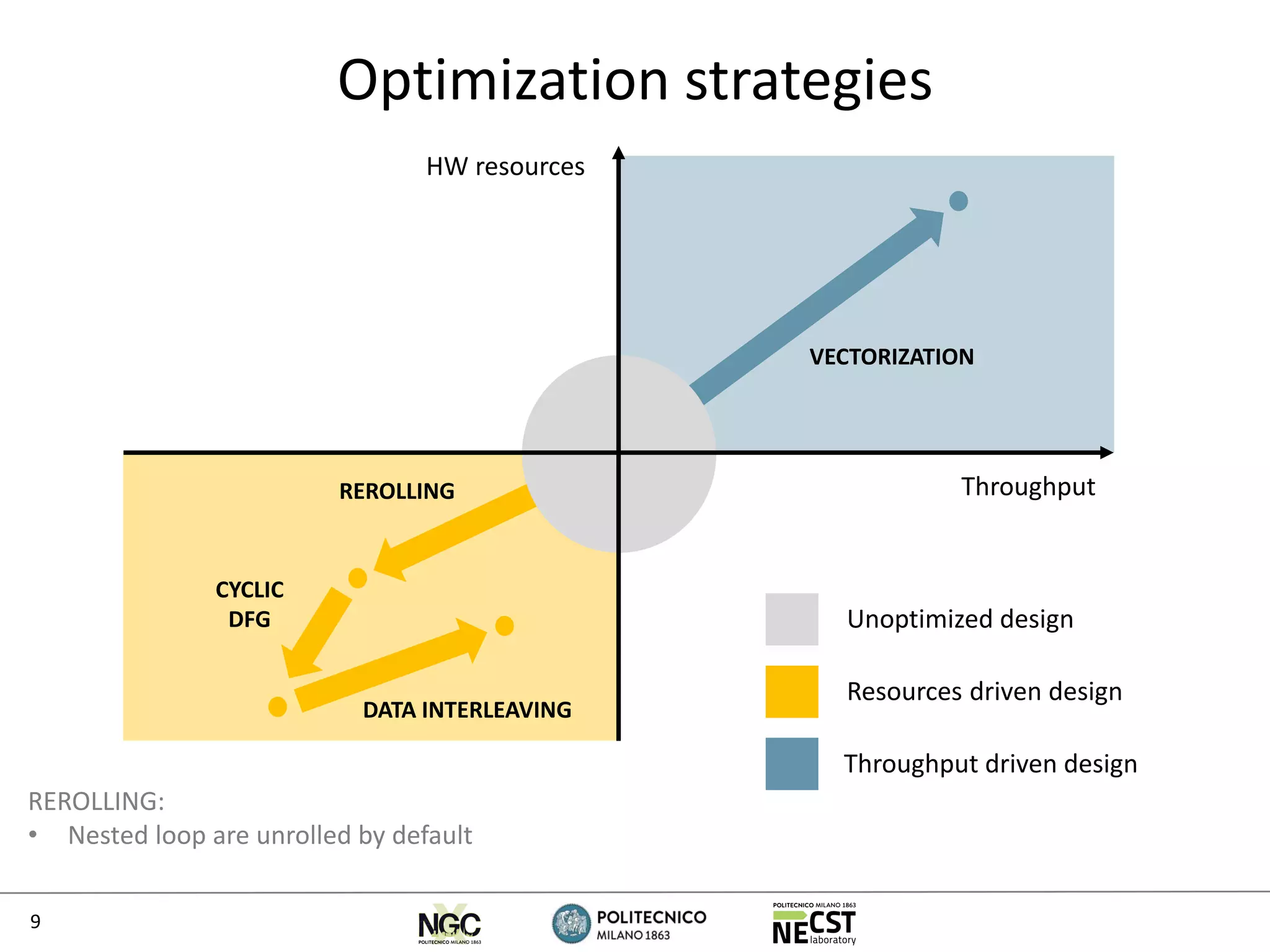
Algorithm Reroll.
factor
Cyclic
dataflow
Data
interl.
DSP
push
Pipel.
push
Freq. Speedup
w.r.t. SOA
Speedup
w.r.t. CPU
AOP 30 4 yes yes 0.1 0.3 210 1.34x w.r.t[1] 118.4x
AOP 30 4 yes yes 0.1 0.3 210 1.23x w.r.t.[2] 118.4x
AOP 780 98 yes yes 0.1 0.3 215 0.5x w.r.t.[2] 101.6x
VMC 128 yes yes 0.1 0.3 210 0.93x w.r.t.[3] 26x
The CPU baseline is a single-threaded implementation compiled with gcc 4.4.7 and –O3 optimization run on a Intel(R)
Core(TM) i7-6700 CPU @ 3.40GHz
[1] F. Peverelli, M. Rabozzi, E. Del Sozzo, and M. D. Santambrogio, “Oxigen: A tool for automatic acceleration of c
functions into dataflow fpga-based kernels,” in 2018 IEEE International Parallel and Distributed Processing Symposium
Workshops (IPDPSW). IEEE, 2018, pp. 91–98.
