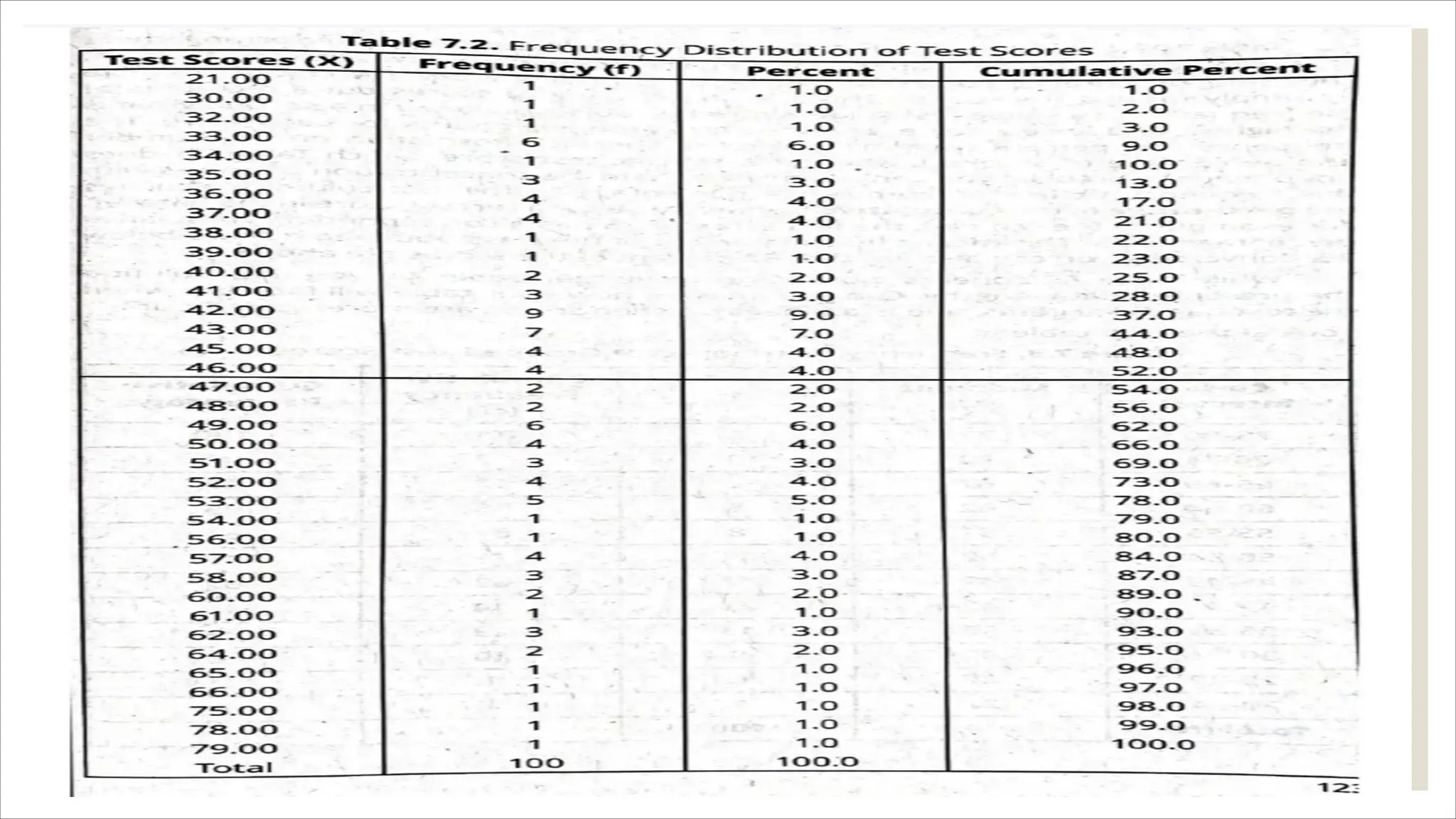
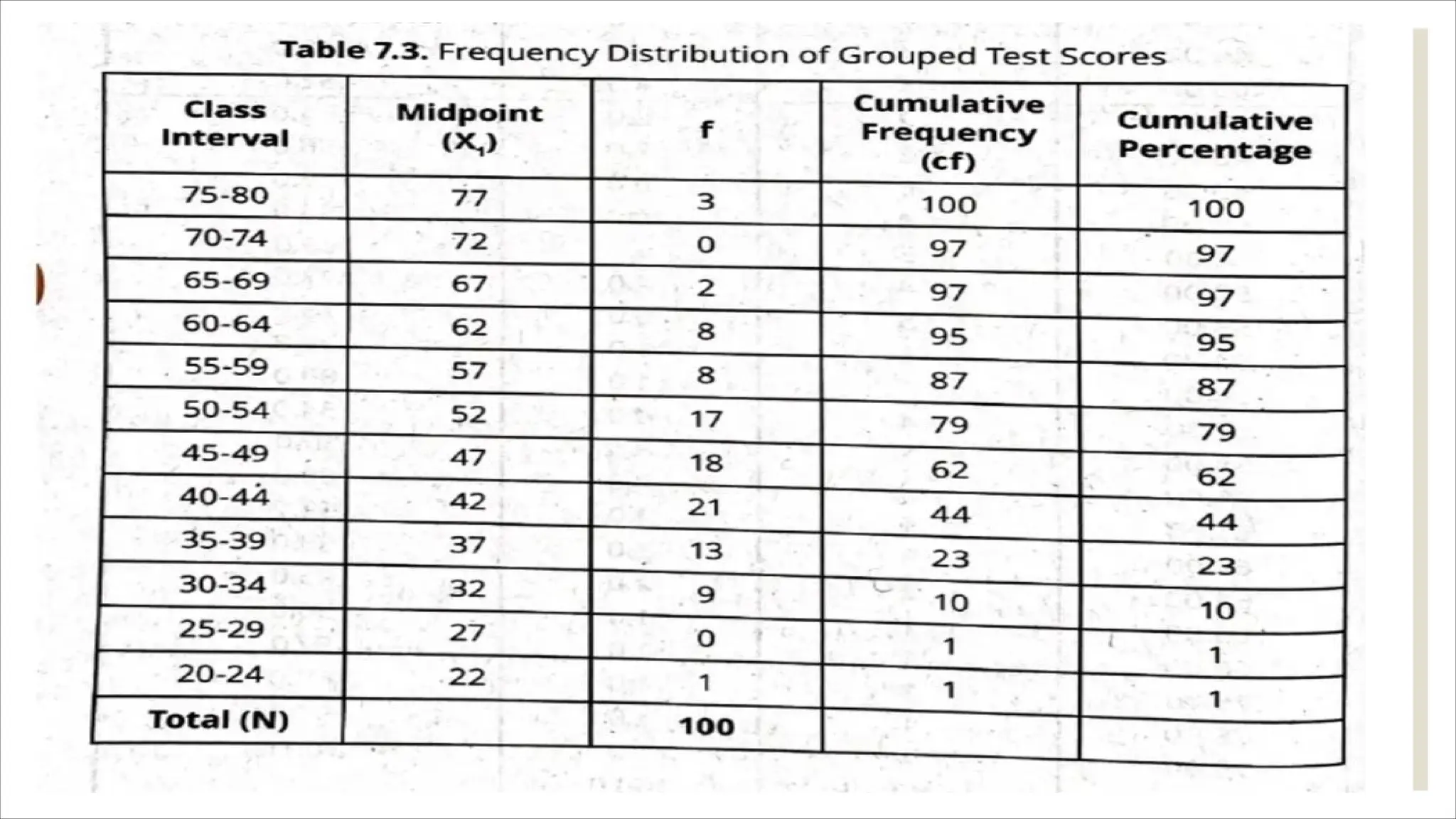
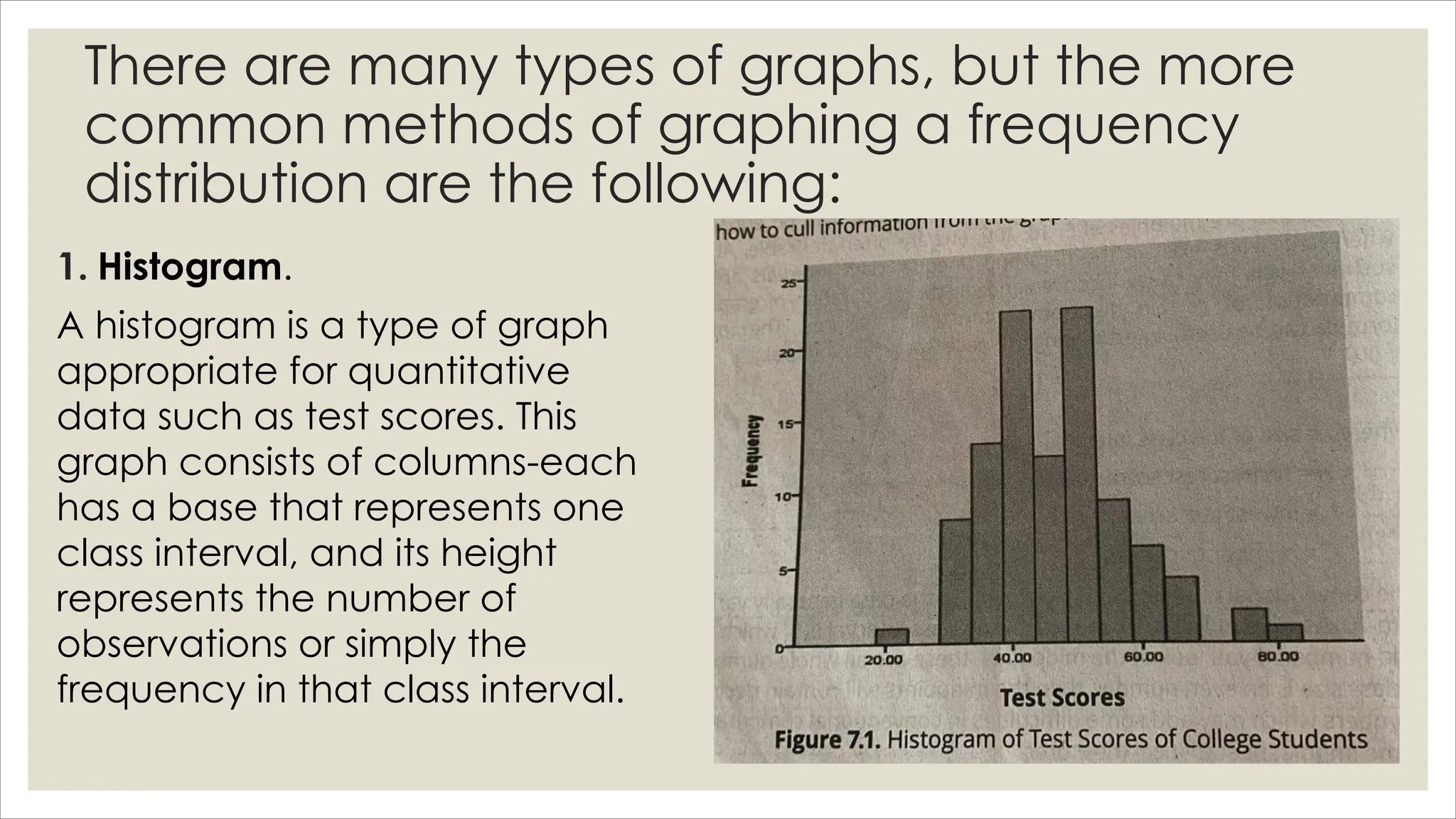