[2] A. M. Nestorov, E. Reggiani, H. Palikareva, P. Burovskiy, T. Becker, and M. D. Santambrogio, “A scalable dataflow
implementation of curran’s approximation algorithm,” in Parallel and Distributed Processing Symposium Workshops
(IPDPSW), 2017 IEEE International. IEEE, 2017, pp. 150–157..
[3] S. Cardamone, J. R. Kimmitt, H. G. Burton, and A. J. Thom, “Field programmable gate arrays and quantum monte
carlo: Power efficient co-processing for scalable high-performance computing,” arXiv preprintarXiv:1808.02402, 2018.](https://image.slidesharecdn.com/oxigen5-190519154820/75/OXiGen-Automated-FPGA-design-flow-from-C-applications-to-dataflow-kernels-pitch-version-14-2048.jpg)


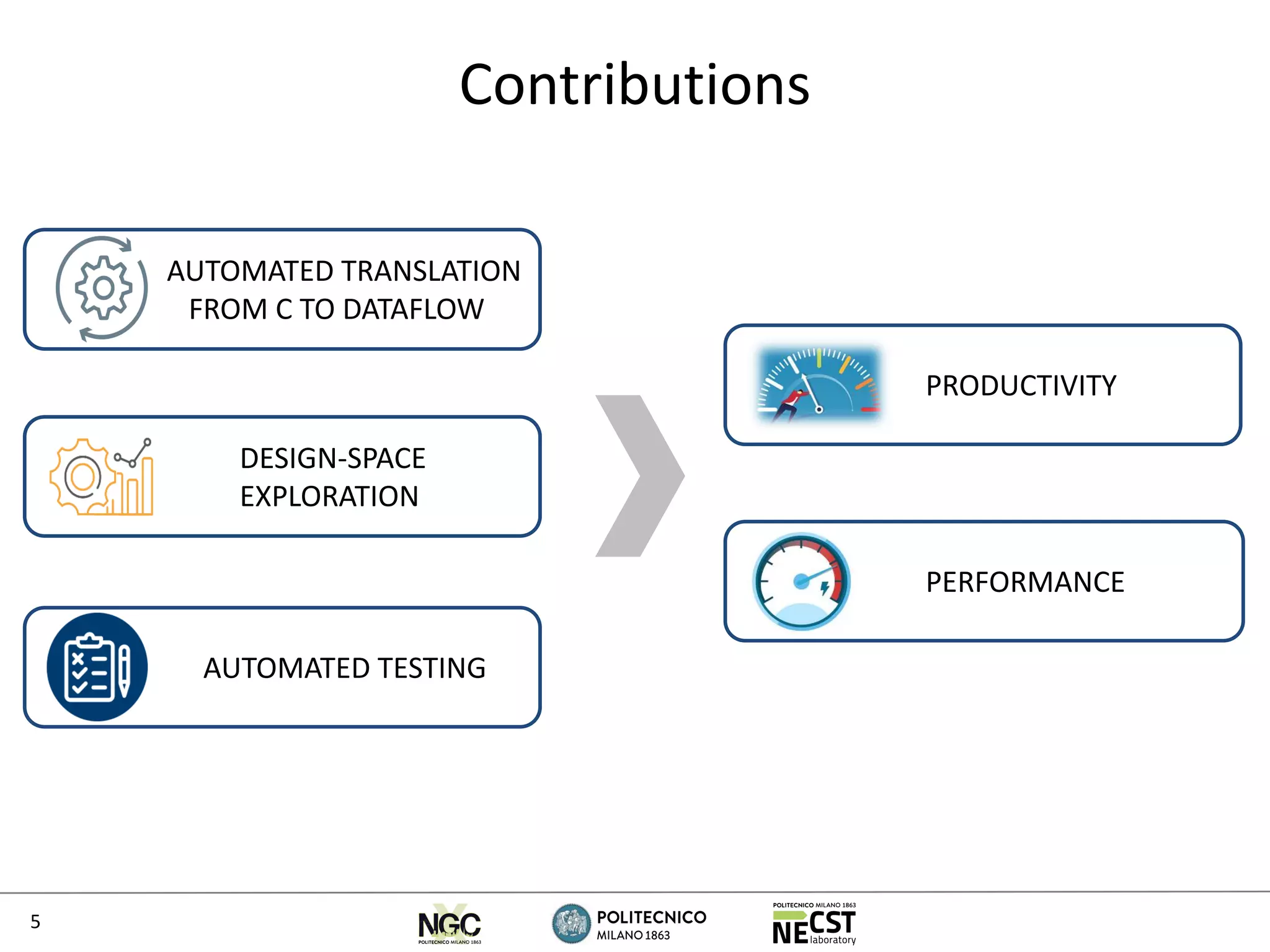
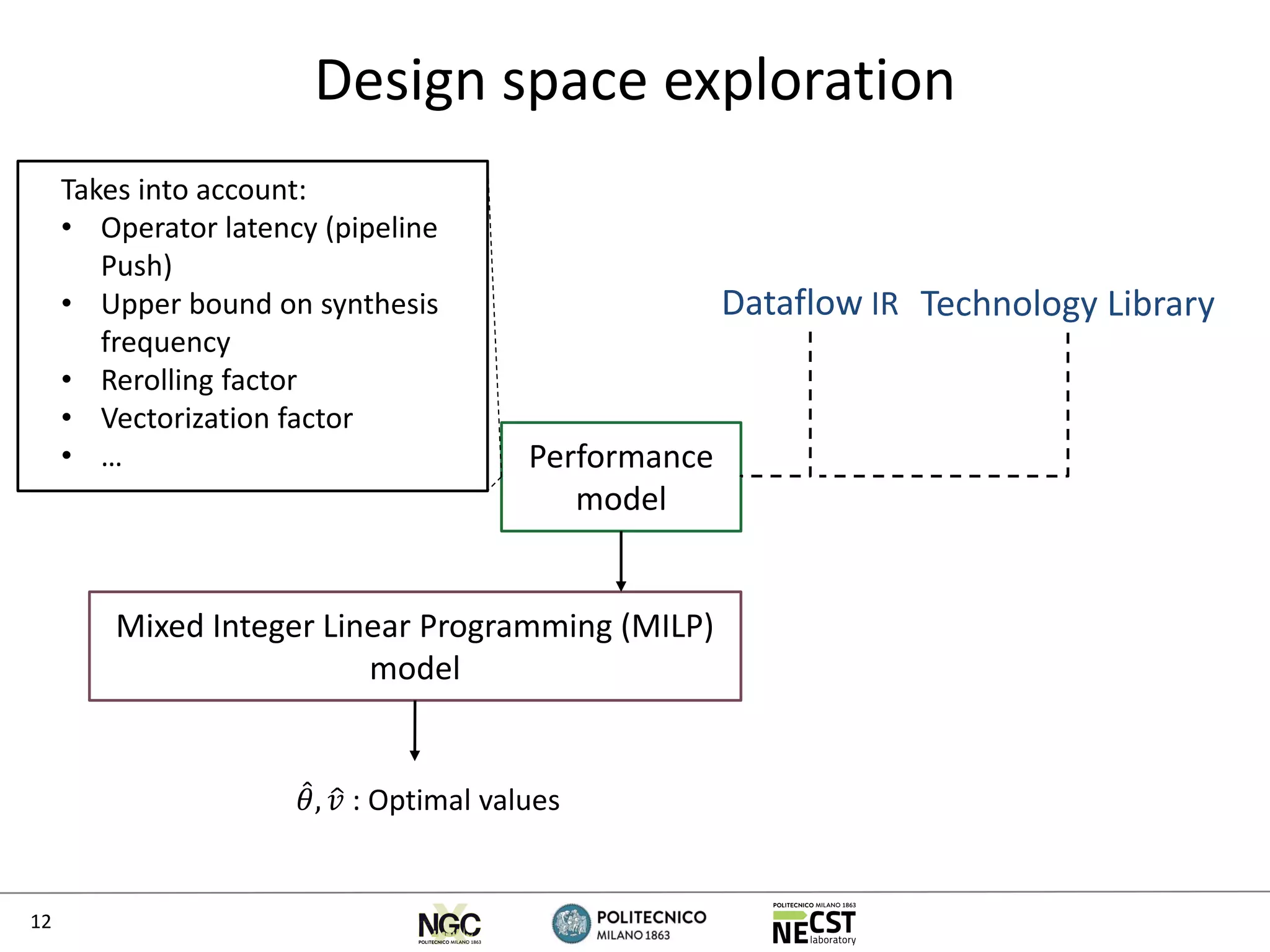
The document discusses the Oxigen tool, which automates the translation of C code into dataflow kernels for FPGA, enhancing design space exploration and performance testing. It outlines the architecture, optimization strategies, and experimental evaluations, demonstrating significant speedups compared to CPU implementations. Key contributions include improved productivity through automated processes and the integration of mixed integer linear programming models for resource and performance optimization.










![CETH for XDP [Linux Meetup Santa Clara | July 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/ceth5overview1-160801192921-thumbnail.jpg?width=640&height=640&fit=bounds)











































