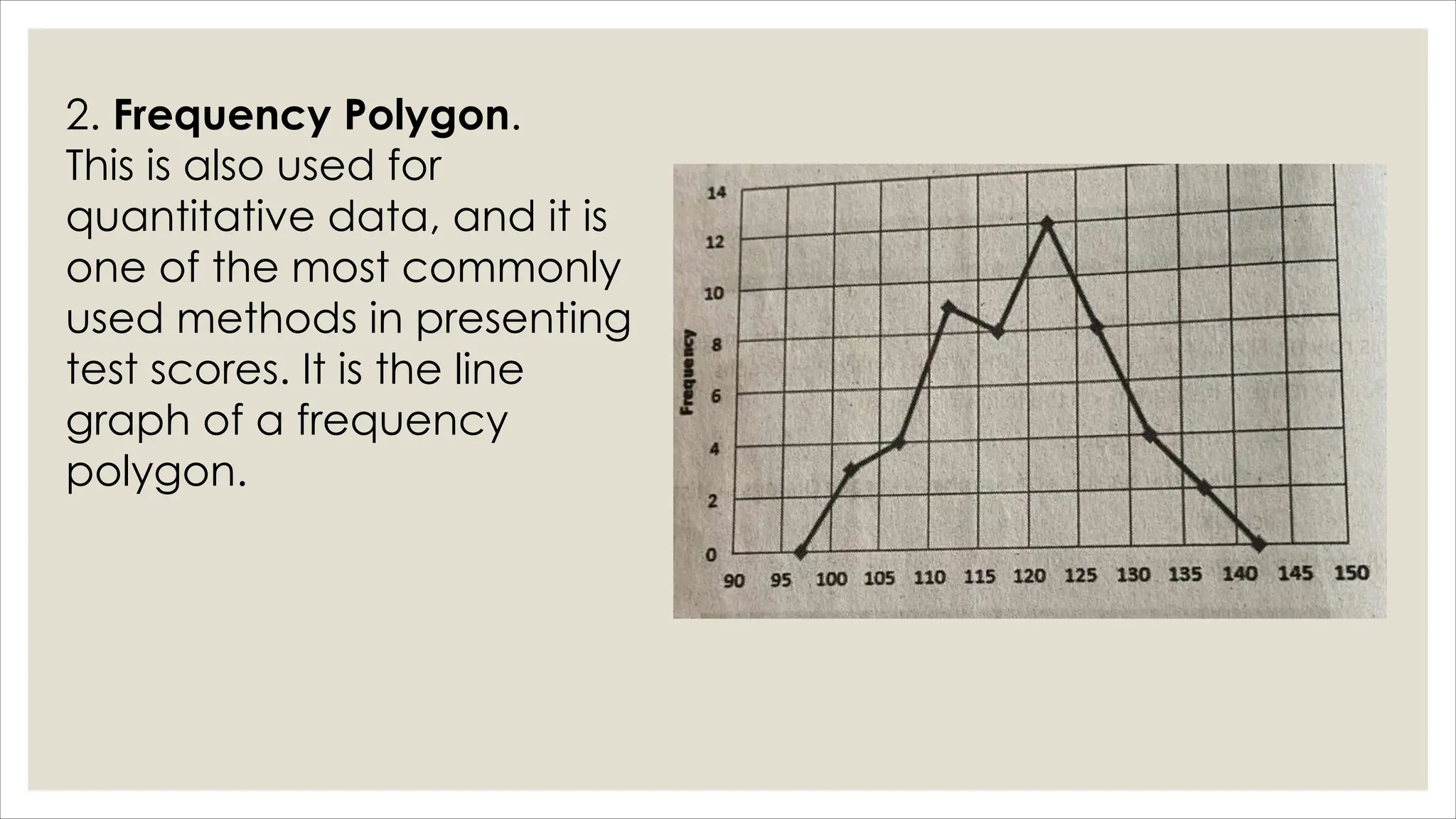
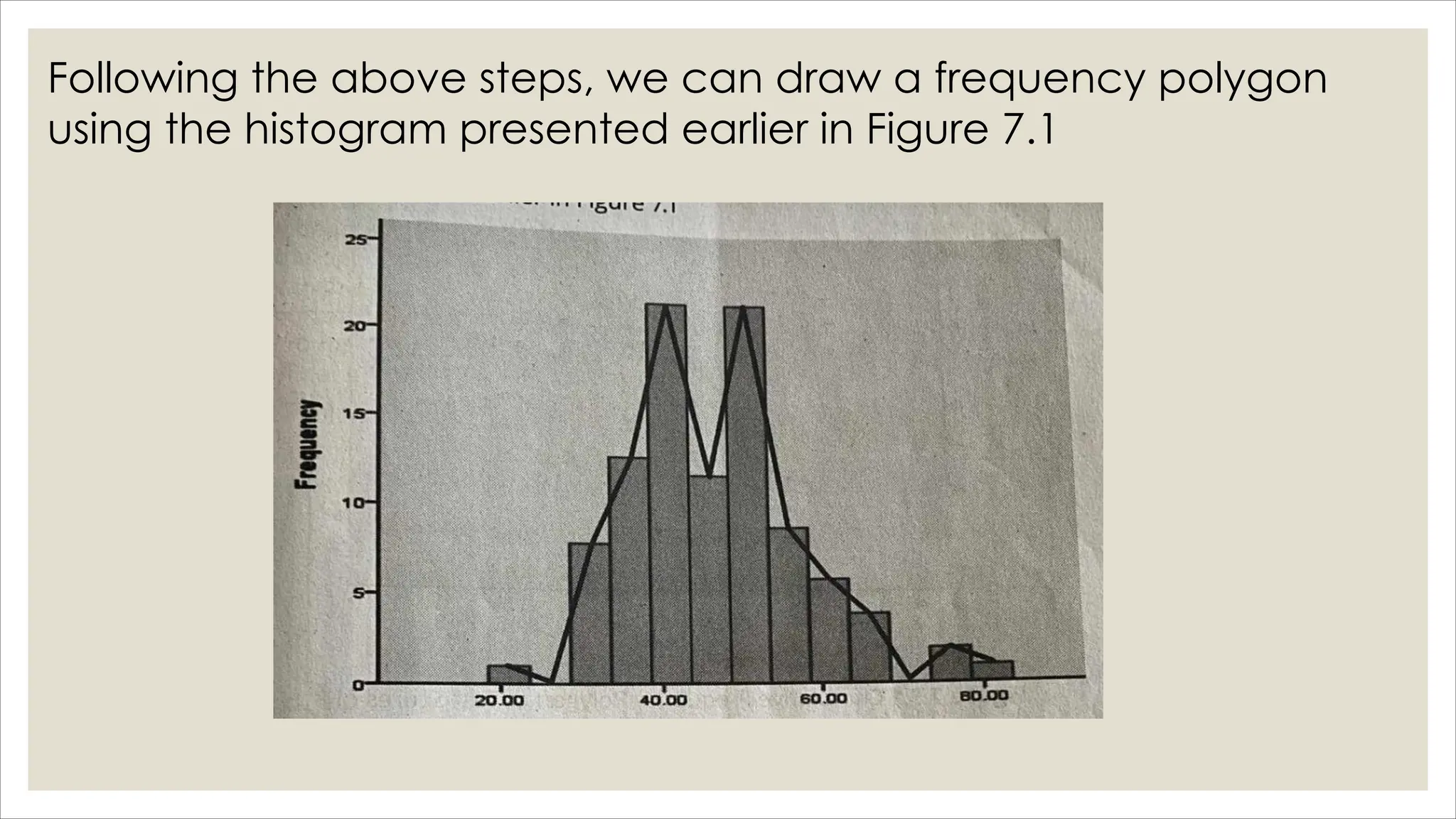
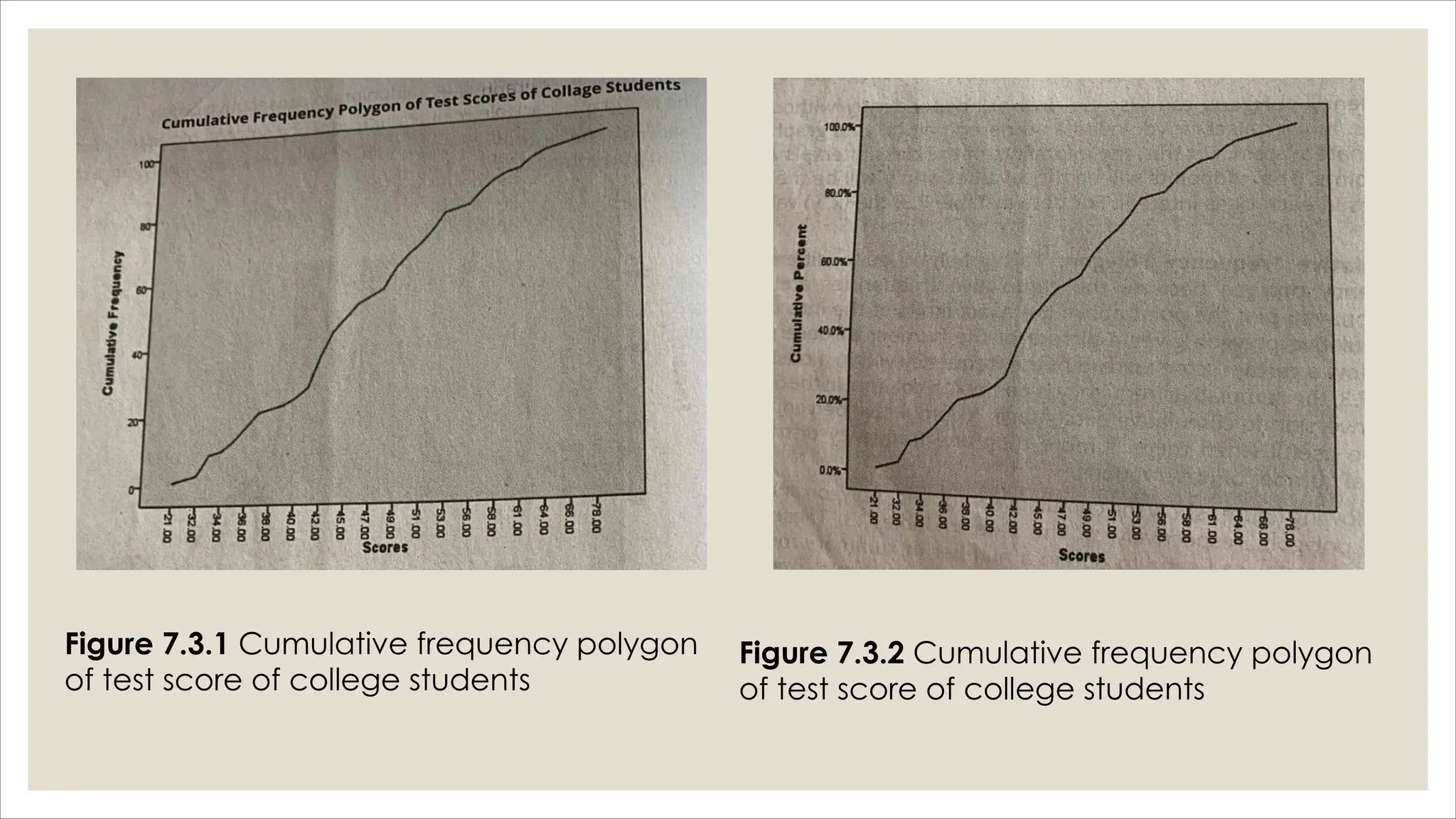
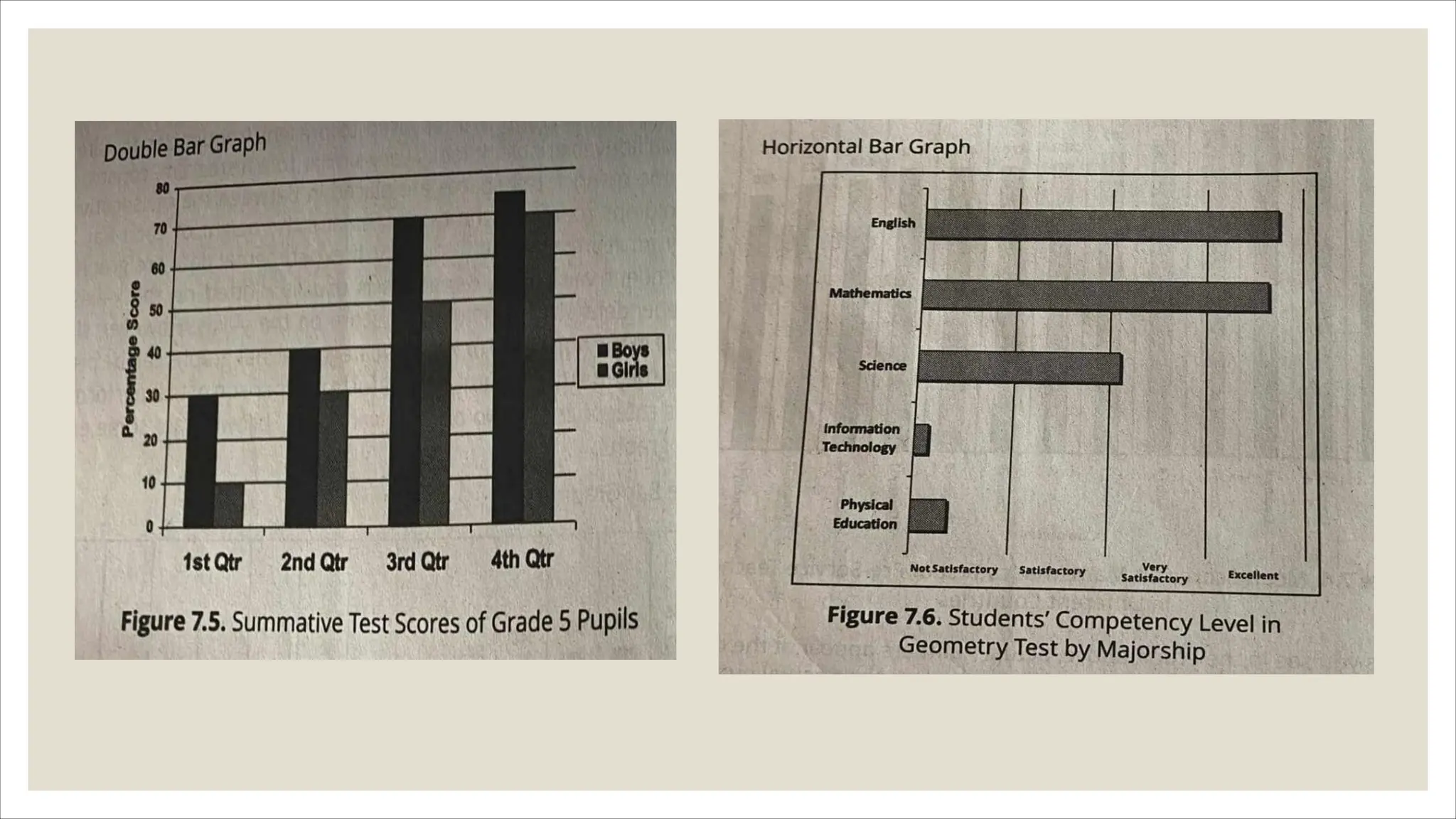
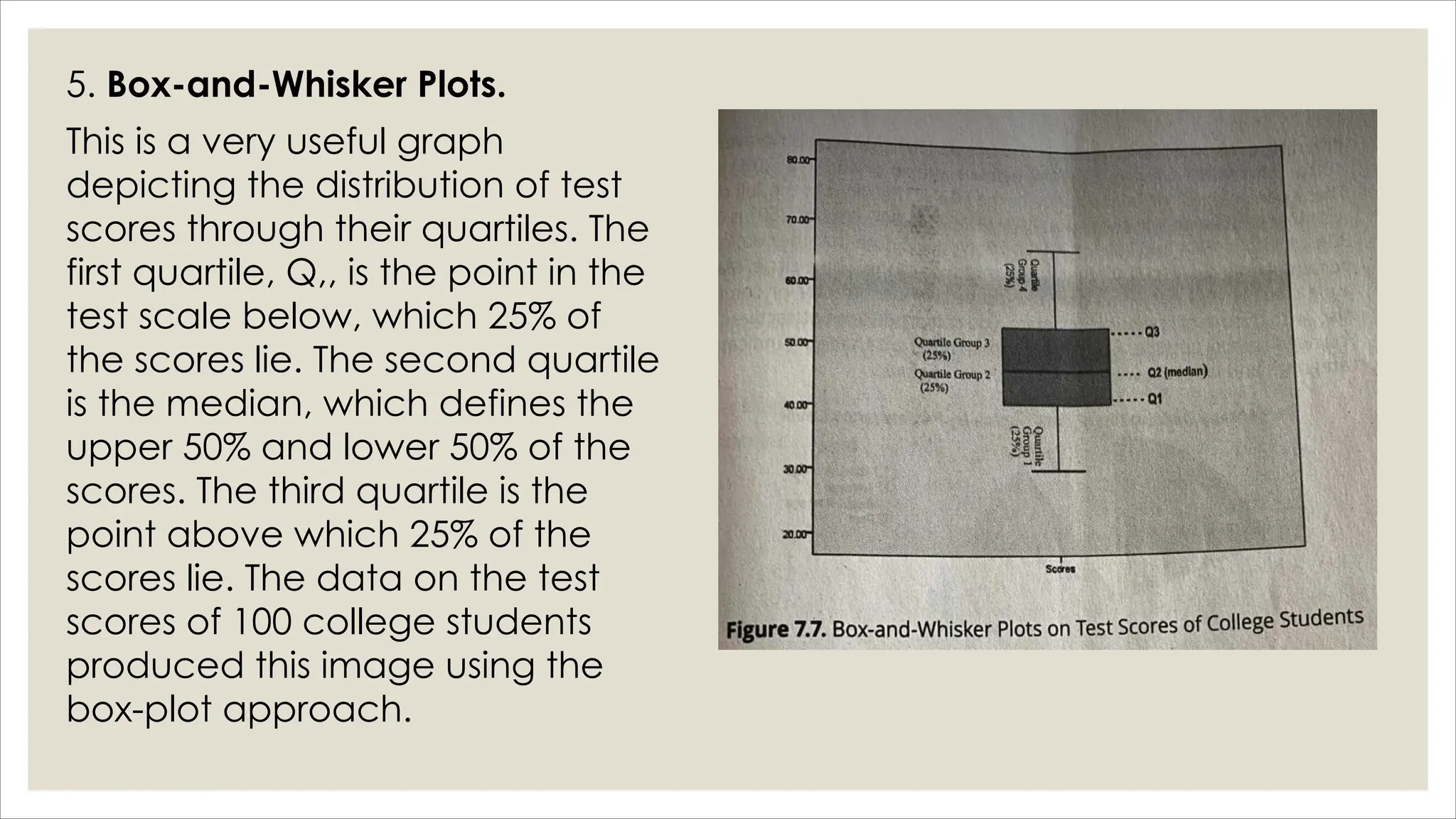
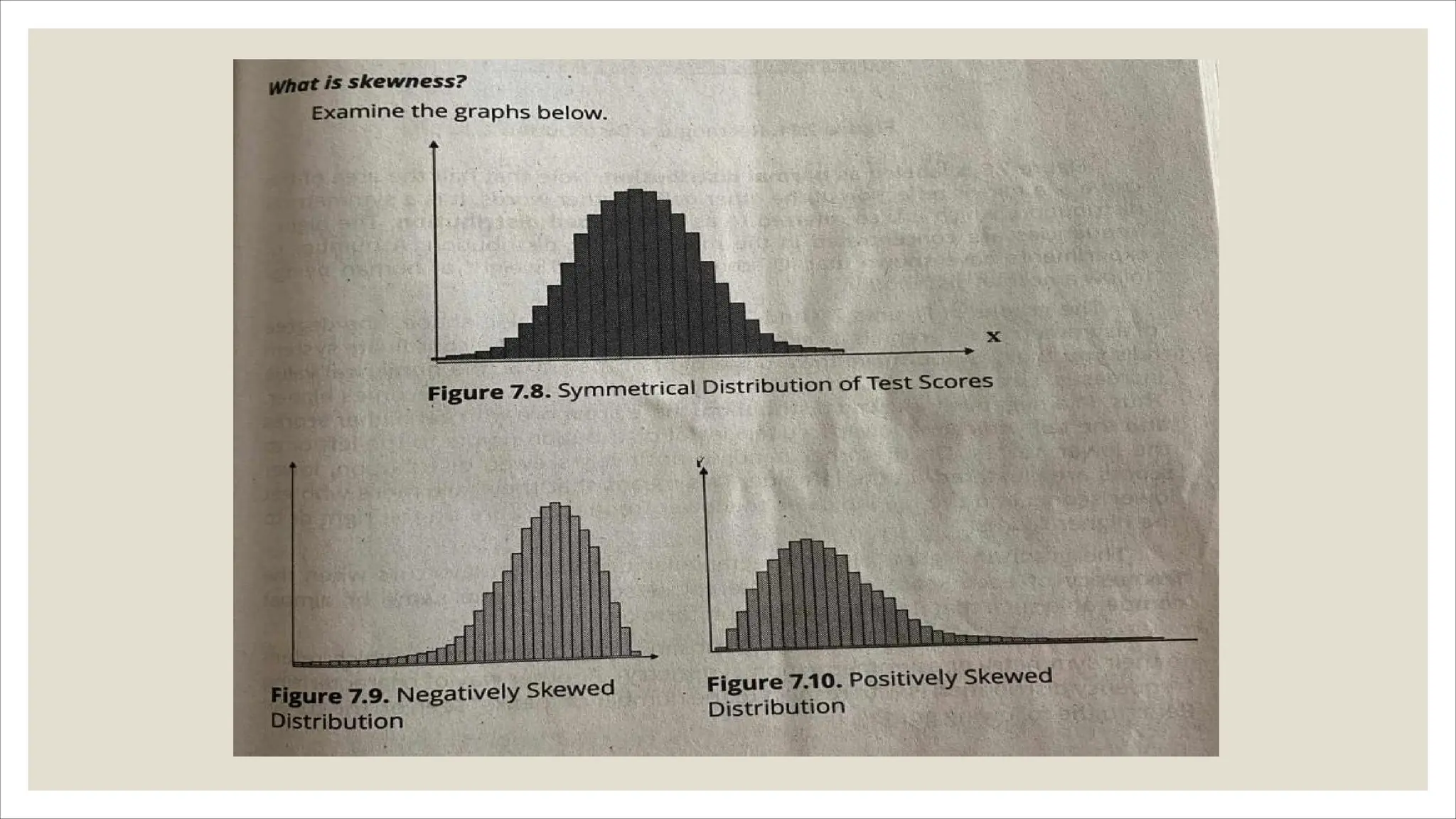
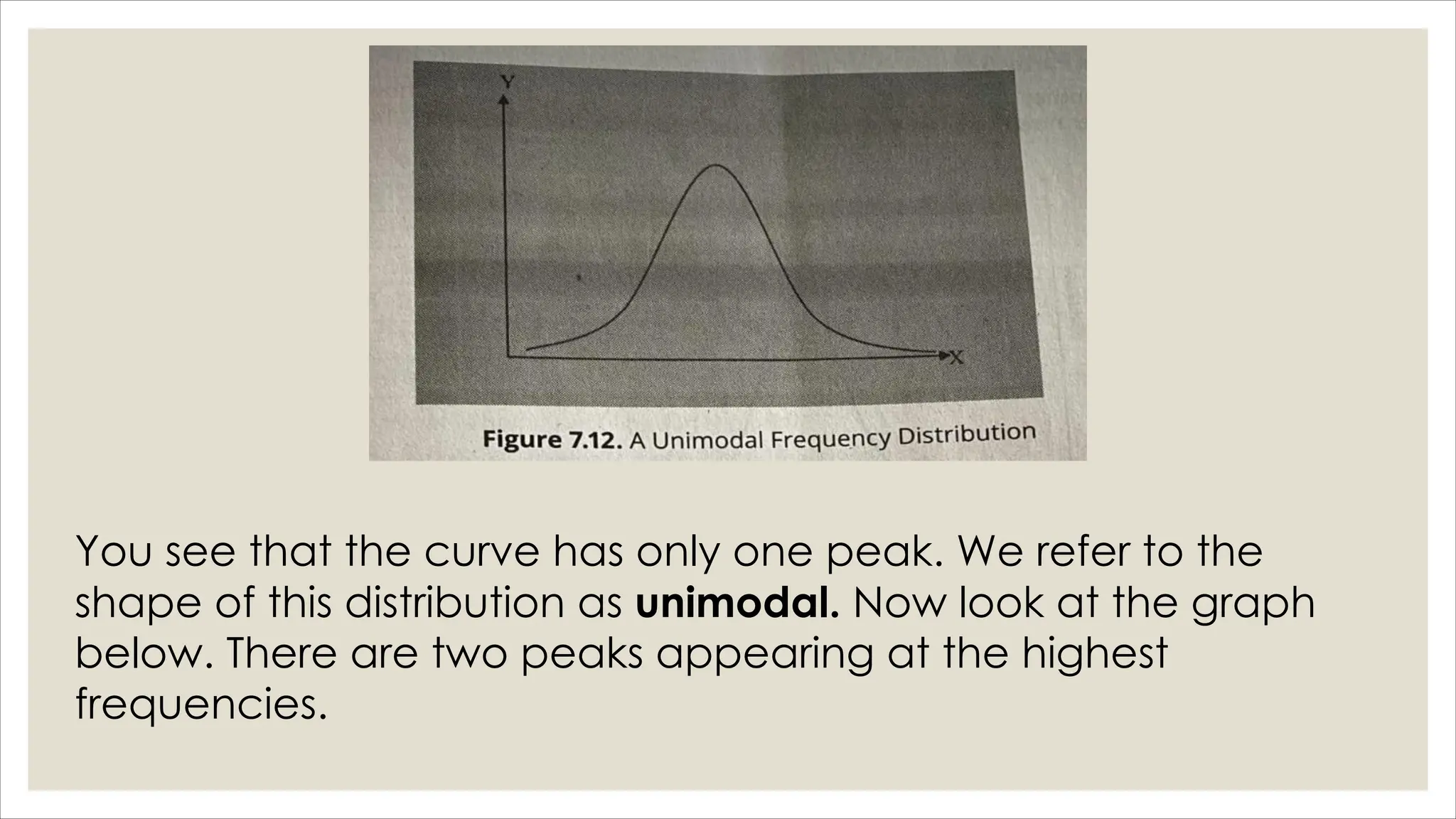
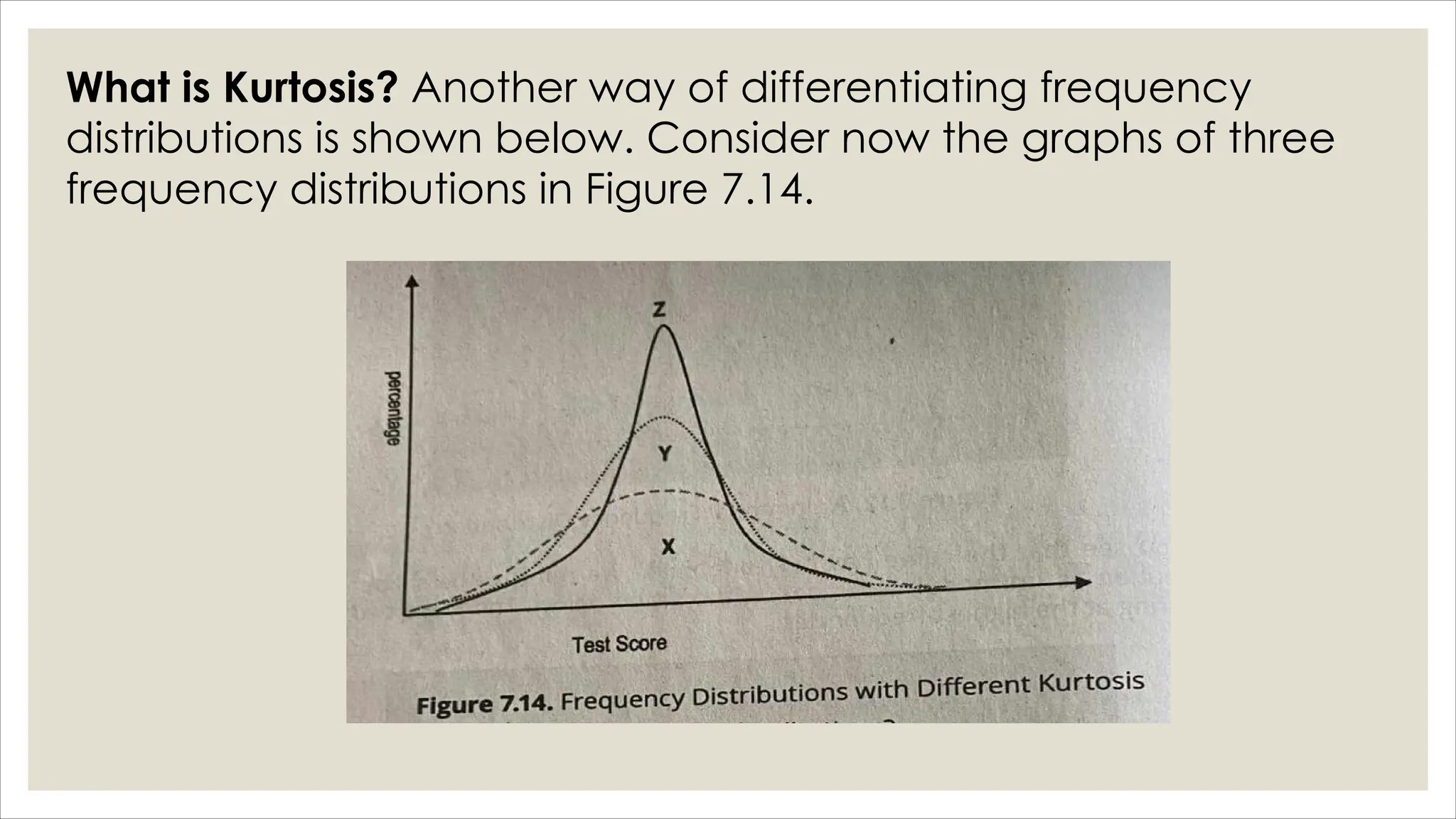
The document outlines how to organize and present test data using tables and graphs, emphasizing the importance of interpreting frequency distributions for effective communication of test results. It details different methods for graphing data, including histograms, frequency polygons, and box-and-whisker plots, while also providing conventions for constructing meaningful class intervals. Additionally, it discusses various distribution shapes, such as normal, skewed, and bimodal distributions, to highlight key characteristics in data analysis.